 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Reuse: A Multi-Scale Transformer Model for Structural Dynamic Segmentation in Symbolic Music Generation
Paper and Code
May 17, 2022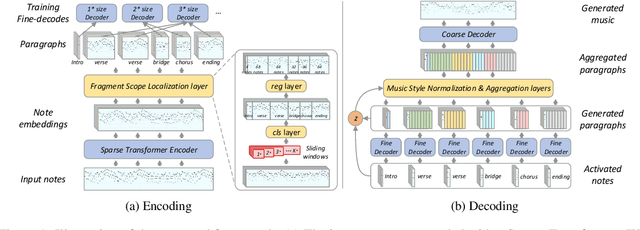
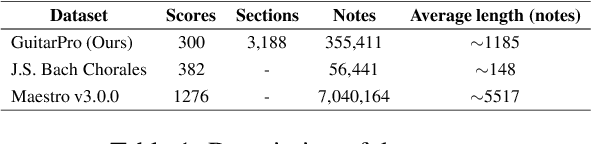
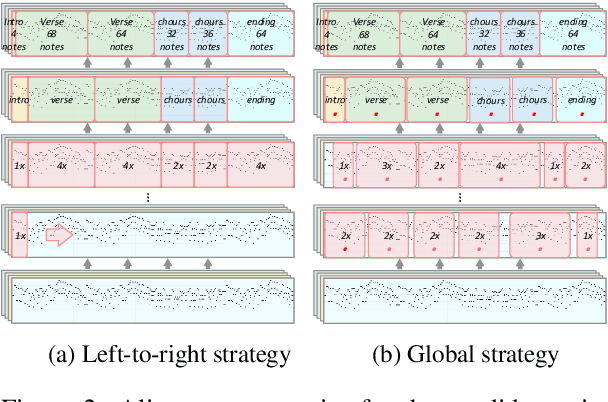
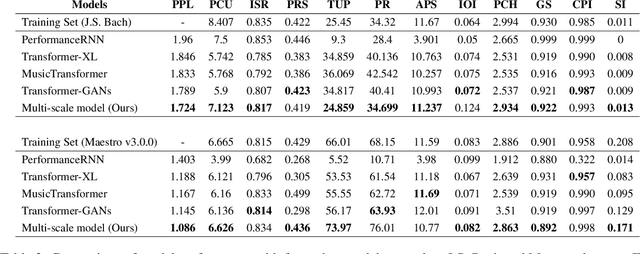
Symbolic Music Generation relies on the contextual representation capabilities of the generative model, where the most prevalent approach is the Transformer-based model. Not only that, the learning of long-term context is also related to the dynamic segmentation of musical structures, i.e. intro, verse and chorus, which is currently overlooked by the research community. In this paper, we propose a multi-scale Transformer, which uses coarse-decoder and fine-decoders to model the contexts at the global and section-level, respectively. Concretely, we designed a Fragment Scope Localization layer to syncopate the music into sections, which were later used to pre-train fine-decoders. After that, we designed a Music Style Normalization layer to transfer the style information from the original sections to the generated sections to achieve consistency in music style. The generated sections are combined in the aggregation layer and fine-tuned by the coarse decoder. Our model is evaluated on two open MIDI datasets, and experiments show that our model outperforms the best contemporary symbolic music generative models. More excitingly, visual evaluation shows that our model is superior in melody reuse, resulting in more realistic music.