 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainDyn: A Sheaf Neural ODE for Generative Brain Dynamics
May 19, 2026Efficient neural network models that generate brain-like dynamic activity can be a valuable resource for generating synthetic data, analyzing differences in brain transients under conditions such as testing perturbation activity or inferring the underlying generative dynamics. However, large language models (LLMs) or standard recurrent neural networks (RNNs) ignore the anatomical organization and therefore do not produce components that align with brain regions. On the other hand, graph-based networks often have very simple message passing rules that are not sufficiently expressive for brain-like dynamics. To address this, we introduce BrainDyn, a sheaf neural ordinary differential equation (neural ODE) model for continuous-time dynamics on structured brain graphs. BrainDyn encodes the recent activity history of each brain region using a long short-term memory (LSTM) model over a sliding temporal window to produce hidden states, or stalks, that are projected through learnable restriction maps into edge-specific shared spaces. Discrepancies between neighboring nodes in these shared spaces are characterized by a sheaf Laplacian that can facilitate message passing between neuronal units. The output of these messages is then fed to a neural ODE that governs the continuous-time evolution of neuronal activity. We evaluated BrainDyn on resting-state fMRI (PNC dataset), scalp EEG with focal epilepsy (TUSZ dataset), and simulated activity from the NEST spiking network simulator. BrainDyn achieves strong forecasting ability across modalities, and the resulting representations support downstream tasks including in silico perturbation prediction.
scShapeBench: Discovering geometry from high dimensional scRNAseq data
May 12, 2026High-dimensional point cloud data arise across many scientific domains, especially single-cell biology. The shapes or topologies of these datasets determine the types of information that can be extracted. For example, clustered data supports cell-type identification, trajectory structures support transition analysis, and archetypal structures capture continua of cellular behaviors. Existing analysis pipelines often assume a specific shape. The standard Seurat pipeline combines UMAP visualization with Louvain clustering and therefore assumes clustered data, while tools such as Monocle and SPADE assume tree-like structures, and flow-based models such as MIOFlow and Conditional Flow Matching target trajectories. Choosing which pipeline to apply is therefore often left to bioinformaticians who visually inspect datasets before selecting an analysis strategy. With the rise of agentic AI scientists, automating shape detection is increasingly important for selecting downstream analysis pipelines. To address this problem, we introduce scShapeBench, a benchmark dataset for shape detection containing both synthetic and expert-annotated single-cell datasets. Synthetic datasets are sampled from ground-truth skeleton graphs with controlled variance. Real single-cell datasets are curated from diverse sources and annotated by experts into four categories: clusters, single trajectory, multi-branching, and archetypal. We additionally introduce scReebTower, a baseline method that uses diffusion geometry to extract Reeb graphs and connect visualization with pipeline selection. We provide topology-aware evaluation metrics and compare scReebTower against PAGA and Mapper on synthetic and real data. Our results indicate that scReebTower outperforms existing baselines. Overall, our contributions span benchmarks, evaluation metrics, and a baseline for automated shape detection in single-cell data.
MIOFlow 2.0: A unified framework for inferring cellular stochastic dynamics from single cell and spatial transcriptomics data
Mar 23, 2026Understanding cellular trajectories via time-resolved single-cell transcriptomics is vital for studying development, regeneration, and disease. A key challenge is inferring continuous trajectories from discrete snapshots. Biological complexity stems from stochastic cell fate decisions, temporal proliferation changes, and spatial environmental influences. Current methods often use deterministic interpolations treating cells in isolation, failing to capture the probabilistic branching, population shifts, and niche-dependent signaling driving real biological processes. We introduce Manifold Interpolating Optimal-Transport Flow (MIOFlow) 2.0. This framework learns biologically informed cellular trajectories by integrating manifold learning, optimal transport, and neural differential equations. It models three core processes: (1) stochasticity and branching via Neural Stochastic Differential Equations; (2) non-conservative population changes using a learned growth-rate model initialized with unbalanced optimal transport; and (3) environmental influence through a joint latent space unifying gene expression with spatial features like local cell type composition and signaling. By operating in a PHATE-distance matching autoencoder latent space, MIOFlow 2.0 ensures trajectories respect the data's intrinsic geometry. Empirical comparisons show expressive trajectory learning via neural differential equations outperforms existing generative models, including simulation-free flow matching. Validated on synthetic datasets, embryoid body differentiation, and spatially resolved axolotl brain regeneration, MIOFlow 2.0 improves trajectory accuracy and reveals hidden drivers of cellular transitions, like specific signaling niches. MIOFlow 2.0 thus bridges single-cell and spatial transcriptomics to uncover tissue-scale trajectories.
HypRAG: Hyperbolic Dense Retrieval for Retrieval Augmented Generation
Feb 08, 2026Embedding geometry plays a fundamental role in retrieval quality, yet dense retrievers for retrieval-augmented generation (RAG) remain largely confined to Euclidean space. However, natural language exhibits hierarchical structure from broad topics to specific entities that Euclidean embeddings fail to preserve, causing semantically distant documents to appear spuriously similar and increasing hallucination risk. To address these limitations, we introduce hyperbolic dense retrieval, developing two model variants in the Lorentz model of hyperbolic space: HyTE-FH, a fully hyperbolic transformer, and HyTE-H, a hybrid architecture projecting pre-trained Euclidean embeddings into hyperbolic space. To prevent representational collapse during sequence aggregation, we introduce the Outward Einstein Midpoint, a geometry-aware pooling operator that provably preserves hierarchical structure. On MTEB, HyTE-FH outperforms equivalent Euclidean baselines, while on RAGBench, HyTE-H achieves up to 29% gains over Euclidean baselines in context relevance and answer relevance using substantially smaller models than current state-of-the-art retrievers. Our analysis also reveals that hyperbolic representations encode document specificity through norm-based separation, with over 20% radial increase from general to specific concepts, a property absent in Euclidean embeddings, underscoring the critical role of geometric inductive bias in faithful RAG systems.
Dispersion Loss Counteracts Embedding Condensation and Improves Generalization in Small Language Models
Jan 30, 2026Large language models (LLMs) achieve remarkable performance through ever-increasing parameter counts, but scaling incurs steep computational costs. To better understand LLM scaling, we study representational differences between LLMs and their smaller counterparts, with the goal of replicating the representational qualities of larger models in the smaller models. We observe a geometric phenomenon which we term $\textbf{embedding condensation}$, where token embeddings collapse into a narrow cone-like subspace in some language models. Through systematic analyses across multiple Transformer families, we show that small models such as $\texttt{GPT2}$ and $\texttt{Qwen3-0.6B}$ exhibit severe condensation, whereas the larger models such as $\texttt{GPT2-xl}$ and $\texttt{Qwen3-32B}$ are more resistant to this phenomenon. Additional observations show that embedding condensation is not reliably mitigated by knowledge distillation from larger models. To fight against it, we formulate a dispersion loss that explicitly encourages embedding dispersion during training. Experiments demonstrate that it mitigates condensation, recovers dispersion patterns seen in larger models, and yields performance gains across 10 benchmarks. We believe this work offers a principled path toward improving smaller Transformers without additional parameters.
Self-Supervised Visual Prompting for Cross-Domain Road Damage Detection
Nov 16, 2025
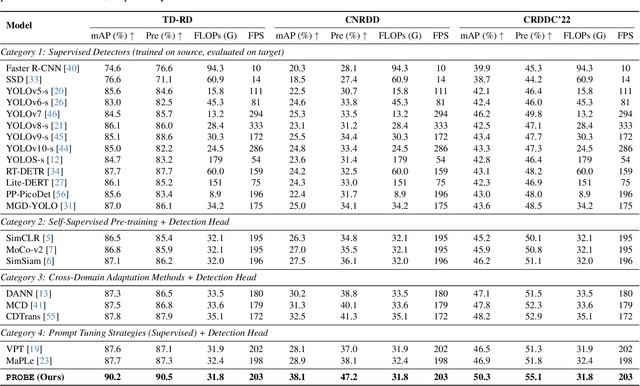
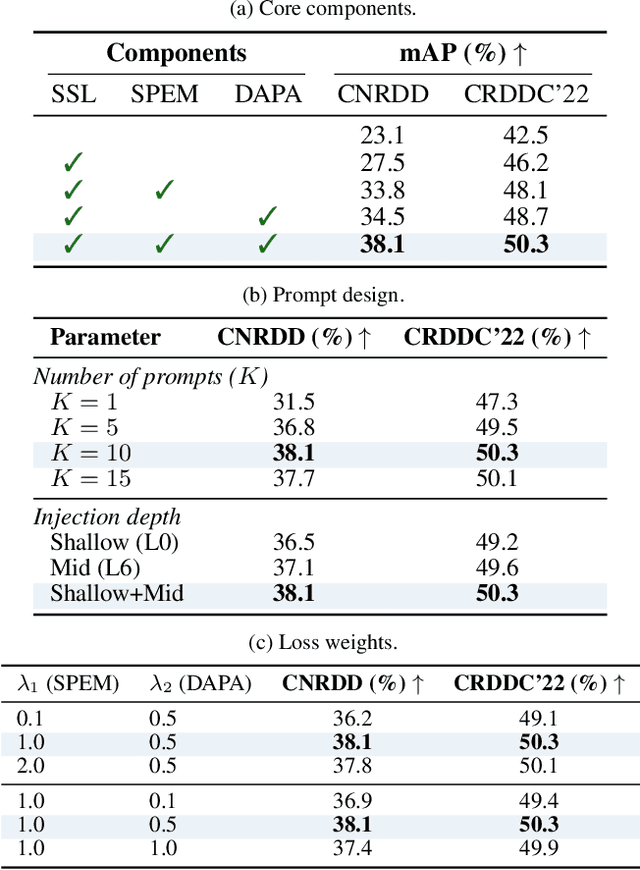

The deployment of automated pavement defect detection is often hindered by poor cross-domain generalization. Supervised detectors achieve strong in-domain accuracy but require costly re-annotation for new environments, while standard self-supervised methods capture generic features and remain vulnerable to domain shift. We propose \ours, a self-supervised framework that \emph{visually probes} target domains without labels. \ours introduces a Self-supervised Prompt Enhancement Module (SPEM), which derives defect-aware prompts from unlabeled target data to guide a frozen ViT backbone, and a Domain-Aware Prompt Alignment (DAPA) objective, which aligns prompt-conditioned source and target representations. Experiments on four challenging benchmarks show that \ours consistently outperforms strong supervised, self-supervised, and adaptation baselines, achieving robust zero-shot transfer, improved resilience to domain variations, and high data efficiency in few-shot adaptation. These results highlight self-supervised prompting as a practical direction for building scalable and adaptive visual inspection systems. Source code is publicly available: https://github.com/xixiaouab/PROBE/tree/main
STAGED: A Multi-Agent Neural Network for Learning Cellular Interaction Dynamics
Jul 15, 2025The advent of single-cell technology has significantly improved our understanding of cellular states and subpopulations in various tissues under normal and diseased conditions by employing data-driven approaches such as clustering and trajectory inference. However, these methods consider cells as independent data points of population distributions. With spatial transcriptomics, we can represent cellular organization, along with dynamic cell-cell interactions that lead to changes in cell state. Still, key computational advances are necessary to enable the data-driven learning of such complex interactive cellular dynamics. While agent-based modeling (ABM) provides a powerful framework, traditional approaches rely on handcrafted rules derived from domain knowledge rather than data-driven approaches. To address this, we introduce Spatio Temporal Agent-Based Graph Evolution Dynamics(STAGED) integrating ABM with deep learning to model intercellular communication, and its effect on the intracellular gene regulatory network. Using graph ODE networks (GDEs) with shared weights per cell type, our approach represents genes as vertices and interactions as directed edges, dynamically learning their strengths through a designed attention mechanism. Trained to match continuous trajectories of simulated as well as inferred trajectories from spatial transcriptomics data, the model captures both intercellular and intracellular interactions, enabling a more adaptive and accurate representation of cellular dynamics.
HEIST: A Graph Foundation Model for Spatial Transcriptomics and Proteomics Data
Jun 11, 2025Single-cell transcriptomics has become a great source for data-driven insights into biology, enabling the use of advanced deep learning methods to understand cellular heterogeneity and transcriptional regulation at the single-cell level. With the advent of spatial transcriptomics data we have the promise of learning about cells within a tissue context as it provides both spatial coordinates and transcriptomic readouts. However, existing models either ignore spatial resolution or the gene regulatory information. Gene regulation in cells can change depending on microenvironmental cues from neighboring cells, but existing models neglect gene regulatory patterns with hierarchical dependencies across levels of abstraction. In order to create contextualized representations of cells and genes from spatial transcriptomics data, we introduce HEIST, a hierarchical graph transformer-based foundation model for spatial transcriptomics and proteomics data. HEIST models tissue as spatial cellular neighborhood graphs, and each cell is, in turn, modeled as a gene regulatory network graph. The framework includes a hierarchical graph transformer that performs cross-level message passing and message passing within levels. HEIST is pre-trained on 22.3M cells from 124 tissues across 15 organs using spatially-aware contrastive learning and masked auto-encoding objectives. Unsupervised analysis of HEIST representations of cells, shows that it effectively encodes the microenvironmental influences in cell embeddings, enabling the discovery of spatially-informed subpopulations that prior models fail to differentiate. Further, HEIST achieves state-of-the-art results on four downstream task such as clinical outcome prediction, cell type annotation, gene imputation, and spatially-informed cell clustering across multiple technologies, highlighting the importance of hierarchical modeling and GRN-based representations.
HELM: Hyperbolic Large Language Models via Mixture-of-Curvature Experts
May 30, 2025



Large language models (LLMs) have shown great success in text modeling tasks across domains. However, natural language exhibits inherent semantic hierarchies and nuanced geometric structure, which current LLMs do not capture completely owing to their reliance on Euclidean operations. Recent studies have also shown that not respecting the geometry of token embeddings leads to training instabilities and degradation of generative capabilities. These findings suggest that shifting to non-Euclidean geometries can better align language models with the underlying geometry of text. We thus propose to operate fully in Hyperbolic space, known for its expansive, scale-free, and low-distortion properties. We thus introduce HELM, a family of HypErbolic Large Language Models, offering a geometric rethinking of the Transformer-based LLM that addresses the representational inflexibility, missing set of necessary operations, and poor scalability of existing hyperbolic LMs. We additionally introduce a Mixture-of-Curvature Experts model, HELM-MICE, where each expert operates in a distinct curvature space to encode more fine-grained geometric structure from text, as well as a dense model, HELM-D. For HELM-MICE, we further develop hyperbolic Multi-Head Latent Attention (HMLA) for efficient, reduced-KV-cache training and inference. For both models, we develop essential hyperbolic equivalents of rotary positional encodings and RMS normalization. We are the first to train fully hyperbolic LLMs at billion-parameter scale, and evaluate them on well-known benchmarks such as MMLU and ARC, spanning STEM problem-solving, general knowledge, and commonsense reasoning. Our results show consistent gains from our HELM architectures -- up to 4% -- over popular Euclidean architectures used in LLaMA and DeepSeek, highlighting the efficacy and enhanced reasoning afforded by hyperbolic geometry in large-scale LM pretraining.
InfoGain Wavelets: Furthering the Design of Diffusion Wavelets for Graph-Structured Data
Apr 08, 2025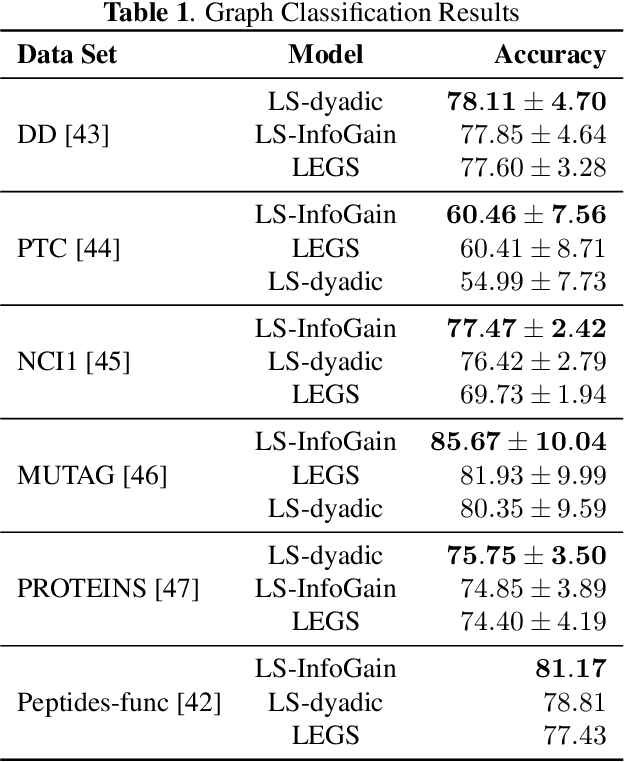
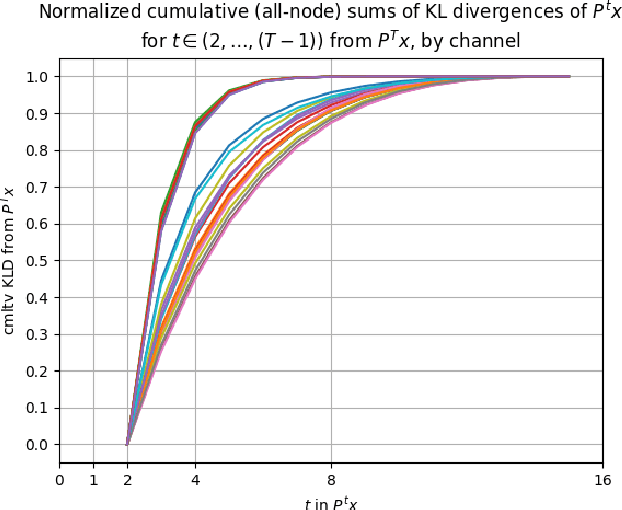
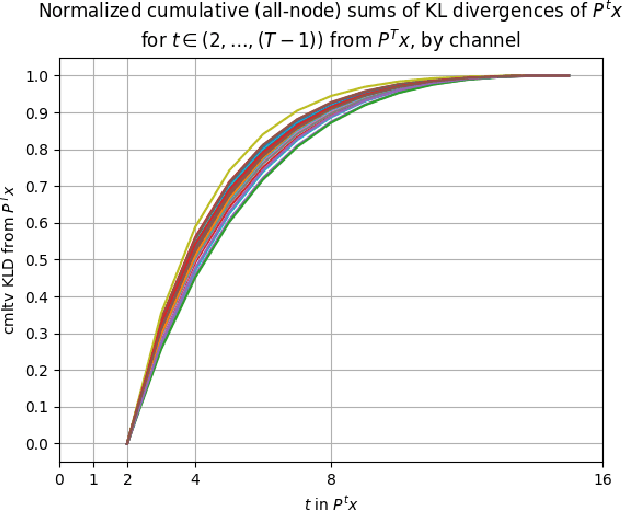
Diffusion wavelets extract information from graph signals at different scales of resolution by utilizing graph diffusion operators raised to various powers, known as diffusion scales. Traditionally, the diffusion scales are chosen to be dyadic integers, $\mathbf{2^j}$. Here, we propose a novel, unsupervised method for selecting the diffusion scales based on ideas from information theory. We then show that our method can be incorporated into wavelet-based GNNs via graph classification experiments.