 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Perspectives Mean Better: Underwater Target Recognition and Localization with Multimodal Data via Symbiotic Transformer and Multiview Regression
Paper and Code
May 22, 2023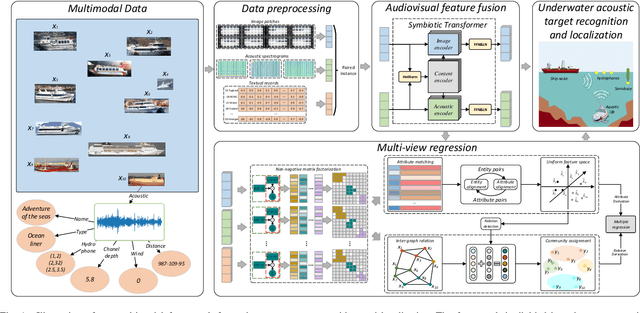

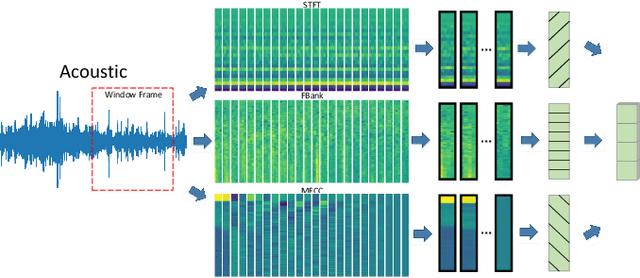
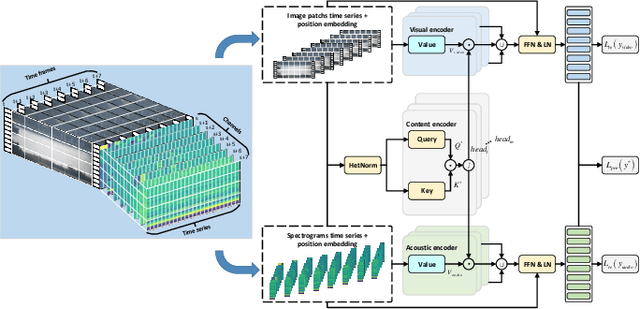
Underwater acoustic target recognition (UATR) and localization (UATL) play important roles in marine exploration. The highly noisy acoustic signal and time-frequency interference among various sources pose big challenges to this task. To tackle these issues, we propose a multimodal approach to extract and fuse audio-visual-textual information to recognize and localize underwater targets through the designed Symbiotic Transformer (Symb-Trans) and Multi-View Regression (MVR) method. The multimodal data were first preprocessed by a custom-designed HetNorm module to normalize the multi-source data in a common feature space. The Symb-Trans module embeds audiovisual features by co-training the preprocessed multimodal features through parallel branches and a content encoder with cross-attention. The audiovisual features are then used for underwater target recognition. Meanwhile, the text embedding combined with the audiovisual features is fed to an MVR module to predict the localization of the underwater targets through multi-view clustering and multiple regression. Since no off-the-shell multimodal dataset is available for UATR and UATL, we combined multiple public datasets, consisting of acoustic, and/or visual, and/or textural data, to obtain audio-visual-textual triplets for model training and validation. Experiments show that our model outperforms comparative methods in 91.7% (11 out of 12 metrics) and 100% (4 metrics) of the quantitative metrics for the recognition and localization tasks, respectively. In a case study, we demonstrate the advantages of multi-view models in establishing sample discriminability through visualization methods. For UATL, the proposed MVR method produces the relation graphs, which allow predictions based on records of underwater targets with similar conditions.