 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSUGA: LLM-Enhanced Recommendation with Hierarchical Semantic Understanding and Group-Aware Alignment
May 12, 2026Large language model (LLM)-enhanced sequential recommendation typically aims to improve two core components: user semantic embedding extraction and utilization. Despite promising results, existing methods still have two limitations: 1) In the extraction stage, most methods directly input long interaction sequence fragments into LLM for preference summarization. However, excessively long sequences increase inference difficulty, making it challenging to reliably infer accurate user embeddings. 2) In the utilization stage, most methods employ the same semantic embedding utilization strategy for all users, neglecting the differences caused by user activity levels, leading to suboptimal performance. To address these issues, we propose HSUGA, which introduces a simple yet effective plugin for each of the two core components: Hierarchical Semantic Understanding (HSU) and Group-Aware Alignment (GAA). HSU performs a staged two-phase preference mining and models preference evolution through constrained editing operations, thereby improving the reliability of user semantic extraction. GAA adjusts the intensity of semantic utilization based on user activity levels, providing weaker alignment for active users and stronger guidance for users with sparse historical data. Finally, extensive experiments on three benchmark datasets demonstrate the effectiveness and compatibility of HSUGA.
Behavior-Aware Dual-Channel Preference Learning for Heterogeneous Sequential Recommendation
Apr 16, 2026Heterogeneous sequential recommendation (HSR) aims to learn dynamic behavior dependencies from the diverse behaviors of user-item interactions to facilitate precise sequential recommendation. Despite many efforts yielding promising achievements, there are still challenges in modeling heterogeneous behavior data. One significant issue is the inherent sparsity of a real-world data, which can weaken the recommendation performance. Although auxiliary behaviors (e.g., clicks) partially address this problem, they inevitably introduce some noise, and the sparsity of the target behavior (e.g., purchases) remains unresolved. Additionally, contrastive learning-based augmentation in existing methods often focuses on a single behavior type, overlooking fine-grained user preferences and losing valuable information. To address these challenges, we have meticulously designed a behavior-aware dual-channel preference learning framework (BDPL). This framework begins with the construction of customized behavior-aware subgraphs to capture personalized behavior transition relationships, followed by a novel cascade-structured graph neural network to aggregate node context information. We then model and enhance user representations through a preference-level contrastive learning paradigm, considering both long-term and short-term preferences. Finally, we fuse the overall preference information using an adaptive gating mechanism to predict the next item the user will interact with under the target behavior. Extensive experiments on three real-world datasets demonstrate the superiority of our BDPL over the state-of-the-art models.
OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models
Mar 10, 2026Multimodal large language models (MLLMs) have achieved remarkable performance across a wide range of vision language tasks. However, their ability in low-level visual perception, particularly in detecting fine-grained visual discrepancies, remains underexplored and lacks systematic analysis. In this work, we introduce OddGridBench, a controllable benchmark for evaluating the visual discrepancy sensitivity of MLLMs. OddGridBench comprises over 1,400 grid-based images, where a single element differs from all others by one or multiple visual attributes such as color, size, rotation, or position. Experiments reveal that all evaluated MLLMs, including open-source families such as Qwen3-VL and InternVL3.5, and proprietary systems like Gemini-2.5-Pro and GPT-5, perform far below human levels in visual discrepancy detection. We further propose OddGrid-GRPO, a reinforcement learning framework that integrates curriculum learning and distance-aware reward. By progressively controlling the difficulty of training samples and incorporating spatial proximity constraints into the reward design, OddGrid-GRPO significantly enhances the model's fine-grained visual discrimination ability. We hope OddGridBench and OddGrid-GRPO will lay the groundwork for advancing perceptual grounding and visual discrepancy sensitivity in multimodal intelligence. Code and dataset are available at https://wwwtttjjj.github.io/OddGridBench/.
M3SR: Multi-Scale Multi-Perceptual Mamba for Efficient Spectral Reconstruction
Jan 13, 2026The Mamba architecture has been widely applied to various low-level vision tasks due to its exceptional adaptability and strong performance. Although the Mamba architecture has been adopted for spectral reconstruction, it still faces the following two challenges: (1) Single spatial perception limits the ability to fully understand and analyze hyperspectral images; (2) Single-scale feature extraction struggles to capture the complex structures and fine details present in hyperspectral images. To address these issues, we propose a multi-scale, multi-perceptual Mamba architecture for the spectral reconstruction task, called M3SR. Specifically, we design a multi-perceptual fusion block to enhance the ability of the model to comprehensively understand and analyze the input features. By integrating the multi-perceptual fusion block into a U-Net structure, M3SR can effectively extract and fuse global, intermediate, and local features, thereby enabling accurate reconstruction of hyperspectral images at multiple scales. Extensive quantitative and qualitative experiments demonstrate that the proposed M3SR outperforms existing state-of-the-art methods while incurring a lower computational cost.
Towards Multi-Behavior Multi-Task Recommendation via Behavior-informed Graph Embedding Learning
Jan 12, 2026Multi-behavior recommendation (MBR) aims to improve the performance w.r.t. the target behavior (i.e., purchase) by leveraging auxiliary behaviors (e.g., click, favourite). However, in real-world scenarios, a recommendation method often needs to process different types of behaviors and generate personalized lists for each task (i.e., each behavior type). Such a new recommendation problem is referred to as multi-behavior multi-task recommendation (MMR). So far, the most powerful MBR methods usually model multi-behavior interactions using a cascading graph paradigm. Although significant progress has been made in optimizing the performance of the target behavior, it often neglects the performance of auxiliary behaviors. To compensate for the deficiencies of the cascading paradigm, we propose a novel solution for MMR, i.e., behavior-informed graph embedding learning (BiGEL). Specifically, we first obtain a set of behavior-aware embeddings by using a cascading graph paradigm. Subsequently, we introduce three key modules to improve the performance of the model. The cascading gated feedback (CGF) module enables a feedback-driven optimization process by integrating feedback from the target behavior to refine the auxiliary behaviors preferences. The global context enhancement (GCE) module integrates the global context to maintain the user's overall preferences, preventing the loss of key preferences due to individual behavior graph modeling. Finally, the contrastive preference alignment (CPA) module addresses the potential changes in user preferences during the cascading process by aligning the preferences of the target behaviors with the global preferences through contrastive learning. Extensive experiments on two real-world datasets demonstrate the effectiveness of our BiGEL compared with ten very competitive methods.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025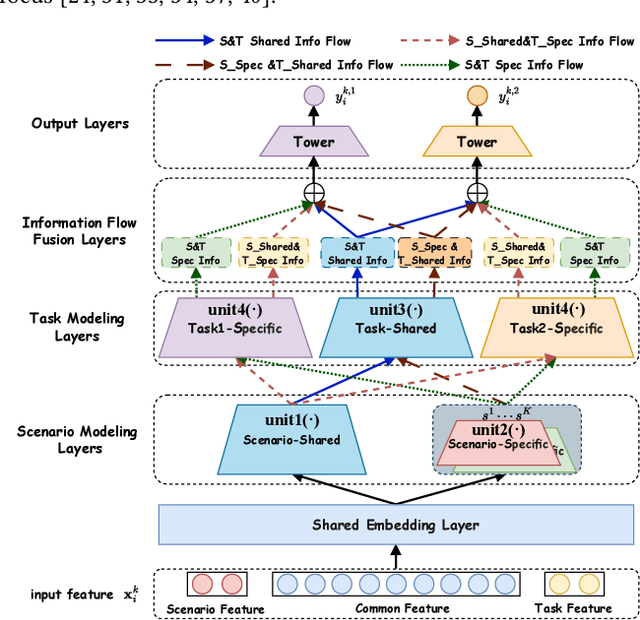
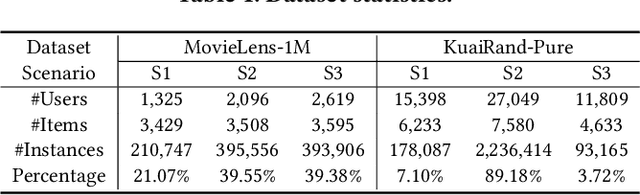
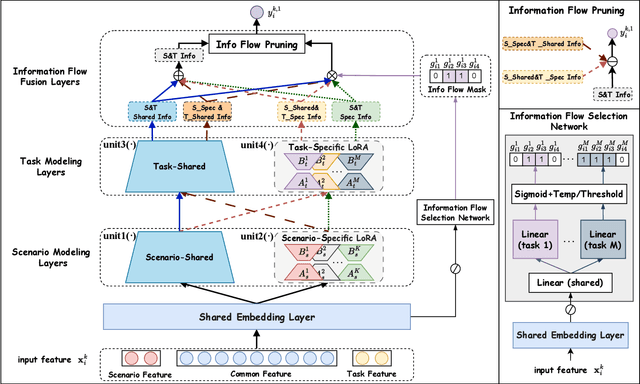
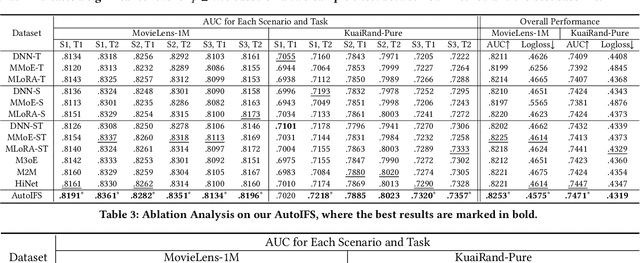
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
VisNumBench: Evaluating Number Sense of Multimodal Large Language Models
Mar 19, 2025Can Multimodal Large Language Models (MLLMs) develop an intuitive number sense similar to humans? Targeting this problem, we introduce Visual Number Benchmark (VisNumBench) to evaluate the number sense abilities of MLLMs across a wide range of visual numerical tasks. VisNumBench consists of about 1,900 multiple-choice question-answer pairs derived from both synthetic and real-world visual data, covering seven visual numerical attributes and four types of visual numerical estimation tasks. Our experiments on VisNumBench led to the following key findings: (i) The 17 MLLMs we tested, including open-source models such as Qwen2.5-VL and InternVL2.5, as well as proprietary models like GPT-4o and Gemini 2.0 Flash, perform significantly below human levels in number sense-related tasks. (ii) Multimodal mathematical models and multimodal chain-of-thought (CoT) models did not exhibit significant improvements in number sense abilities. (iii) Stronger MLLMs with larger parameter sizes and broader general abilities demonstrate modest gains in number sense abilities. We believe VisNumBench will serve as a valuable resource for the research community, encouraging further advancements in enhancing MLLMs' number sense abilities. All benchmark resources, including code and datasets, will be publicly available at https://wwwtttjjj.github.io/VisNumBench/.
A Survey on Sequential Recommendation
Dec 17, 2024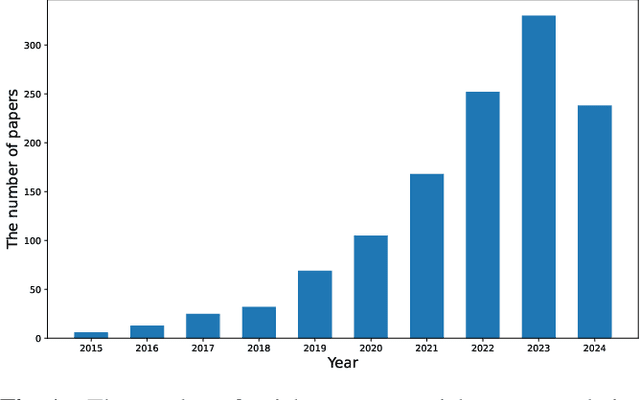
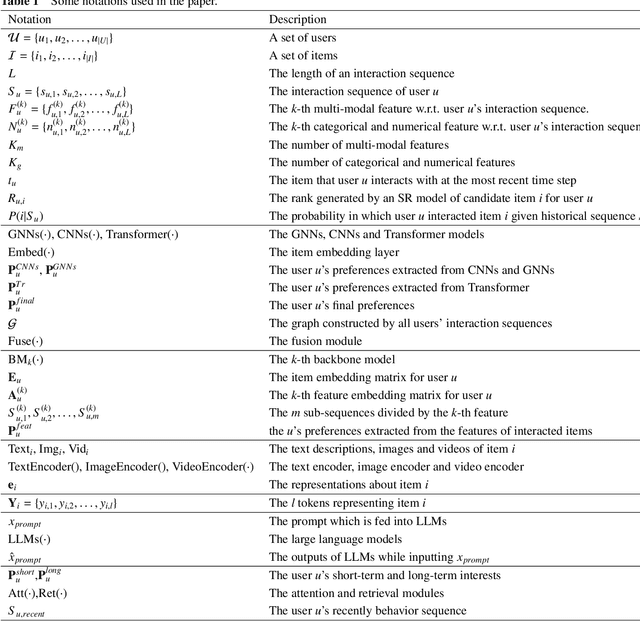
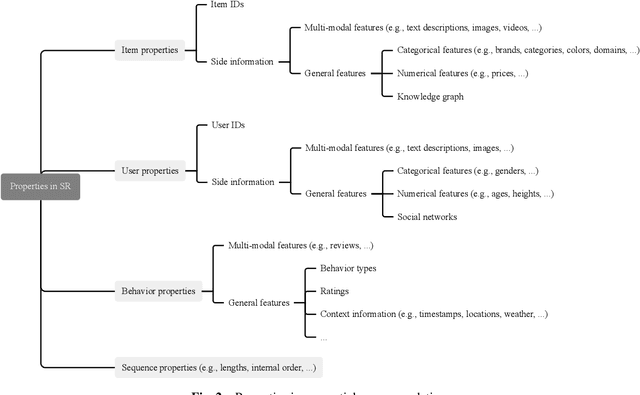
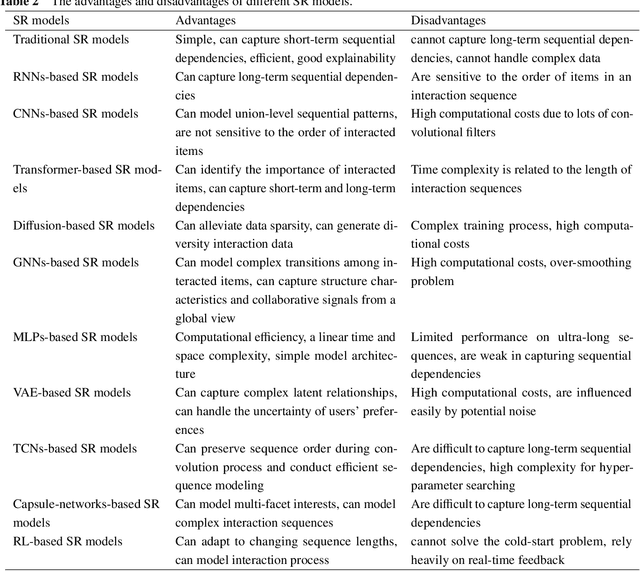
Different from most conventional recommendation problems, sequential recommendation focuses on learning users' preferences by exploiting the internal order and dependency among the interacted items, which has received significant attention from both researchers and practitioners. In recent years, we have witnessed great progress and achievements in this field, necessitating a new survey. In this survey, we study the SR problem from a new perspective (i.e., the construction of an item's properties), and summarize the most recent techniques used in sequential recommendation such as pure ID-based SR, SR with side information, multi-modal SR, generative SR, LLM-powered SR, ultra-long SR and data-augmented SR. Moreover, we introduce some frontier research topics in sequential recommendation, e.g., open-domain SR, data-centric SR, could-edge collaborative SR, continuous SR, SR for good, and explainable SR. We believe that our survey could be served as a valuable roadmap for readers in this field.
Lossless and Privacy-Preserving Graph Convolution Network for Federated Item Recommendation
Dec 02, 2024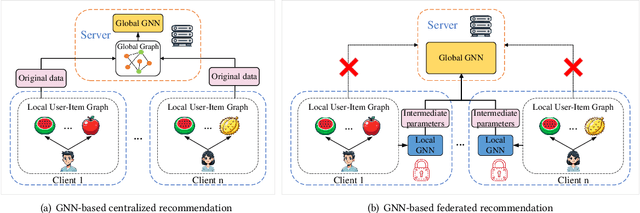


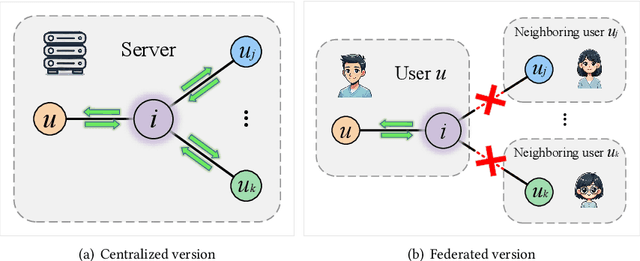
Graph neural network (GNN) has emerged as a state-of-the-art solution for item recommendation. However, existing GNN-based recommendation methods rely on a centralized storage of fragmented user-item interaction sub-graphs and training on an aggregated global graph, which will lead to privacy concerns. As a response, some recent works develop GNN-based federated recommendation methods by exploiting decentralized and fragmented user-item sub-graphs in order to preserve user privacy. However, due to privacy constraints, the graph convolution process in existing federated recommendation methods is incomplete compared with the centralized counterpart, causing a degradation of the recommendation performance. In this paper, we propose a novel lossless and privacy-preserving graph convolution network (LP-GCN), which fully completes the graph convolution process with decentralized user-item interaction sub-graphs while ensuring privacy. It is worth mentioning that its performance is equivalent to that of the non-federated (i.e., centralized) counterpart. Moreover, we validate its effectiveness through both theoretical analysis and empirical studies. Extensive experiments on three real-world datasets show that our LP-GCN outperforms the existing federated recommendation methods. The code will be publicly available once the paper is accepted.
Sample Enrichment via Temporary Operations on Subsequences for Sequential Recommendation
Jul 25, 2024



Sequential recommendation leverages interaction sequences to predict forthcoming user behaviors, crucial for crafting personalized recommendations. However, the true preferences of a user are inherently complex and high-dimensional, while the observed data is merely a simplified and low-dimensional projection of the rich preferences, which often leads to prevalent issues like data sparsity and inaccurate model training. To learn true preferences from the sparse data, most existing works endeavor to introduce some extra information or design some ingenious models. Although they have shown to be effective, extra information usually increases the cost of data collection, and complex models may result in difficulty in deployment. Innovatively, we avoid the use of extra information or alterations to the model; instead, we fill the transformation space between the observed data and the underlying preferences with randomness. Specifically, we propose a novel model-agnostic and highly generic framework for sequential recommendation called sample enrichment via temporary operations on subsequences (SETO), which temporarily and separately enriches the transformation space via sequence enhancement operations with rationality constraints in training. The transformation space not only exists in the process from input samples to preferences but also in preferences to target samples. We highlight our SETO's effectiveness and versatility over multiple representative and state-of-the-art sequential recommendation models (including six single-domain sequential models and two cross-domain sequential models) across multiple real-world datasets (including three single-domain datasets, three cross-domain datasets and a large-scale industry dataset).