 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAP: Local ECT-Based Learnable Positional Encodings for Graphs
Oct 01, 2025Graph neural networks (GNNs) largely rely on the message-passing paradigm, where nodes iteratively aggregate information from their neighbors. Yet, standard message passing neural networks (MPNNs) face well-documented theoretical and practical limitations. Graph positional encoding (PE) has emerged as a promising direction to address these limitations. The Euler Characteristic Transform (ECT) is an efficiently computable geometric-topological invariant that characterizes shapes and graphs. In this work, we combine the differentiable approximation of the ECT (DECT) and its local variant ($\ell$-ECT) to propose LEAP, a new end-to-end trainable local structural PE for graphs. We evaluate our approach on multiple real-world datasets as well as on a synthetic task designed to test its ability to extract topological features. Our results underline the potential of LEAP-based encodings as a powerful component for graph representation learning pipelines.
EmbedOR: Provable Cluster-Preserving Visualizations with Curvature-Based Stochastic Neighbor Embeddings
Sep 03, 2025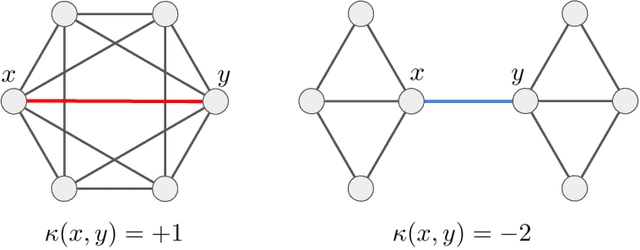
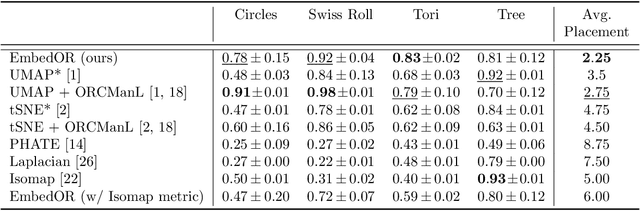


Stochastic Neighbor Embedding (SNE) algorithms like UMAP and tSNE often produce visualizations that do not preserve the geometry of noisy and high dimensional data. In particular, they can spuriously separate connected components of the underlying data submanifold and can fail to find clusters in well-clusterable data. To address these limitations, we propose EmbedOR, a SNE algorithm that incorporates discrete graph curvature. Our algorithm stochastically embeds the data using a curvature-enhanced distance metric that emphasizes underlying cluster structure. Critically, we prove that the EmbedOR distance metric extends consistency results for tSNE to a much broader class of datasets. We also describe extensive experiments on synthetic and real data that demonstrate the visualization and geometry-preservation capabilities of EmbedOR. We find that, unlike other SNE algorithms and UMAP, EmbedOR is much less likely to fragment continuous, high-density regions of the data. Finally, we demonstrate that the EmbedOR distance metric can be used as a tool to annotate existing visualizations to identify fragmentation and provide deeper insight into the underlying geometry of the data.
Geometry-Aware Edge Pooling for Graph Neural Networks
Jun 13, 2025Graph Neural Networks (GNNs) have shown significant success for graph-based tasks. Motivated by the prevalence of large datasets in real-world applications, pooling layers are crucial components of GNNs. By reducing the size of input graphs, pooling enables faster training and potentially better generalisation. However, existing pooling operations often optimise for the learning task at the expense of fundamental graph structures and interpretability. This leads to unreliable performance across varying dataset types, downstream tasks and pooling ratios. Addressing these concerns, we propose novel graph pooling layers for structure aware pooling via edge collapses. Our methods leverage diffusion geometry and iteratively reduce a graph's size while preserving both its metric structure and structural diversity. We guide pooling using magnitude, an isometry-invariant diversity measure, which permits us to control the fidelity of the pooling process. Further, we use the spread of a metric space as a faster and more stable alternative ensuring computational efficiency. Empirical results demonstrate that our methods (i) achieve superior performance compared to alternative pooling layers across a range of diverse graph classification tasks, (ii) preserve key spectral properties of the input graphs, and (iii) retain high accuracy across varying pooling ratios.
Graph and Simplicial Complex Prediction Gaussian Process via the Hodgelet Representations
May 16, 2025Predicting the labels of graph-structured data is crucial in scientific applications and is often achieved using graph neural networks (GNNs). However, when data is scarce, GNNs suffer from overfitting, leading to poor performance. Recently, Gaussian processes (GPs) with graph-level inputs have been proposed as an alternative. In this work, we extend the Gaussian process framework to simplicial complexes (SCs), enabling the handling of edge-level attributes and attributes supported on higher-order simplices. We further augment the resulting SC representations by considering their Hodge decompositions, allowing us to account for homological information, such as the number of holes, in the SC. We demonstrate that our framework enhances the predictions across various applications, paving the way for GPs to be more widely used for graph and SC-level predictions.
Principal Curvatures Estimation with Applications to Single Cell Data
Feb 06, 2025



The rapidly growing field of single-cell transcriptomic sequencing (scRNAseq) presents challenges for data analysis due to its massive datasets. A common method in manifold learning consists in hypothesizing that datasets lie on a lower dimensional manifold. This allows to study the geometry of point clouds by extracting meaningful descriptors like curvature. In this work, we will present Adaptive Local PCA (AdaL-PCA), a data-driven method for accurately estimating various notions of intrinsic curvature on data manifolds, in particular principal curvatures for surfaces. The model relies on local PCA to estimate the tangent spaces. The evaluation of AdaL-PCA on sampled surfaces shows state-of-the-art results. Combined with a PHATE embedding, the model applied to single-cell RNA sequencing data allows us to identify key variations in the cellular differentiation.
No Metric to Rule Them All: Toward Principled Evaluations of Graph-Learning Datasets
Feb 04, 2025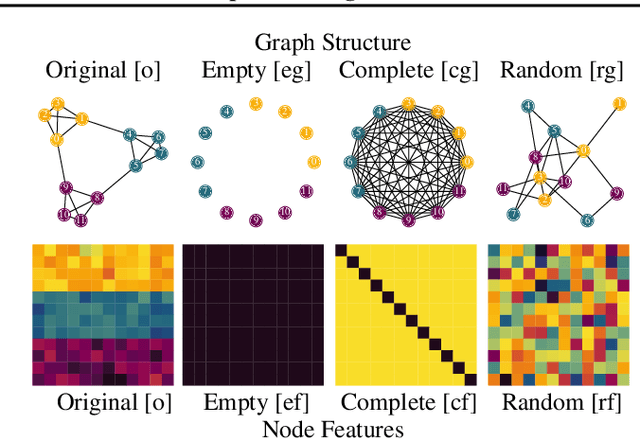
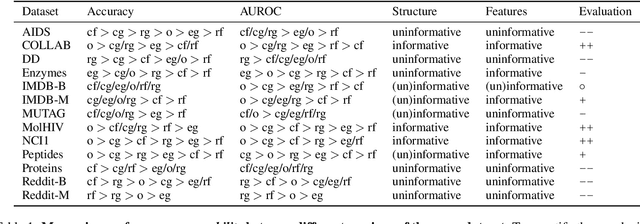
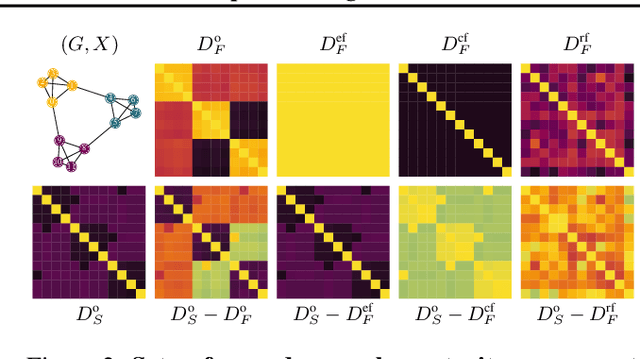
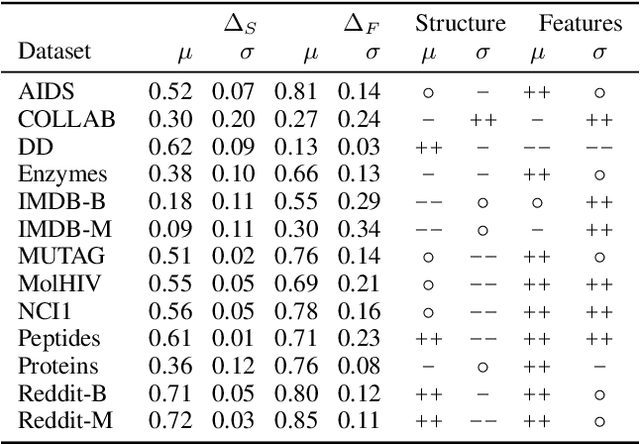
Benchmark datasets have proved pivotal to the success of graph learning, and good benchmark datasets are crucial to guide the development of the field. Recent research has highlighted problems with graph-learning datasets and benchmarking practices -- revealing, for example, that methods which ignore the graph structure can outperform graph-based approaches on popular benchmark datasets. Such findings raise two questions: (1) What makes a good graph-learning dataset, and (2) how can we evaluate dataset quality in graph learning? Our work addresses these questions. As the classic evaluation setup uses datasets to evaluate models, it does not apply to dataset evaluation. Hence, we start from first principles. Observing that graph-learning datasets uniquely combine two modes -- the graph structure and the node features -- , we introduce RINGS, a flexible and extensible mode-perturbation framework to assess the quality of graph-learning datasets based on dataset ablations -- i.e., by quantifying differences between the original dataset and its perturbed representations. Within this framework, we propose two measures -- performance separability and mode complementarity -- as evaluation tools, each assessing, from a distinct angle, the capacity of a graph dataset to benchmark the power and efficacy of graph-learning methods. We demonstrate the utility of our framework for graph-learning dataset evaluation in an extensive set of experiments and derive actionable recommendations for improving the evaluation of graph-learning methods. Our work opens new research directions in data-centric graph learning, and it constitutes a first step toward the systematic evaluation of evaluations.
Topology meets Machine Learning: An Introduction using the Euler Characteristic Transform
Oct 23, 2024



This overview article makes the case for how topological concepts can enrich research in machine learning. Using the Euler Characteristic Transform (ECT), a geometrical-topological invariant, as a running example, I present different use cases that result in more efficient models for analyzing point clouds, graphs, and meshes. Moreover, I outline a vision for how topological concepts could be used in the future, comprising (1) the learning of functions on topological spaces, (2) the building of hybrid models that imbue neural networks with knowledge about the topological information in data, and (3) the analysis of qualitative properties of neural networks. With current research already addressing some of these aspects, this article thus serves as an introduction and invitation to this nascent area of research.
Detecting and Approximating Redundant Computational Blocks in Neural Networks
Oct 07, 2024Deep neural networks often learn similar internal representations, both across different models and within their own layers. While inter-network similarities have enabled techniques such as model stitching and merging, intra-network similarities present new opportunities for designing more efficient architectures. In this paper, we investigate the emergence of these internal similarities across different layers in diverse neural architectures, showing that similarity patterns emerge independently of the datataset used. We introduce a simple metric, Block Redundancy, to detect redundant blocks, providing a foundation for future architectural optimization methods. Building on this, we propose Redundant Blocks Approximation (RBA), a general framework that identifies and approximates one or more redundant computational blocks using simpler transformations. We show that the transformation $\mathcal{T}$ between two representations can be efficiently computed in closed-form, and it is enough to replace the redundant blocks from the network. RBA reduces model parameters and time complexity while maintaining good performance. We validate our method on classification tasks in the vision domain using a variety of pretrained foundational models and datasets.
Diss-l-ECT: Dissecting Graph Data with local Euler Characteristic Transforms
Oct 03, 2024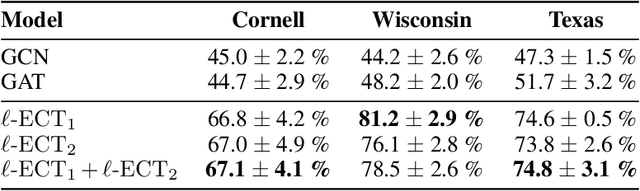


The Euler Characteristic Transform (ECT) is an efficiently-computable geometrical-topological invariant that characterizes the global shape of data. In this paper, we introduce the Local Euler Characteristic Transform ($\ell$-ECT), a novel extension of the ECT particularly designed to enhance expressivity and interpretability in graph representation learning. Unlike traditional Graph Neural Networks (GNNs), which may lose critical local details through aggregation, the $\ell$-ECT provides a lossless representation of local neighborhoods. This approach addresses key limitations in GNNs by preserving nuanced local structures while maintaining global interpretability. Moreover, we construct a rotation-invariant metric based on $\ell$-ECTs for spatial alignment of data spaces. Our method exhibits superior performance than standard GNNs on a variety of node classification tasks, particularly in graphs with high heterophily.
MANTRA: The Manifold Triangulations Assemblage
Oct 03, 2024
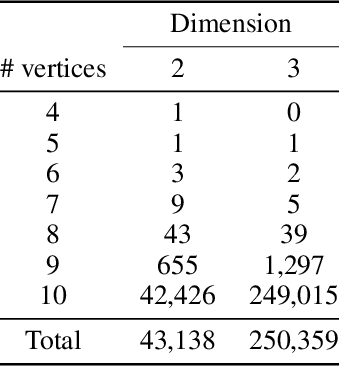

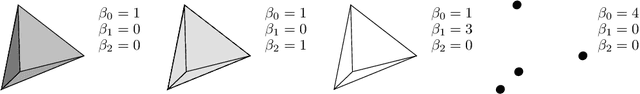
The rising interest in leveraging higher-order interactions present in complex systems has led to a surge in more expressive models exploiting high-order structures in the data, especially in topological deep learning (TDL), which designs neural networks on high-order domains such as simplicial complexes. However, progress in this field is hindered by the scarcity of datasets for benchmarking these architectures. To address this gap, we introduce MANTRA, the first large-scale, diverse, and intrinsically high order dataset for benchmarking high-order models, comprising over 43,000 and 249,000 triangulations of surfaces and three-dimensional manifolds, respectively. With MANTRA, we assess several graph- and simplicial complex-based models on three topological classification tasks. We demonstrate that while simplicial complex-based neural networks generally outperform their graph-based counterparts in capturing simple topological invariants, they also struggle, suggesting a rethink of TDL. Thus, MANTRA serves as a benchmark for assessing and advancing topological methods, leading the way for more effective high-order models.