 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Knowledge Metabolism: Generating Scientific Hypotheses from Evolving Literature
Apr 14, 2026Scientific hypothesis generation requires tracking how knowledge evolves, not just what is currently known. We introduce Continuous Knowledge Metabolism (CKM), a framework that processes scientific literature through sliding time windows and incrementally updates a structured knowledge base as new findings arrive. We present CKM-Lite, an efficient variant that achieves strong predictive coverage through incremental accumulation, outperforming batch processing on hit rate (+2.8%, p=0.006), hypothesis yield (+3.6, p<0.001), and best-match alignment (+0.43, p<0.001) while reducing token cost by 92%. To understand what drives these differences, we develop CKM-Full, an instrumented variant that categorizes each new finding as novel, confirming, or contradicting, detects knowledge change signals, and conditions hypothesis generation on the full evolution trajectory. Analyzing 892 hypotheses generated by CKM-Full across 50 research topics, alongside parallel runs of the other variants, we report four empirical observations: (1) incremental processing outperforms batch baseline across predictive and efficiency metrics; (2) change-aware instrumentation is associated with higher LLM-judged novelty (Cohen's d=3.46) but lower predictive coverage, revealing a quality-coverage trade-off; (3) a field's trajectory stability is associated with hypothesis success (r=-0.28, p=0.051), suggesting boundary conditions for literature-based prediction; (4) knowledge convergence signals are associated with nearly 5x higher hit rate than contradiction signals, pointing to differential predictability across change types. These findings suggest that the character of generated hypotheses is shaped not only by how much literature is processed, but also by how it is processed. They further indicate that evaluation frameworks must account for the quality-coverage trade-off rather than optimize for a single metric.
Parameter-Efficient Fine-Tuning of LLMs with Mixture of Space Experts
Feb 16, 2026Large Language Models (LLMs) have achieved remarkable progress, with Parameter-Efficient Fine-Tuning (PEFT) emerging as a key technique for downstream task adaptation. However, existing PEFT methods mainly operate in Euclidean space, fundamentally limiting their capacity to capture complex geometric structures inherent in language data. While alternative geometric spaces, like hyperbolic geometries for hierarchical data and spherical manifolds for circular patterns, offer theoretical advantages, forcing representations into a single manifold type ultimately limits expressiveness, even when curvature parameters are learnable. To address this, we propose Mixture of Space (MoS), a unified framework that leverages multiple geometric spaces simultaneously to learn richer, curvature-aware representations. Building on this scheme, we develop MoSLoRA, which extends Low-Rank Adaptation (LoRA) with heterogeneous geometric experts, enabling models to dynamically select or combine appropriate geometric spaces based on input context. Furthermore, to address the computational overhead of frequent manifold switching, we develop a lightweight routing mechanism. Moreover, we provide empirical insights into how curvature optimization impacts training stability and model performance. Our experiments across diverse benchmarks demonstrate that MoSLoRA consistently outperforms strong baselines, achieving up to 5.6% improvement on MATH500 and 15.9% on MAWPS.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
HypRAG: Hyperbolic Dense Retrieval for Retrieval Augmented Generation
Feb 08, 2026Embedding geometry plays a fundamental role in retrieval quality, yet dense retrievers for retrieval-augmented generation (RAG) remain largely confined to Euclidean space. However, natural language exhibits hierarchical structure from broad topics to specific entities that Euclidean embeddings fail to preserve, causing semantically distant documents to appear spuriously similar and increasing hallucination risk. To address these limitations, we introduce hyperbolic dense retrieval, developing two model variants in the Lorentz model of hyperbolic space: HyTE-FH, a fully hyperbolic transformer, and HyTE-H, a hybrid architecture projecting pre-trained Euclidean embeddings into hyperbolic space. To prevent representational collapse during sequence aggregation, we introduce the Outward Einstein Midpoint, a geometry-aware pooling operator that provably preserves hierarchical structure. On MTEB, HyTE-FH outperforms equivalent Euclidean baselines, while on RAGBench, HyTE-H achieves up to 29% gains over Euclidean baselines in context relevance and answer relevance using substantially smaller models than current state-of-the-art retrievers. Our analysis also reveals that hyperbolic representations encode document specificity through norm-based separation, with over 20% radial increase from general to specific concepts, a property absent in Euclidean embeddings, underscoring the critical role of geometric inductive bias in faithful RAG systems.
AL-GNN: Privacy-Preserving and Replay-Free Continual Graph Learning via Analytic Learning
Dec 20, 2025Continual graph learning (CGL) aims to enable graph neural networks to incrementally learn from a stream of graph structured data without forgetting previously acquired knowledge. Existing methods particularly those based on experience replay typically store and revisit past graph data to mitigate catastrophic forgetting. However, these approaches pose significant limitations, including privacy concerns, inefficiency. In this work, we propose AL GNN, a novel framework for continual graph learning that eliminates the need for backpropagation and replay buffers. Instead, AL GNN leverages principles from analytic learning theory to formulate learning as a recursive least squares optimization process. It maintains and updates model knowledge analytically through closed form classifier updates and a regularized feature autocorrelation matrix. This design enables efficient one pass training for each task, and inherently preserves data privacy by avoiding historical sample storage. Extensive experiments on multiple dynamic graph classification benchmarks demonstrate that AL GNN achieves competitive or superior performance compared to existing methods. For instance, it improves average performance by 10% on CoraFull and reduces forgetting by over 30% on Reddit, while also reducing training time by nearly 50% due to its backpropagation free design.
Hyperbolic Deep Learning for Foundation Models: A Survey
Jul 23, 2025Foundation models pre-trained on massive datasets, including large language models (LLMs), vision-language models (VLMs), and large multimodal models, have demonstrated remarkable success in diverse downstream tasks. However, recent studies have shown fundamental limitations of these models: (1) limited representational capacity, (2) lower adaptability, and (3) diminishing scalability. These shortcomings raise a critical question: is Euclidean geometry truly the optimal inductive bias for all foundation models, or could incorporating alternative geometric spaces enable models to better align with the intrinsic structure of real-world data and improve reasoning processes? Hyperbolic spaces, a class of non-Euclidean manifolds characterized by exponential volume growth with respect to distance, offer a mathematically grounded solution. These spaces enable low-distortion embeddings of hierarchical structures (e.g., trees, taxonomies) and power-law distributions with substantially fewer dimensions compared to Euclidean counterparts. Recent advances have leveraged these properties to enhance foundation models, including improving LLMs' complex reasoning ability, VLMs' zero-shot generalization, and cross-modal semantic alignment, while maintaining parameter efficiency. This paper provides a comprehensive review of hyperbolic neural networks and their recent development for foundation models. We further outline key challenges and research directions to advance the field.
Learning Along the Arrow of Time: Hyperbolic Geometry for Backward-Compatible Representation Learning
Jun 06, 2025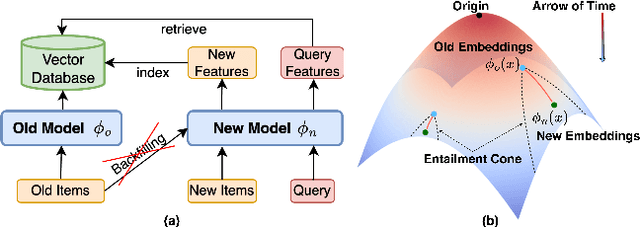
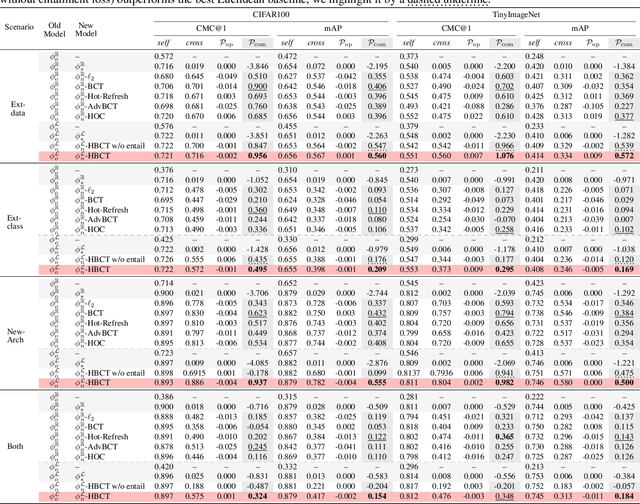
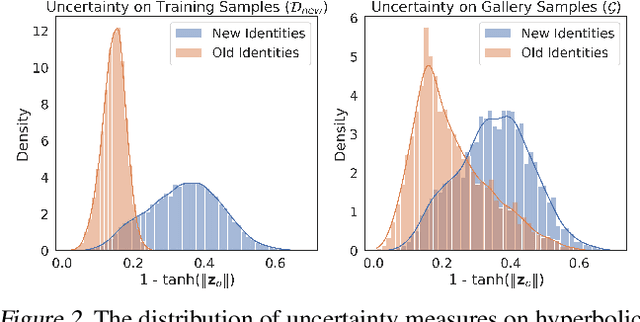
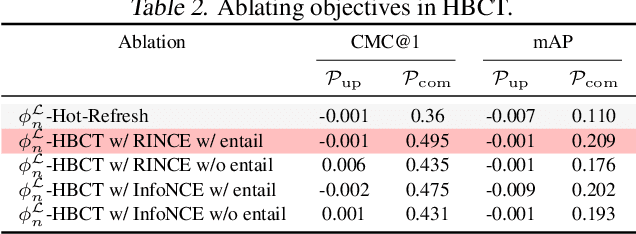
Backward compatible representation learning enables updated models to integrate seamlessly with existing ones, avoiding to reprocess stored data. Despite recent advances, existing compatibility approaches in Euclidean space neglect the uncertainty in the old embedding model and force the new model to reconstruct outdated representations regardless of their quality, thereby hindering the learning process of the new model. In this paper, we propose to switch perspectives to hyperbolic geometry, where we treat time as a natural axis for capturing a model's confidence and evolution. By lifting embeddings into hyperbolic space and constraining updated embeddings to lie within the entailment cone of the old ones, we maintain generational consistency across models while accounting for uncertainties in the representations. To further enhance compatibility, we introduce a robust contrastive alignment loss that dynamically adjusts alignment weights based on the uncertainty of the old embeddings. Experiments validate the superiority of the proposed method in achieving compatibility, paving the way for more resilient and adaptable machine learning systems.
HELM: Hyperbolic Large Language Models via Mixture-of-Curvature Experts
May 30, 2025



Large language models (LLMs) have shown great success in text modeling tasks across domains. However, natural language exhibits inherent semantic hierarchies and nuanced geometric structure, which current LLMs do not capture completely owing to their reliance on Euclidean operations. Recent studies have also shown that not respecting the geometry of token embeddings leads to training instabilities and degradation of generative capabilities. These findings suggest that shifting to non-Euclidean geometries can better align language models with the underlying geometry of text. We thus propose to operate fully in Hyperbolic space, known for its expansive, scale-free, and low-distortion properties. We thus introduce HELM, a family of HypErbolic Large Language Models, offering a geometric rethinking of the Transformer-based LLM that addresses the representational inflexibility, missing set of necessary operations, and poor scalability of existing hyperbolic LMs. We additionally introduce a Mixture-of-Curvature Experts model, HELM-MICE, where each expert operates in a distinct curvature space to encode more fine-grained geometric structure from text, as well as a dense model, HELM-D. For HELM-MICE, we further develop hyperbolic Multi-Head Latent Attention (HMLA) for efficient, reduced-KV-cache training and inference. For both models, we develop essential hyperbolic equivalents of rotary positional encodings and RMS normalization. We are the first to train fully hyperbolic LLMs at billion-parameter scale, and evaluate them on well-known benchmarks such as MMLU and ARC, spanning STEM problem-solving, general knowledge, and commonsense reasoning. Our results show consistent gains from our HELM architectures -- up to 4% -- over popular Euclidean architectures used in LLaMA and DeepSeek, highlighting the efficacy and enhanced reasoning afforded by hyperbolic geometry in large-scale LM pretraining.
Towards Non-Euclidean Foundation Models: Advancing AI Beyond Euclidean Frameworks
May 20, 2025In the era of foundation models and Large Language Models (LLMs), Euclidean space is the de facto geometric setting of our machine learning architectures. However, recent literature has demonstrated that this choice comes with fundamental limitations. To that end, non-Euclidean learning is quickly gaining traction, particularly in web-related applications where complex relationships and structures are prevalent. Non-Euclidean spaces, such as hyperbolic, spherical, and mixed-curvature spaces, have been shown to provide more efficient and effective representations for data with intrinsic geometric properties, including web-related data like social network topology, query-document relationships, and user-item interactions. Integrating foundation models with non-Euclidean geometries has great potential to enhance their ability to capture and model the underlying structures, leading to better performance in search, recommendations, and content understanding. This workshop focuses on the intersection of Non-Euclidean Foundation Models and Geometric Learning (NEGEL), exploring its potential benefits, including the potential benefits for advancing web-related technologies, challenges, and future directions. Workshop page: [https://hyperboliclearning.github.io/events/www2025workshop](https://hyperboliclearning.github.io/events/www2025workshop)
HMamba: Hyperbolic Mamba for Sequential Recommendation
May 14, 2025Sequential recommendation systems have become a cornerstone of personalized services, adept at modeling the temporal evolution of user preferences by capturing dynamic interaction sequences. Existing approaches predominantly rely on traditional models, including RNNs and Transformers. Despite their success in local pattern recognition, Transformer-based methods suffer from quadratic computational complexity and a tendency toward superficial attention patterns, limiting their ability to infer enduring preference hierarchies in sequential recommendation data. Recent advances in Mamba-based sequential models introduce linear-time efficiency but remain constrained by Euclidean geometry, failing to leverage the intrinsic hyperbolic structure of recommendation data. To bridge this gap, we propose Hyperbolic Mamba, a novel architecture that unifies the efficiency of Mamba's selective state space mechanism with hyperbolic geometry's hierarchical representational power. Our framework introduces (1) a hyperbolic selective state space that maintains curvature-aware sequence modeling and (2) stabilized Riemannian operations to enable scalable training. Experiments across four benchmarks demonstrate that Hyperbolic Mamba achieves 3-11% improvement while retaining Mamba's linear-time efficiency, enabling real-world deployment. This work establishes a new paradigm for efficient, hierarchy-aware sequential modeling.