 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Aug 10, 2025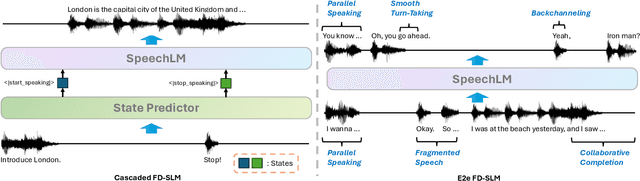

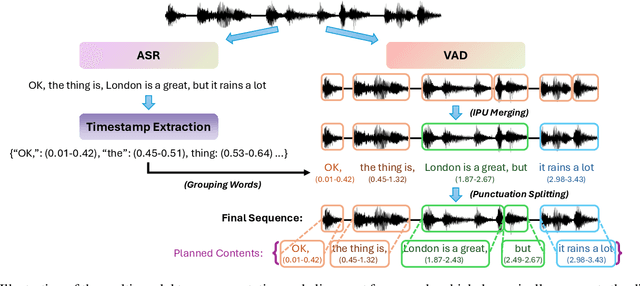
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge -- their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs' conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models
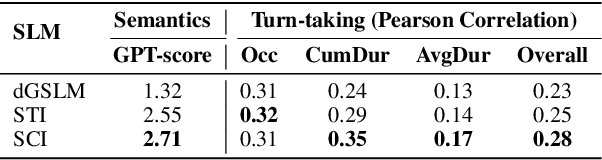
Mar 31, 2025As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing'' has emerged as a prominent research focus. Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A. However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding. To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale. Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment. Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions.
Learning Functional Dependencies with Sparse Regression
May 04, 2019


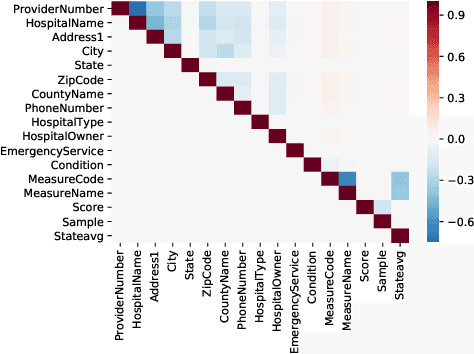
We study the problem of discovering functional dependencies (FD) from a noisy dataset. We focus on FDs that correspond to statistical dependencies in a dataset and draw connections between FD discovery and structure learning in probabilistic graphical models. We show that discovering FDs from a noisy dataset is equivalent to learning the structure of a graphical model over binary random variables, where each random variable corresponds to a functional of the dataset attributes. We build upon this observation to introduce AutoFD a conceptually simple framework in which learning functional dependencies corresponds to solving a sparse regression problem. We show that our methods can recover true functional dependencies across a diverse array of real-world and synthetic datasets, even in the presence of noisy or missing data. We find that AutoFD scales to large data instances with millions of tuples and hundreds of attributes while it yields an average F1 improvement of 2 times against state-of-the-art FD discovery methods.