 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration
Feb 03, 2026Search-integrated reasoning enables language agents to transcend static parametric knowledge by actively querying external sources. However, training these agents via reinforcement learning is hindered by the multi-scale credit assignment problem: existing methods typically rely on sparse, trajectory-level rewards that fail to distinguish between high-quality reasoning and fortuitous guesses, leading to redundant or misleading search behaviors. To address this, we propose Search-R2, a novel Actor-Refiner collaboration framework that enhances reasoning through targeted intervention, with both components jointly optimized during training. Our approach decomposes the generation process into an Actor, which produces initial reasoning trajectories, and a Meta-Refiner, which selectively diagnoses and repairs flawed steps via a 'cut-and-regenerate' mechanism. To provide fine-grained supervision, we introduce a hybrid reward design that couples outcome correctness with a dense process reward quantifying the information density of retrieved evidence. Theoretically, we formalize the Actor-Refiner interaction as a smoothed mixture policy, proving that selective correction yields strict performance gains over strong baselines. Extensive experiments across various general and multi-hop QA datasets demonstrate that Search-R2 consistently outperforms strong RAG and RL-based baselines across model scales, achieving superior reasoning accuracy with minimal overhead.
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Feb 02, 2026Token-level reweighting is a simple yet effective mechanism for controlling supervised fine-tuning, but common indicators are largely one-dimensional: the ground-truth probability reflects downstream alignment, while token entropy reflects intrinsic uncertainty induced by the pre-training prior. Ignoring entropy can misidentify noisy or easily replaceable tokens as learning-critical, while ignoring probability fails to reflect target-specific alignment. RankTuner introduces a probability--entropy calibration signal, the Relative Rank Indicator, which compares the rank of the ground-truth token with its expected rank under the prediction distribution. The inverse indicator is used as a token-wise Relative Scale to reweight the fine-tuning objective, focusing updates on truly under-learned tokens without over-penalizing intrinsically uncertain positions. Experiments on multiple backbones show consistent improvements on mathematical reasoning benchmarks, transfer gains on out-of-distribution reasoning, and pre code generation performance over probability-only or entropy-only reweighting baselines.
UrbanMoE: A Sparse Multi-Modal Mixture-of-Experts Framework for Multi-Task Urban Region Profiling
Jan 30, 2026Urban region profiling, the task of characterizing geographical areas, is crucial for urban planning and resource allocation. However, existing research in this domain faces two significant limitations. First, most methods are confined to single-task prediction, failing to capture the interconnected, multi-faceted nature of urban environments where numerous indicators are deeply correlated. Second, the field lacks a standardized experimental benchmark, which severely impedes fair comparison and reproducible progress. To address these challenges, we first establish a comprehensive benchmark for multi-task urban region profiling, featuring multi-modal features and a diverse set of strong baselines to ensure a fair and rigorous evaluation environment. Concurrently, we propose UrbanMoE, the first sparse multi-modal, multi-expert framework specifically architected to solve the multi-task challenge. Leveraging a sparse Mixture-of-Experts architecture, it dynamically routes multi-modal features to specialized sub-networks, enabling the simultaneous prediction of diverse urban indicators. We conduct extensive experiments on three real-world datasets within our benchmark, where UrbanMoE consistently demonstrates superior performance over all baselines. Further in-depth analysis validates the efficacy and efficiency of our approach, setting a new state-of-the-art and providing the community with a valuable tool for future research in urban analytics
Semi-supervised Instruction Tuning for Large Language Models on Text-Attributed Graphs
Jan 19, 2026The emergent reasoning capabilities of Large Language Models (LLMs) offer a transformative paradigm for analyzing text-attributed graphs. While instruction tuning is the prevailing method for adapting pre-trained LLMs to graph learning tasks like node classification, it requires a substantial volume of annotated (INSTRUCTION, OUTPUT) pairs deriving from labeled nodes. This requirement is particularly prohibitive in the social domain, where obtaining expert labels for sensitive or evolving content is costly and slow. Furthermore, standard graph instruction tuning fails to exploit the vast amount of unlabeled nodes, which contain latent correlations due to edge connections that are beneficial for downstream predictions. To bridge this gap, we propose a novel Semi-supervised Instruction Tuning pipeline for Graph Learning, named SIT-Graph. Notably, SIT-Graph is model-agnostic and can be seamlessly integrated into any graph instruction tuning method that utilizes LLMs as the predictor. SIT-Graph operates via an iterative self-training process. Initially, the model is fine-tuned using instruction pairs constructed solely from the labeled nodes. Then it generates confidence-filtered pseudo-responses for unlabeled nodes to strategically augment the dataset for the next round of fine-tuning. Finally, this iterative refinement progressively aligns the LLM with the underlying node correlations. Extensive experiments demonstrate that when incorporated into state-of-the-art graph instruction tuning methods, SIT-Graph significantly enhances their performance on text-attributed graph benchmarks, achieving over 20% improvement under the low label ratio settings.
ConMax: Confidence-Maximizing Compression for Efficient Chain-of-Thought Reasoning
Jan 08, 2026Recent breakthroughs in Large Reasoning Models (LRMs) have demonstrated that extensive Chain-of-Thought (CoT) generation is critical for enabling intricate cognitive behaviors, such as self-verification and backtracking, to solve complex tasks. However, this capability often leads to ``overthinking'', where models generate redundant reasoning paths that inflate computational costs without improving accuracy. While Supervised Fine-Tuning (SFT) on reasoning traces is a standard paradigm for the 'cold start' phase, applying existing compression techniques to these traces often compromises logical coherence or incurs prohibitive sampling costs. In this paper, we introduce ConMax (Confidence-Maximizing Compression), a novel reinforcement learning framework designed to automatically compress reasoning traces while preserving essential reasoning patterns. ConMax formulates compression as a reward-driven optimization problem, training a policy to prune redundancy by maximizing a weighted combination of answer confidence for predictive fidelity and thinking confidence for reasoning validity through a frozen auxiliary LRM. Extensive experiments across five reasoning datasets demonstrate that ConMax achieves a superior efficiency-performance trade-off. Specifically, it reduces inference length by 43% over strong baselines at the cost of a mere 0.7% dip in accuracy, proving its effectiveness in generating high-quality, efficient training data for LRMs.
MTR-DuplexBench: Towards a Comprehensive Evaluation of Multi-Round Conversations for Full-Duplex Speech Language Models
Nov 13, 2025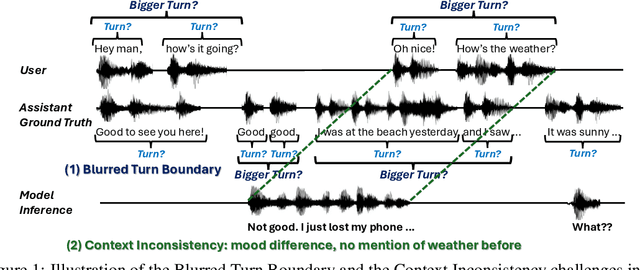

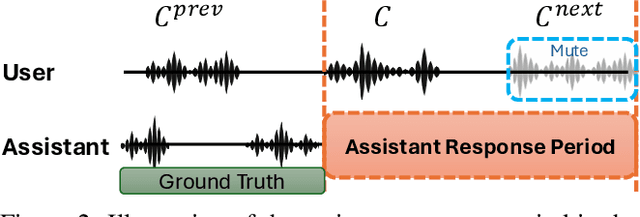

Full-Duplex Speech Language Models (FD-SLMs) enable real-time, overlapping conversational interactions, offering a more dynamic user experience compared to traditional half-duplex models. However, existing benchmarks primarily focus on evaluating single-round interactions and conversational features, neglecting the complexities of multi-round communication and critical capabilities such as instruction following and safety. Evaluating FD-SLMs in multi-round settings poses significant challenges, including blurred turn boundaries in communication and context inconsistency during model inference. To address these gaps, we introduce MTR-DuplexBench, a novel benchmark that segments continuous full-duplex dialogues into discrete turns, enabling comprehensive, turn-by-turn evaluation of FD-SLMs across dialogue quality, conversational dynamics, instruction following, and safety. Experimental results reveal that current FD-SLMs face difficulties in maintaining consistent performance across multiple rounds and evaluation dimensions, highlighting the necessity and effectiveness of our proposed benchmark. The benchmark and code will be available in the future.
ConSurv: Multimodal Continual Learning for Survival Analysis
Nov 13, 2025Survival prediction of cancers is crucial for clinical practice, as it informs mortality risks and influences treatment plans. However, a static model trained on a single dataset fails to adapt to the dynamically evolving clinical environment and continuous data streams, limiting its practical utility. While continual learning (CL) offers a solution to learn dynamically from new datasets, existing CL methods primarily focus on unimodal inputs and suffer from severe catastrophic forgetting in survival prediction. In real-world scenarios, multimodal inputs often provide comprehensive and complementary information, such as whole slide images and genomics; and neglecting inter-modal correlations negatively impacts the performance. To address the two challenges of catastrophic forgetting and complex inter-modal interactions between gigapixel whole slide images and genomics, we propose ConSurv, the first multimodal continual learning (MMCL) method for survival analysis. ConSurv incorporates two key components: Multi-staged Mixture of Experts (MS-MoE) and Feature Constrained Replay (FCR). MS-MoE captures both task-shared and task-specific knowledge at different learning stages of the network, including two modality encoders and the modality fusion component, learning inter-modal relationships. FCR further enhances learned knowledge and mitigates forgetting by restricting feature deviation of previous data at different levels, including encoder-level features of two modalities and the fusion-level representations. Additionally, we introduce a new benchmark integrating four datasets, Multimodal Survival Analysis Incremental Learning (MSAIL), for comprehensive evaluation in the CL setting. Extensive experiments demonstrate that ConSurv outperforms competing methods across multiple metrics.
Think Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Aug 10, 2025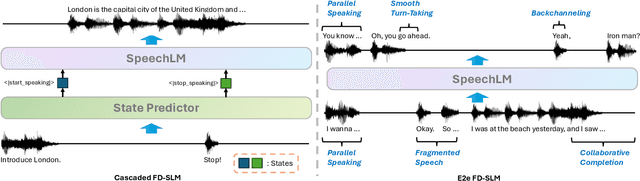

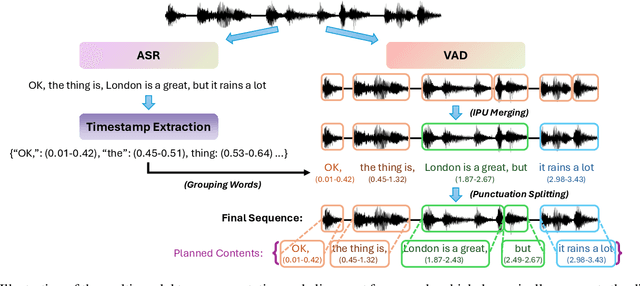
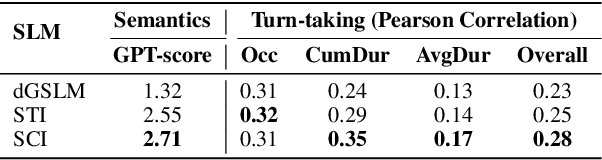
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge -- their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs' conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
Efficient Identity and Position Graph Embedding via Spectral-Based Random Feature Aggregation
May 27, 2025



Graph neural networks (GNNs), which capture graph structures via a feature aggregation mechanism following the graph embedding framework, have demonstrated a powerful ability to support various tasks. According to the topology properties (e.g., structural roles or community memberships of nodes) to be preserved, graph embedding can be categorized into identity and position embedding. However, it is unclear for most GNN-based methods which property they can capture. Some of them may also suffer from low efficiency and scalability caused by several time- and space-consuming procedures (e.g., feature extraction and training). From a perspective of graph signal processing, we find that high- and low-frequency information in the graph spectral domain may characterize node identities and positions, respectively. Based on this investigation, we propose random feature aggregation (RFA) for efficient identity and position embedding, serving as an extreme ablation study regarding GNN feature aggregation. RFA (i) adopts a spectral-based GNN without learnable parameters as its backbone, (ii) only uses random noises as inputs, and (iii) derives embeddings via just one feed-forward propagation (FFP). Inspired by degree-corrected spectral clustering, we further introduce a degree correction mechanism to the GNN backbone. Surprisingly, our experiments demonstrate that two variants of RFA with high- and low-pass filters can respectively derive informative identity and position embeddings via just one FFP (i.e., without any training). As a result, RFA can achieve a better trade-off between quality and efficiency for both identity and position embedding over various baselines.