 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior-Aware Dual-Channel Preference Learning for Heterogeneous Sequential Recommendation
Apr 16, 2026Heterogeneous sequential recommendation (HSR) aims to learn dynamic behavior dependencies from the diverse behaviors of user-item interactions to facilitate precise sequential recommendation. Despite many efforts yielding promising achievements, there are still challenges in modeling heterogeneous behavior data. One significant issue is the inherent sparsity of a real-world data, which can weaken the recommendation performance. Although auxiliary behaviors (e.g., clicks) partially address this problem, they inevitably introduce some noise, and the sparsity of the target behavior (e.g., purchases) remains unresolved. Additionally, contrastive learning-based augmentation in existing methods often focuses on a single behavior type, overlooking fine-grained user preferences and losing valuable information. To address these challenges, we have meticulously designed a behavior-aware dual-channel preference learning framework (BDPL). This framework begins with the construction of customized behavior-aware subgraphs to capture personalized behavior transition relationships, followed by a novel cascade-structured graph neural network to aggregate node context information. We then model and enhance user representations through a preference-level contrastive learning paradigm, considering both long-term and short-term preferences. Finally, we fuse the overall preference information using an adaptive gating mechanism to predict the next item the user will interact with under the target behavior. Extensive experiments on three real-world datasets demonstrate the superiority of our BDPL over the state-of-the-art models.
The Double-Edged Sword of Knowledge Transfer: Diagnosing and Curing Fairness Pathologies in Cross-Domain Recommendation
Jan 29, 2026Cross-domain recommendation (CDR) offers an effective strategy for improving recommendation quality in a target domain by leveraging auxiliary signals from source domains. Nonetheless, emerging evidence shows that CDR can inadvertently heighten group-level unfairness. In this work, we conduct a comprehensive theoretical and empirical analysis to uncover why these fairness issues arise. Specifically, we identify two key challenges: (i) Cross-Domain Disparity Transfer, wherein existing group-level disparities in the source domain are systematically propagated to the target domain; and (ii) Unfairness from Cross-Domain Information Gain, where the benefits derived from cross-domain knowledge are unevenly allocated among distinct groups. To address these two challenges, we propose a Cross-Domain Fairness Augmentation (CDFA) framework composed of two key components. Firstly, it mitigates cross-domain disparity transfer by adaptively integrating unlabeled data to equilibrate the informativeness of training signals across groups. Secondly, it redistributes cross-domain information gains via an information-theoretic approach to ensure equitable benefit allocation across groups. Extensive experiments on multiple datasets and baselines demonstrate that our framework significantly reduces unfairness in CDR without sacrificing overall recommendation performance, while even enhancing it.
Towards Multi-Behavior Multi-Task Recommendation via Behavior-informed Graph Embedding Learning
Jan 12, 2026Multi-behavior recommendation (MBR) aims to improve the performance w.r.t. the target behavior (i.e., purchase) by leveraging auxiliary behaviors (e.g., click, favourite). However, in real-world scenarios, a recommendation method often needs to process different types of behaviors and generate personalized lists for each task (i.e., each behavior type). Such a new recommendation problem is referred to as multi-behavior multi-task recommendation (MMR). So far, the most powerful MBR methods usually model multi-behavior interactions using a cascading graph paradigm. Although significant progress has been made in optimizing the performance of the target behavior, it often neglects the performance of auxiliary behaviors. To compensate for the deficiencies of the cascading paradigm, we propose a novel solution for MMR, i.e., behavior-informed graph embedding learning (BiGEL). Specifically, we first obtain a set of behavior-aware embeddings by using a cascading graph paradigm. Subsequently, we introduce three key modules to improve the performance of the model. The cascading gated feedback (CGF) module enables a feedback-driven optimization process by integrating feedback from the target behavior to refine the auxiliary behaviors preferences. The global context enhancement (GCE) module integrates the global context to maintain the user's overall preferences, preventing the loss of key preferences due to individual behavior graph modeling. Finally, the contrastive preference alignment (CPA) module addresses the potential changes in user preferences during the cascading process by aligning the preferences of the target behaviors with the global preferences through contrastive learning. Extensive experiments on two real-world datasets demonstrate the effectiveness of our BiGEL compared with ten very competitive methods.
Leave No One Behind: Fairness-Aware Cross-Domain Recommender Systems for Non-Overlapping Users
Jul 23, 2025Cross-domain recommendation (CDR) methods predominantly leverage overlapping users to transfer knowledge from a source domain to a target domain. However, through empirical studies, we uncover a critical bias inherent in these approaches: while overlapping users experience significant enhancements in recommendation quality, non-overlapping users benefit minimally and even face performance degradation. This unfairness may erode user trust, and, consequently, negatively impact business engagement and revenue. To address this issue, we propose a novel solution that generates virtual source-domain users for non-overlapping target-domain users. Our method utilizes a dual attention mechanism to discern similarities between overlapping and non-overlapping users, thereby synthesizing realistic virtual user embeddings. We further introduce a limiter component that ensures the generated virtual users align with real-data distributions while preserving each user's unique characteristics. Notably, our method is model-agnostic and can be seamlessly integrated into any CDR model. Comprehensive experiments conducted on three public datasets with five CDR baselines demonstrate that our method effectively mitigates the CDR non-overlapping user bias, without loss of overall accuracy. Our code is publicly available at https://github.com/WeixinChen98/VUG.
A Survey on Sequential Recommendation
Dec 17, 2024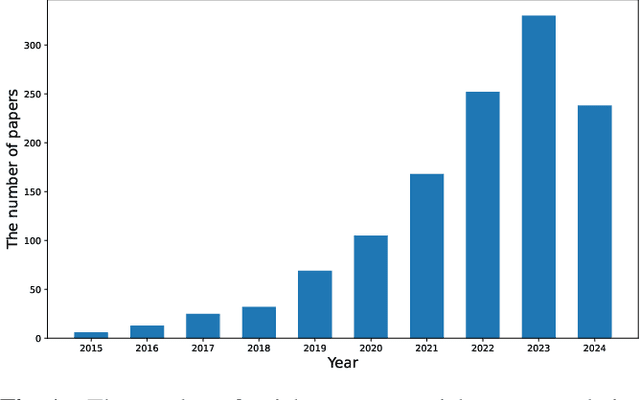
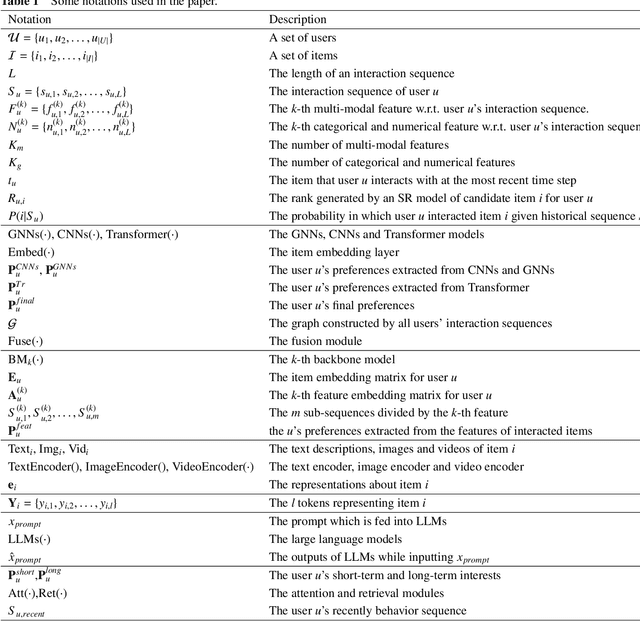
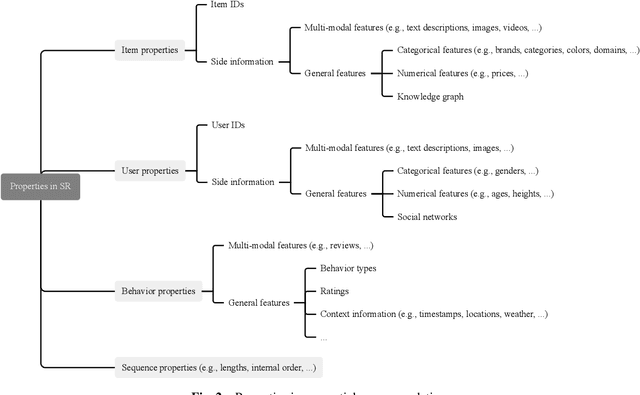
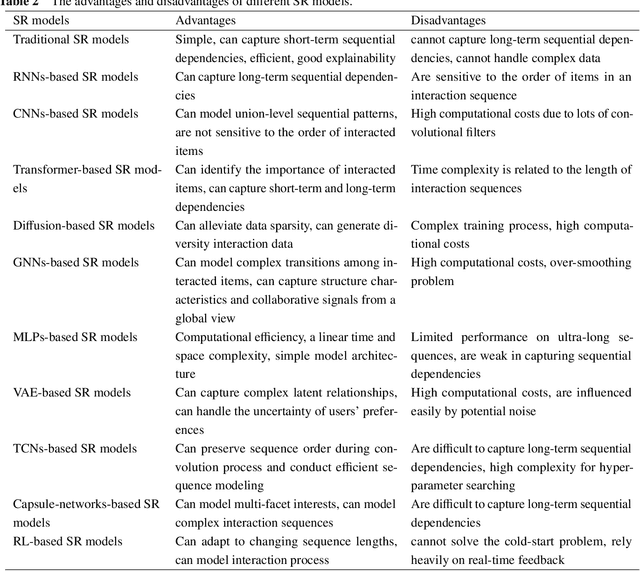
Different from most conventional recommendation problems, sequential recommendation focuses on learning users' preferences by exploiting the internal order and dependency among the interacted items, which has received significant attention from both researchers and practitioners. In recent years, we have witnessed great progress and achievements in this field, necessitating a new survey. In this survey, we study the SR problem from a new perspective (i.e., the construction of an item's properties), and summarize the most recent techniques used in sequential recommendation such as pure ID-based SR, SR with side information, multi-modal SR, generative SR, LLM-powered SR, ultra-long SR and data-augmented SR. Moreover, we introduce some frontier research topics in sequential recommendation, e.g., open-domain SR, data-centric SR, could-edge collaborative SR, continuous SR, SR for good, and explainable SR. We believe that our survey could be served as a valuable roadmap for readers in this field.
Lossless and Privacy-Preserving Graph Convolution Network for Federated Item Recommendation
Dec 02, 2024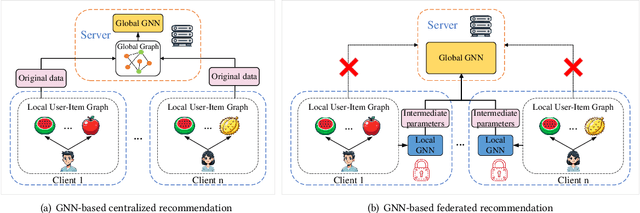


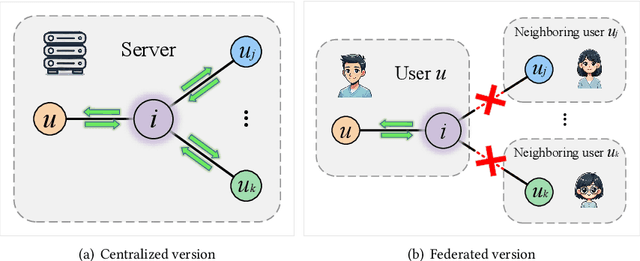
Graph neural network (GNN) has emerged as a state-of-the-art solution for item recommendation. However, existing GNN-based recommendation methods rely on a centralized storage of fragmented user-item interaction sub-graphs and training on an aggregated global graph, which will lead to privacy concerns. As a response, some recent works develop GNN-based federated recommendation methods by exploiting decentralized and fragmented user-item sub-graphs in order to preserve user privacy. However, due to privacy constraints, the graph convolution process in existing federated recommendation methods is incomplete compared with the centralized counterpart, causing a degradation of the recommendation performance. In this paper, we propose a novel lossless and privacy-preserving graph convolution network (LP-GCN), which fully completes the graph convolution process with decentralized user-item interaction sub-graphs while ensuring privacy. It is worth mentioning that its performance is equivalent to that of the non-federated (i.e., centralized) counterpart. Moreover, we validate its effectiveness through both theoretical analysis and empirical studies. Extensive experiments on three real-world datasets show that our LP-GCN outperforms the existing federated recommendation methods. The code will be publicly available once the paper is accepted.
Federated Graph Learning for Cross-Domain Recommendation
Oct 10, 2024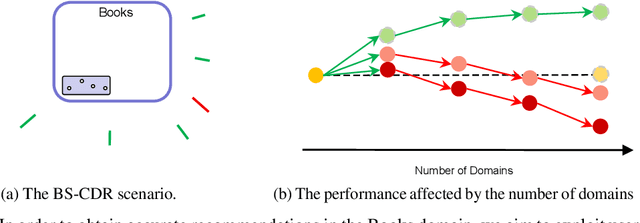
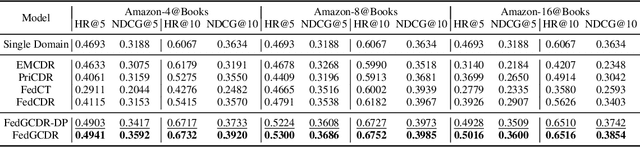
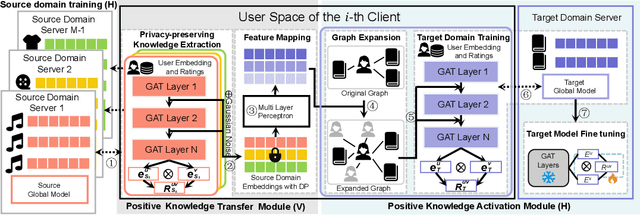
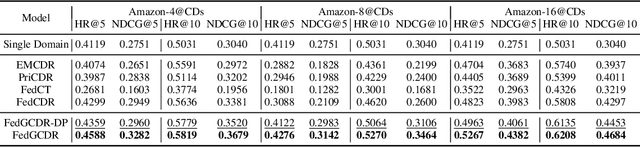
Cross-domain recommendation (CDR) offers a promising solution to the data sparsity problem by enabling knowledge transfer across source and target domains. However, many recent CDR models overlook crucial issues such as privacy as well as the risk of negative transfer (which negatively impact model performance), especially in multi-domain settings. To address these challenges, we propose FedGCDR, a novel federated graph learning framework that securely and effectively leverages positive knowledge from multiple source domains. First, we design a positive knowledge transfer module that ensures privacy during inter-domain knowledge transmission. This module employs differential privacy-based knowledge extraction combined with a feature mapping mechanism, transforming source domain embeddings from federated graph attention networks into reliable domain knowledge. Second, we design a knowledge activation module to filter out potential harmful or conflicting knowledge from source domains, addressing the issues of negative transfer. This module enhances target domain training by expanding the graph of the target domain to generate reliable domain attentions and fine-tunes the target model for improved negative knowledge filtering and more accurate predictions. We conduct extensive experiments on 16 popular domains of the Amazon dataset, demonstrating that FedGCDR significantly outperforms state-of-the-art methods.
Sample Enrichment via Temporary Operations on Subsequences for Sequential Recommendation
Jul 25, 2024



Sequential recommendation leverages interaction sequences to predict forthcoming user behaviors, crucial for crafting personalized recommendations. However, the true preferences of a user are inherently complex and high-dimensional, while the observed data is merely a simplified and low-dimensional projection of the rich preferences, which often leads to prevalent issues like data sparsity and inaccurate model training. To learn true preferences from the sparse data, most existing works endeavor to introduce some extra information or design some ingenious models. Although they have shown to be effective, extra information usually increases the cost of data collection, and complex models may result in difficulty in deployment. Innovatively, we avoid the use of extra information or alterations to the model; instead, we fill the transformation space between the observed data and the underlying preferences with randomness. Specifically, we propose a novel model-agnostic and highly generic framework for sequential recommendation called sample enrichment via temporary operations on subsequences (SETO), which temporarily and separately enriches the transformation space via sequence enhancement operations with rationality constraints in training. The transformation space not only exists in the process from input samples to preferences but also in preferences to target samples. We highlight our SETO's effectiveness and versatility over multiple representative and state-of-the-art sequential recommendation models (including six single-domain sequential models and two cross-domain sequential models) across multiple real-world datasets (including three single-domain datasets, three cross-domain datasets and a large-scale industry dataset).
Delving into Differentially Private Transformer
May 29, 2024



Deep learning with differential privacy (DP) has garnered significant attention over the past years, leading to the development of numerous methods aimed at enhancing model accuracy and training efficiency. This paper delves into the problem of training Transformer models with differential privacy. Our treatment is modular: the logic is to `reduce' the problem of training DP Transformer to the more basic problem of training DP vanilla neural nets. The latter is better understood and amenable to many model-agnostic methods. Such `reduction' is done by first identifying the hardness unique to DP Transformer training: the attention distraction phenomenon and a lack of compatibility with existing techniques for efficient gradient clipping. To deal with these two issues, we propose the Re-Attention Mechanism and Phantom Clipping, respectively. We believe that our work not only casts new light on training DP Transformers but also promotes a modular treatment to advance research in the field of differentially private deep learning.
BMLP: Behavior-aware MLP for Heterogeneous Sequential Recommendation
Feb 20, 2024In real recommendation scenarios, users often have different types of behaviors, such as clicking and buying. Existing research methods show that it is possible to capture the heterogeneous interests of users through different types of behaviors. However, most multi-behavior approaches have limitations in learning the relationship between different behaviors. In this paper, we propose a novel multilayer perceptron (MLP)-based heterogeneous sequential recommendation method, namely behavior-aware multilayer perceptron (BMLP). Specifically, it has two main modules, including a heterogeneous interest perception (HIP) module, which models behaviors at multiple granularities through behavior types and transition relationships, and a purchase intent perception (PIP) module, which adaptively fuses subsequences of auxiliary behaviors to capture users' purchase intent. Compared with mainstream sequence models, MLP is competitive in terms of accuracy and has unique advantages in simplicity and efficiency. Extensive experiments show that BMLP achieves significant improvement over state-of-the-art algorithms on four public datasets. In addition, its pure MLP architecture leads to a linear time complexity.