 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Noise, More Voice: Reinforcement Learning for Reasoning via Instruction Purification
Jan 29, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has advanced LLM reasoning, but remains constrained by inefficient exploration under limited rollout budgets, leading to low sampling success and unstable training in complex tasks. We find that many exploration failures arise not from problem difficulty, but from a small number of prompt tokens that introduce interference. Building on this insight, we propose the Less Noise Sampling Framework (LENS), which first prompts by identifying and removing interference tokens. then transfers successful rollouts from the purification process to supervise policy optimization on the original noisy prompts, enabling the model to learn to ignore interference in the real-world, noisy prompting settings. Experimental results show that LENS significantly outperforms GRPO, delivering higher performance and faster convergence, with a 3.88% average gain and over 1.6$\times$ speedup. Our work highlights the critical role of pruning interference tokens in improving rollout efficiency, offering a new perspective for RLVR research.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning
Jun 09, 2025Large language models (LLMs) have demonstrated significant improvements in contextual understanding. However, their ability to attend to truly critical information during long-context reasoning and generation still falls behind the pace. Specifically, our preliminary experiments reveal that certain distracting patterns can misdirect the model's attention during inference, and removing these patterns substantially improves reasoning accuracy and generation quality. We attribute this phenomenon to spurious correlations in the training data, which obstruct the model's capacity to infer authentic causal instruction-response relationships. This phenomenon may induce redundant reasoning processes, potentially resulting in significant inference overhead and, more critically, the generation of erroneous or suboptimal responses. To mitigate this, we introduce a two-stage framework called Learning to Focus (LeaF) leveraging intervention-based inference to disentangle confounding factors. In the first stage, LeaF employs gradient-based comparisons with an advanced teacher to automatically identify confounding tokens based on causal relationships in the training corpus. Then, in the second stage, it prunes these tokens during distillation to enact intervention, aligning the student's attention with the teacher's focus distribution on truly critical context tokens. Experimental results demonstrate that LeaF not only achieves an absolute improvement in various mathematical reasoning and code generation benchmarks but also effectively suppresses attention to confounding tokens during inference, yielding a more interpretable and reliable reasoning model.
Counterfactual Multi-player Bandits for Explainable Recommendation Diversification
May 27, 2025Existing recommender systems tend to prioritize items closely aligned with users' historical interactions, inevitably trapping users in the dilemma of ``filter bubble''. Recent efforts are dedicated to improving the diversity of recommendations. However, they mainly suffer from two major issues: 1) a lack of explainability, making it difficult for the system designers to understand how diverse recommendations are generated, and 2) limitations to specific metrics, with difficulty in enhancing non-differentiable diversity metrics. To this end, we propose a \textbf{C}ounterfactual \textbf{M}ulti-player \textbf{B}andits (CMB) method to deliver explainable recommendation diversification across a wide range of diversity metrics. Leveraging a counterfactual framework, our method identifies the factors influencing diversity outcomes. Meanwhile, we adopt the multi-player bandits to optimize the counterfactual optimization objective, making it adaptable to both differentiable and non-differentiable diversity metrics. Extensive experiments conducted on three real-world datasets demonstrate the applicability, effectiveness, and explainability of the proposed CMB.
What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
Mar 31, 2025As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing'' has emerged as a prominent research focus. Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A. However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding. To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale. Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment. Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions.
ARIES: Stimulating Self-Refinement of Large Language Models by Iterative Preference Optimization
Feb 08, 2025A truly intelligent Large Language Model (LLM) should be capable of correcting errors in its responses through external interactions. However, even the most advanced models often face challenges in improving their outputs. In this paper, we explore how to cultivate LLMs with the self-refinement capability through iterative preference training, and how this ability can be leveraged to improve model performance during inference. To this end, we introduce a novel post-training and inference framework, called ARIES: Adaptive Refinement and Iterative Enhancement Structure. This method iteratively performs preference training and self-refinement-based data collection. During training, ARIES strengthen the model's direct question-answering capability while simultaneously unlocking its self-refinement potential. During inference, ARIES harnesses this self-refinement capability to generate a series of progressively refined responses, which are then filtered using either the Reward Model Scoring or a simple yet effective Rule-Based Selection mechanism, specifically tailored to our approach, to construct a dataset for the next round of preference training. Experimental results demonstrate the remarkable performance of ARIES. When applied to the Llama-3.1-8B model and under the self-refinement setting, ARIES surpasses powerful models such as GPT-4o, achieving 62.3% length-controlled (LC) and a 63.3% raw win rates on AlpacaEval 2, outperforming Iterative DPO by 27.8% and 35.5% respectively, as well as a 50.3% win rate on Arena-Hard, surpassing Iterative DPO by 26.6%. Furthermore, ARIES consistently enhances performance on mathematical reasoning tasks like GSM8K and MATH.
End-to-End Cost-Effective Incentive Recommendation under Budget Constraint with Uplift Modeling
Aug 21, 2024



In modern online platforms, incentives are essential factors that enhance user engagement and increase platform revenue. Over recent years, uplift modeling has been introduced as a strategic approach to assign incentives to individual customers. Especially in many real-world applications, online platforms can only incentivize customers with specific budget constraints. This problem can be reformulated as the multi-choice knapsack problem. This optimization aims to select the optimal incentive for each customer to maximize the return on investment. Recent works in this field frequently tackle the budget allocation problem using a two-stage approach. However, this solution is confronted with the following challenges: (1) The causal inference methods often ignore the domain knowledge in online marketing, where the expected response curve of a customer should be monotonic and smooth as the incentive increases. (2) An optimality gap between the two stages results in inferior sub-optimal allocation performance due to the loss of the incentive recommendation information for the uplift prediction under the limited budget constraint. To address these challenges, we propose a novel End-to-End Cost-Effective Incentive Recommendation (E3IR) model under budget constraints. Specifically, our methods consist of two modules, i.e., the uplift prediction module and the differentiable allocation module. In the uplift prediction module, we construct prediction heads to capture the incremental improvement between adjacent treatments with the marketing domain constraints (i.e., monotonic and smooth). We incorporate integer linear programming (ILP) as a differentiable layer input in the allocation module. Furthermore, we conduct extensive experiments on public and real product datasets, demonstrating that our E3IR improves allocation performance compared to existing two-stage approaches.
OptDist: Learning Optimal Distribution for Customer Lifetime Value Prediction
Aug 16, 2024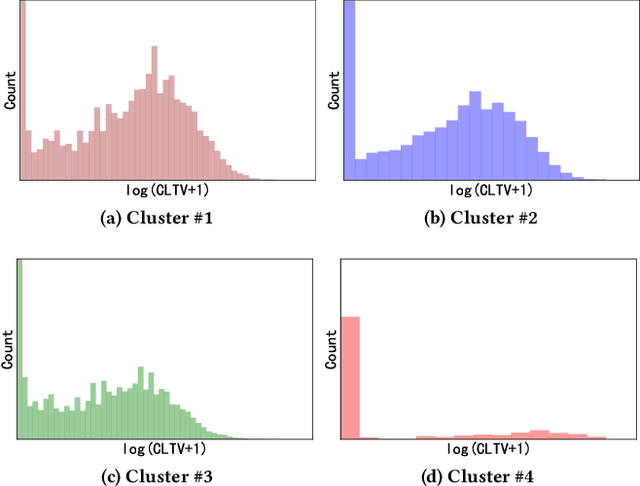
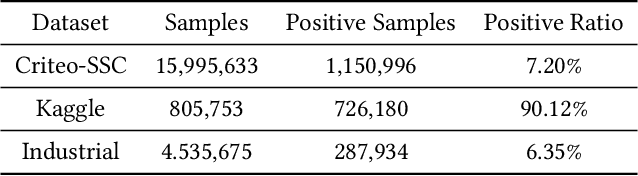
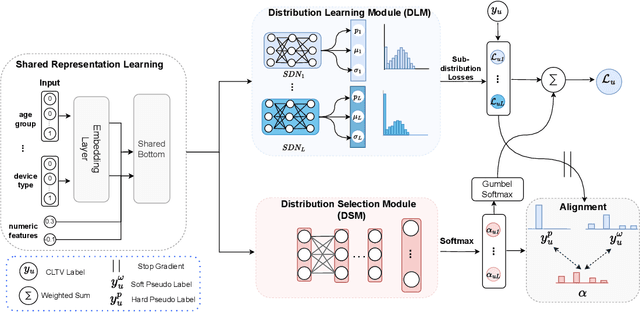
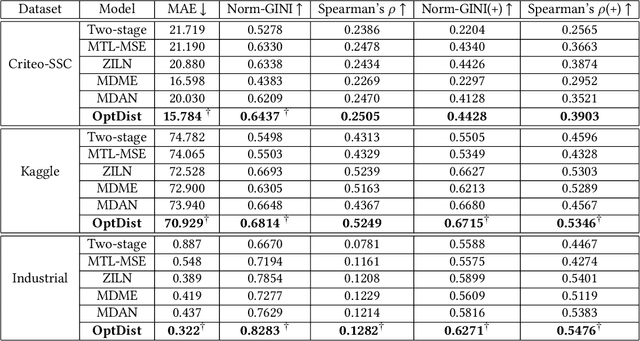
Customer Lifetime Value (CLTV) prediction is a critical task in business applications. Accurately predicting CLTV is challenging in real-world business scenarios, as the distribution of CLTV is complex and mutable. Firstly, there is a large number of users without any consumption consisting of a long-tailed part that is too complex to fit. Secondly, the small set of high-value users spent orders of magnitude more than a typical user leading to a wide range of the CLTV distribution which is hard to capture in a single distribution. Existing approaches for CLTV estimation either assume a prior probability distribution and fit a single group of distribution-related parameters for all samples, or directly learn from the posterior distribution with manually predefined buckets in a heuristic manner. However, all these methods fail to handle complex and mutable distributions. In this paper, we propose a novel optimal distribution selection model OptDist for CLTV prediction, which utilizes an adaptive optimal sub-distribution selection mechanism to improve the accuracy of complex distribution modeling. Specifically, OptDist trains several candidate sub-distribution networks in the distribution learning module (DLM) for modeling the probability distribution of CLTV. Then, a distribution selection module (DSM) is proposed to select the sub-distribution for each sample, thus making the selection automatically and adaptively. Besides, we design an alignment mechanism that connects both modules, which effectively guides the optimization. We conduct extensive experiments on both two public and one private dataset to verify that OptDist outperforms state-of-the-art baselines. Furthermore, OptDist has been deployed on a large-scale financial platform for customer acquisition marketing campaigns and the online experiments also demonstrate the effectiveness of OptDist.
Generalized Encouragement-Based Instrumental Variables for Counterfactual Regression
Aug 10, 2024



In causal inference, encouragement designs (EDs) are widely used to analyze causal effects, when randomized controlled trials (RCTs) are impractical or compliance to treatment cannot be perfectly enforced. Unlike RCTs, which directly allocate treatments, EDs randomly assign encouragement policies that positively motivate individuals to engage in a specific treatment. These random encouragements act as instrumental variables (IVs), facilitating the identification of causal effects through leveraging exogenous perturbations in discrete treatment scenarios. However, real-world applications of encouragement designs often face challenges such as incomplete randomization, limited experimental data, and significantly fewer encouragements compared to treatments, hindering precise causal effect estimation. To address this, this paper introduces novel theories and algorithms for identifying the Conditional Average Treatment Effect (CATE) using variations in encouragement. Further, by leveraging both observational and encouragement data, we propose a generalized IV estimator, named Encouragement-based Counterfactual Regression (EnCounteR), to effectively estimate the causal effects. Extensive experiments on both synthetic and real-world datasets demonstrate the superiority of EnCounteR over existing methods.
Towards Robust Recommendation via Decision Boundary-aware Graph Contrastive Learning
Jul 14, 2024



In recent years, graph contrastive learning (GCL) has received increasing attention in recommender systems due to its effectiveness in reducing bias caused by data sparsity. However, most existing GCL models rely on heuristic approaches and usually assume entity independence when constructing contrastive views. We argue that these methods struggle to strike a balance between semantic invariance and view hardness across the dynamic training process, both of which are critical factors in graph contrastive learning. To address the above issues, we propose a novel GCL-based recommendation framework RGCL, which effectively maintains the semantic invariance of contrastive pairs and dynamically adapts as the model capability evolves through the training process. Specifically, RGCL first introduces decision boundary-aware adversarial perturbations to constrain the exploration space of contrastive augmented views, avoiding the decrease of task-specific information. Furthermore, to incorporate global user-user and item-item collaboration relationships for guiding on the generation of hard contrastive views, we propose an adversarial-contrastive learning objective to construct a relation-aware view-generator. Besides, considering that unsupervised GCL could potentially narrower margins between data points and the decision boundary, resulting in decreased model robustness, we introduce the adversarial examples based on maximum perturbations to achieve margin maximization. We also provide theoretical analyses on the effectiveness of our designs. Through extensive experiments on five public datasets, we demonstrate the superiority of RGCL compared against twelve baseline models.