 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025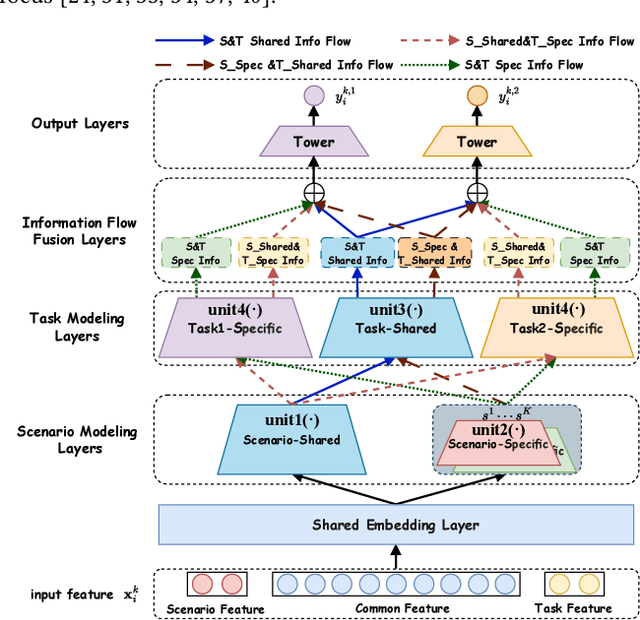
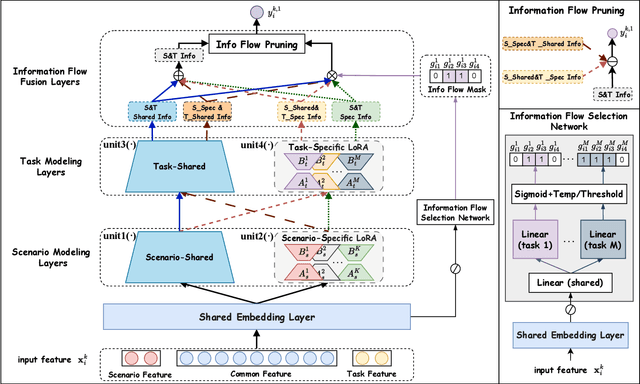
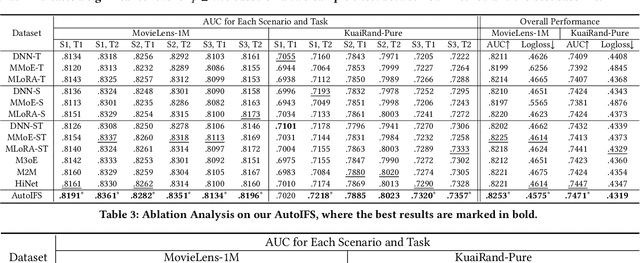
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Exploring Test-time Scaling via Prediction Merging on Large-Scale Recommendation
Dec 08, 2025Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.
Beyond Higher Rank: Token-wise Input-Output Projections for Efficient Low-Rank Adaptation
Oct 27, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). LoRA essentially describes the projection of an input space into a low-dimensional output space, with the dimensionality determined by the LoRA rank. In standard LoRA, all input tokens share the same weights and undergo an identical input-output projection. This limits LoRA's ability to capture token-specific information due to the inherent semantic differences among tokens. To address this limitation, we propose Token-wise Projected Low-Rank Adaptation (TopLoRA), which dynamically adjusts LoRA weights according to the input token, thereby learning token-wise input-output projections in an end-to-end manner. Formally, the weights of TopLoRA can be expressed as $B\Sigma_X A$, where $A$ and $B$ are low-rank matrices (as in standard LoRA), and $\Sigma_X$ is a diagonal matrix generated from each input token $X$. Notably, TopLoRA does not increase the rank of LoRA weights but achieves more granular adaptation by learning token-wise LoRA weights (i.e., token-wise input-output projections). Extensive experiments across multiple models and datasets demonstrate that TopLoRA consistently outperforms LoRA and its variants. The code is available at https://github.com/Leopold1423/toplora-neurips25.
Ultrafast Grid Impedance Identification in $dq$-Asymmetric Three-Phase Power Systems
Oct 14, 2025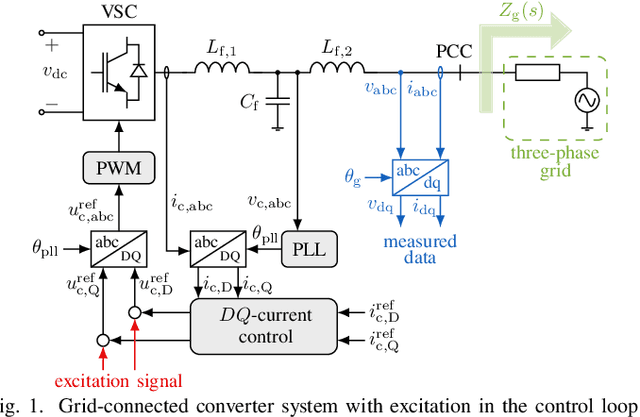


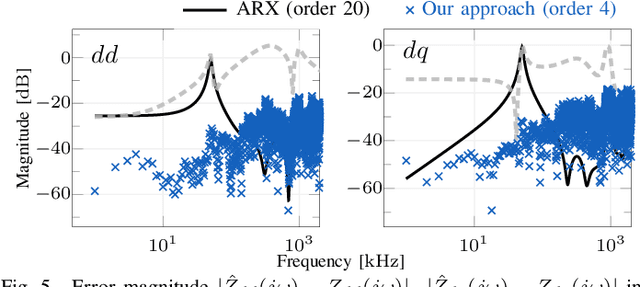
We propose a non-parametric frequency-domain method to identify small-signal $dq$-asymmetric grid impedances, over a wide frequency band, using grid-connected converters. Existing identification methods are faced with significant trade-offs: e.g., passive approaches rely on ambient harmonics and rare grid events and thus can only provide estimates at a few frequencies, while many active approaches that intentionally perturb grid operation require long time series measurement and specialized equipment. Although active time-domain methods reduce the measurement time, they either make crude simplifying assumptions or require laborious model order tuning. Our approach effectively addresses these challenges: it does not require specialized excitation signals or hardware and achieves ultrafast ($<1$ s) identification, drastically reducing measurement time. Being non-parametric, our approach also makes no assumptions on the grid structure. A detailed electromagnetic transient simulation is used to validate the method and demonstrate its clear superiority over existing alternatives.
BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity
Aug 09, 2025



Low-rank adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method widely used in large language models (LLMs). It approximates the update of a pretrained weight matrix $W\in\mathbb{R}^{m\times n}$ by the product of two low-rank matrices, $BA$, where $A \in\mathbb{R}^{r\times n}$ and $B\in\mathbb{R}^{m\times r} (r\ll\min\{m,n\})$. Increasing the dimension $r$ can raise the rank of LoRA weights (i.e., $BA$), which typically improves fine-tuning performance but also significantly increases the number of trainable parameters. In this paper, we propose Block Diversified Low-Rank Adaptation (BoRA), which improves the rank of LoRA weights with a small number of additional parameters. Specifically, BoRA treats the product $BA$ as a block matrix multiplication, where $A$ and $B$ are partitioned into $b$ blocks along the columns and rows, respectively (i.e., $A=[A_1,\dots,A_b]$ and $B=[B_1,\dots,B_b]^\top$). Consequently, the product $BA$ becomes the concatenation of the block products $B_iA_j$ for $i,j\in[b]$. To enhance the diversity of different block products, BoRA introduces a unique diagonal matrix $\Sigma_{i,j} \in \mathbb{R}^{r\times r}$ for each block multiplication, resulting in $B_i \Sigma_{i,j} A_j$. By leveraging these block-wise diagonal matrices, BoRA increases the rank of LoRA weights by a factor of $b$ while only requiring $b^2r$ additional parameters. Extensive experiments across multiple datasets and models demonstrate the superiority of BoRA, and ablation studies further validate its scalability.
Timing is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
Beyond Zero Initialization: Investigating the Impact of Non-Zero Initialization on LoRA Fine-Tuning Dynamics
May 29, 2025Low-rank adaptation (LoRA) is a widely used parameter-efficient fine-tuning method. In standard LoRA layers, one of the matrices, $A$ or $B$, is initialized to zero, ensuring that fine-tuning starts from the pretrained model. However, there is no theoretical support for this practice. In this paper, we investigate the impact of non-zero initialization on LoRA's fine-tuning dynamics from an infinite-width perspective. Our analysis reveals that, compared to zero initialization, simultaneously initializing $A$ and $B$ to non-zero values improves LoRA's robustness to suboptimal learning rates, particularly smaller ones. Further analysis indicates that although the non-zero initialization of $AB$ introduces random noise into the pretrained weight, it generally does not affect fine-tuning performance. In other words, fine-tuning does not need to strictly start from the pretrained model. The validity of our findings is confirmed through extensive experiments across various models and datasets. The code is available at https://github.com/Leopold1423/non_zero_lora-icml25.
The Panaceas for Improving Low-Rank Decomposition in Communication-Efficient Federated Learning
May 29, 2025To improve the training efficiency of federated learning (FL), previous research has employed low-rank decomposition techniques to reduce communication overhead. In this paper, we seek to enhance the performance of these low-rank decomposition methods. Specifically, we focus on three key issues related to decomposition in FL: what to decompose, how to decompose, and how to aggregate. Subsequently, we introduce three novel techniques: Model Update Decomposition (MUD), Block-wise Kronecker Decomposition (BKD), and Aggregation-Aware Decomposition (AAD), each targeting a specific issue. These techniques are complementary and can be applied simultaneously to achieve optimal performance. Additionally, we provide a rigorous theoretical analysis to ensure the convergence of the proposed MUD. Extensive experimental results show that our approach achieves faster convergence and superior accuracy compared to relevant baseline methods. The code is available at https://github.com/Leopold1423/fedmud-icml25.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.
A Predict-Then-Optimize Customer Allocation Framework for Online Fund Recommendation
Mar 05, 2025With the rapid growth of online investment platforms, funds can be distributed to individual customers online. The central issue is to match funds with potential customers under constraints. Most mainstream platforms adopt the recommendation formulation to tackle the problem. However, the traditional recommendation regime has its inherent drawbacks when applying the fund-matching problem with multiple constraints. In this paper, we model the fund matching under the allocation formulation. We design PTOFA, a Predict-Then-Optimize Fund Allocation framework. This data-driven framework consists of two stages, i.e., prediction and optimization, which aim to predict expected revenue based on customer behavior and optimize the impression allocation to achieve the maximum revenue under the necessary constraints, respectively. Extensive experiments on real-world datasets from an industrial online investment platform validate the effectiveness and efficiency of our solution. Additionally, the online A/B tests demonstrate PTOFA's effectiveness in the real-world fund recommendation scenario.