 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finite Time Analysis of Thompson Sampling for Bayesian Optimization with Preferential Feedback
Apr 27, 2026Preference feedback, in the form of pairwise comparisons rather than scalar scores, has seen increasing use in applications such as human-, laboratory-, and expert-in-the-loop design, as well as scientific discovery. We propose a Thompson Sampling (TS) approach to Bayesian optimization with preferential feedback that models comparisons using a monotone link on latent utility differences and leverages the dueling kernel induced by a base kernel. We provide a finite-time analysis showing that the performance of the proposed method matches that of standard TS for conventional Bayesian optimization with scalar feedback. The analysis exploits the anchor invariance of TS for challenger selection and introduces a double-TS pairing variant. We also demonstrate the performance of the method on both synthetic and real-world examples.
Cross-Tokenizer LLM Distillation through a Byte-Level Interface
Apr 08, 2026Cross-tokenizer distillation (CTD), the transfer of knowledge from a teacher to a student language model when the two use different tokenizers, remains a largely unsolved problem. Existing approaches rely on heuristic strategies to align mismatched vocabularies, introducing considerable complexity. In this paper, we propose a simple but effective baseline called Byte-Level Distillation (BLD) which enables CTD by operating at a common interface across tokenizers: the byte level. In more detail, we convert the teacher's output distribution to byte-level probabilities, attach a lightweight byte-level decoder head to the student, and distill through this shared byte-level interface. Despite its simplicity, BLD performs competitively with--and on several benchmarks surpasses--significantly more sophisticated CTD methods, across a range of distillation tasks with models from 1B to 8B parameters. Our results suggest that the byte level is a natural common ground for cross-tokenizer knowledge transfer, while also highlighting that consistent improvements across all tasks and benchmarks remain elusive, underscoring that CTD is still an open problem.
Towards a Foundation Model for Communication Systems
May 20, 2025
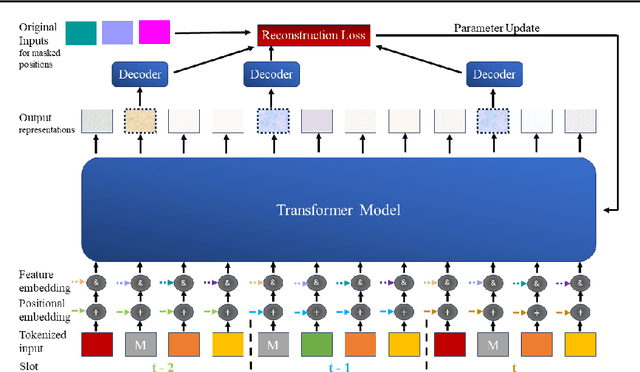
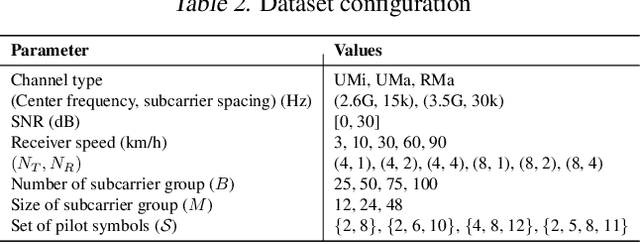
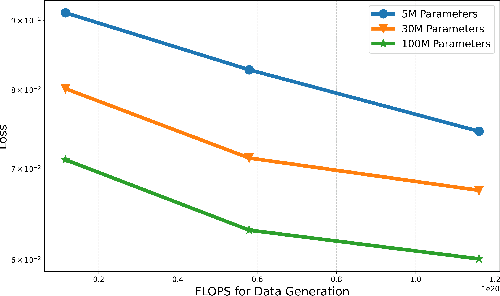
Artificial Intelligence (AI) has demonstrated unprecedented performance across various domains, and its application to communication systems is an active area of research. While current methods focus on task-specific solutions, the broader trend in AI is shifting toward large general models capable of supporting multiple applications. In this work, we take a step toward a foundation model for communication data--a transformer-based, multi-modal model designed to operate directly on communication data. We propose methodologies to address key challenges, including tokenization, positional embedding, multimodality, variable feature sizes, and normalization. Furthermore, we empirically demonstrate that such a model can successfully estimate multiple features, including transmission rank, selected precoder, Doppler spread, and delay profile.
Group Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity
May 16, 2025Recent advances in large language models (LLMs) have demonstrated the power of reasoning through self-generated chains of thought. Multiple reasoning agents can collaborate to raise joint reasoning quality above individual outcomes. However, such agents typically interact in a turn-based manner, trading increased latency for improved quality. In this paper, we propose Group Think--a single LLM that acts as multiple concurrent reasoning agents, or thinkers. With shared visibility into each other's partial generation progress, Group Think introduces a new concurrent-reasoning paradigm in which multiple reasoning trajectories adapt dynamically to one another at the token level. For example, a reasoning thread may shift its generation mid-sentence upon detecting that another thread is better positioned to continue. This fine-grained, token-level collaboration enables Group Think to reduce redundant reasoning and improve quality while achieving significantly lower latency. Moreover, its concurrent nature allows for efficient utilization of idle computational resources, making it especially suitable for edge inference, where very small batch size often underutilizes local~GPUs. We give a simple and generalizable modification that enables any existing LLM to perform Group Think on a local GPU. We also present an evaluation strategy to benchmark reasoning latency and empirically demonstrate latency improvements using open-source LLMs that were not explicitly trained for Group Think. We hope this work paves the way for future LLMs to exhibit more sophisticated and more efficient collaborative behavior for higher quality generation.
Exact, Tractable Gauss-Newton Optimization in Deep Reversible Architectures Reveal Poor Generalization
Nov 13, 2024


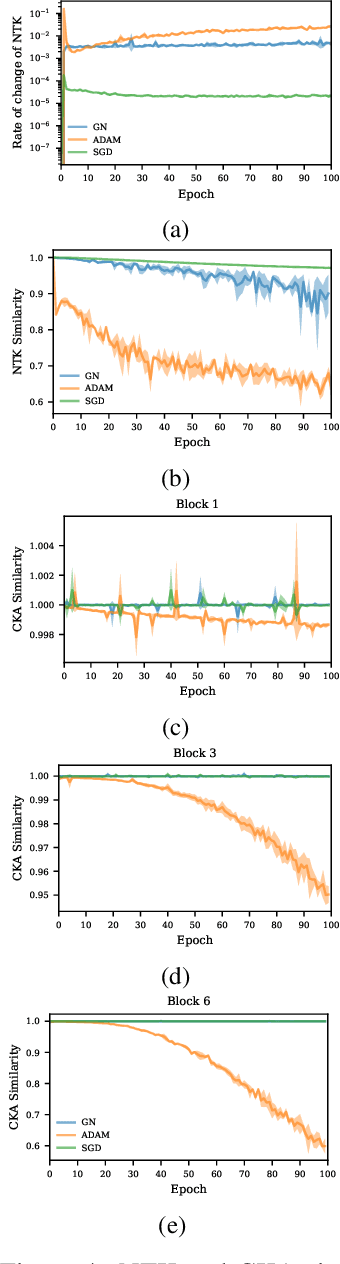
Second-order optimization has been shown to accelerate the training of deep neural networks in many applications, often yielding faster progress per iteration on the training loss compared to first-order optimizers. However, the generalization properties of second-order methods are still being debated. Theoretical investigations have proved difficult to carry out outside the tractable settings of heavily simplified model classes -- thus, the relevance of existing theories to practical deep learning applications remains unclear. Similarly, empirical studies in large-scale models and real datasets are significantly confounded by the necessity to approximate second-order updates in practice. It is often unclear whether the observed generalization behaviour arises specifically from the second-order nature of the parameter updates, or instead reflects the specific structured (e.g.\ Kronecker) approximations used or any damping-based interpolation towards first-order updates. Here, we show for the first time that exact Gauss-Newton (GN) updates take on a tractable form in a class of deep reversible architectures that are sufficiently expressive to be meaningfully applied to common benchmark datasets. We exploit this novel setting to study the training and generalization properties of the GN optimizer. We find that exact GN generalizes poorly. In the mini-batch training setting, this manifests as rapidly saturating progress even on the \emph{training} loss, with parameter updates found to overfit each mini-batchatch without producing the features that would support generalization to other mini-batches. We show that our experiments run in the ``lazy'' regime, in which the neural tangent kernel (NTK) changes very little during the course of training. This behaviour is associated with having no significant changes in neural representations, explaining the lack of generalization.
Deep Equilibrium Algorithmic Reasoning
Oct 19, 2024Neural Algorithmic Reasoning (NAR) research has demonstrated that graph neural networks (GNNs) could learn to execute classical algorithms. However, most previous approaches have always used a recurrent architecture, where each iteration of the GNN matches an iteration of the algorithm. In this paper we study neurally solving algorithms from a different perspective: since the algorithm's solution is often an equilibrium, it is possible to find the solution directly by solving an equilibrium equation. Our approach requires no information on the ground-truth number of steps of the algorithm, both during train and test time. Furthermore, the proposed method improves the performance of GNNs on executing algorithms and is a step towards speeding up existing NAR models. Our empirical evidence, leveraging algorithms from the CLRS-30 benchmark, validates that one can train a network to solve algorithmic problems by directly finding the equilibrium. We discuss the practical implementation of such models and propose regularisations to improve the performance of these equilibrium reasoners.
CliquePH: Higher-Order Information for Graph Neural Networks through Persistent Homology on Clique Graphs
Sep 12, 2024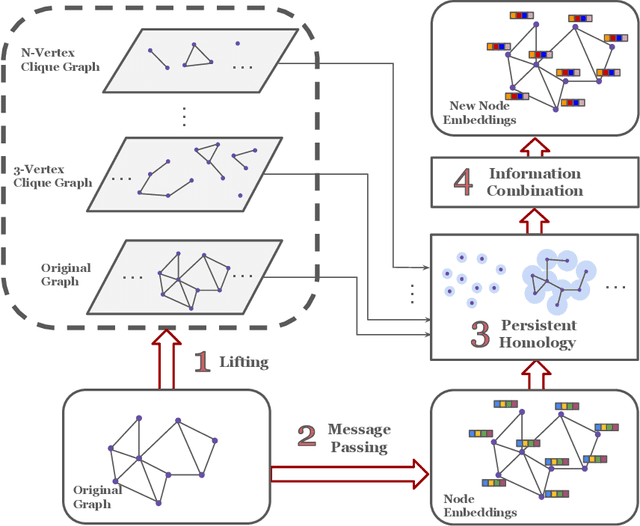
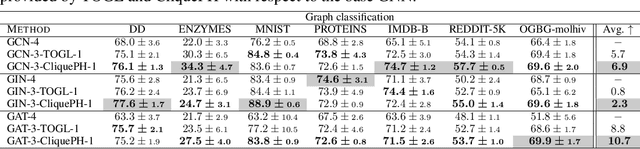
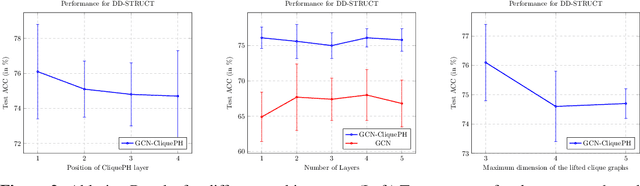

Graph neural networks have become the default choice by practitioners for graph learning tasks such as graph classification and node classification. Nevertheless, popular graph neural network models still struggle to capture higher-order information, i.e., information that goes \emph{beyond} pairwise interactions. Recent work has shown that persistent homology, a tool from topological data analysis, can enrich graph neural networks with topological information that they otherwise could not capture. Calculating such features is efficient for dimension 0 (connected components) and dimension 1 (cycles). However, when it comes to higher-order structures, it does not scale well, with a complexity of $O(n^d)$, where $n$ is the number of nodes and $d$ is the order of the structures. In this work, we introduce a novel method that extracts information about higher-order structures in the graph while still using the efficient low-dimensional persistent homology algorithm. On standard benchmark datasets, we show that our method can lead to up to $31\%$ improvements in test accuracy.
The Deep Equilibrium Algorithmic Reasoner
Feb 09, 2024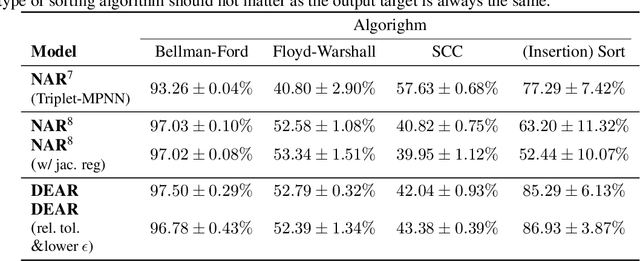
Recent work on neural algorithmic reasoning has demonstrated that graph neural networks (GNNs) could learn to execute classical algorithms. Doing so, however, has always used a recurrent architecture, where each iteration of the GNN aligns with an algorithm's iteration. Since an algorithm's solution is often an equilibrium, we conjecture and empirically validate that one can train a network to solve algorithmic problems by directly finding the equilibrium. Note that this does not require matching each GNN iteration with a step of the algorithm.
Is Meta-Learning the Right Approach for the Cold-Start Problem in Recommender Systems?
Aug 16, 2023



Recommender systems have become fundamental building blocks of modern online products and services, and have a substantial impact on user experience. In the past few years, deep learning methods have attracted a lot of research, and are now heavily used in modern real-world recommender systems. Nevertheless, dealing with recommendations in the cold-start setting, e.g., when a user has done limited interactions in the system, is a problem that remains far from solved. Meta-learning techniques, and in particular optimization-based meta-learning, have recently become the most popular approaches in the academic research literature for tackling the cold-start problem in deep learning models for recommender systems. However, current meta-learning approaches are not practical for real-world recommender systems, which have billions of users and items, and strict latency requirements. In this paper we show that it is possible to obtaining similar, or higher, performance on commonly used benchmarks for the cold-start problem without using meta-learning techniques. In more detail, we show that, when tuned correctly, standard and widely adopted deep learning models perform just as well as newer meta-learning models. We further show that an extremely simple modular approach using common representation learning techniques, can perform comparably to meta-learning techniques specifically designed for the cold-start setting while being much more easily deployable in real-world applications.
Extending Logic Explained Networks to Text Classification
Nov 04, 2022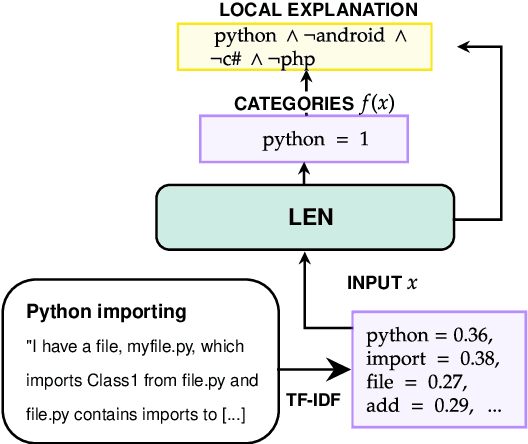
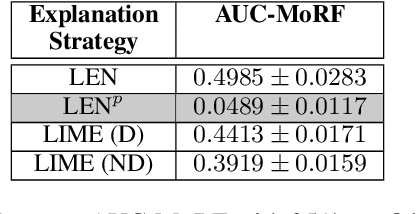
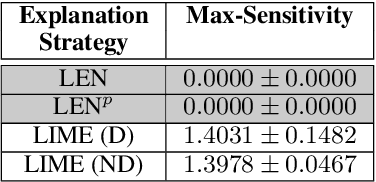

Recently, Logic Explained Networks (LENs) have been proposed as explainable-by-design neural models providing logic explanations for their predictions. However, these models have only been applied to vision and tabular data, and they mostly favour the generation of global explanations, while local ones tend to be noisy and verbose. For these reasons, we propose LENp, improving local explanations by perturbing input words, and we test it on text classification. Our results show that (i) LENp provides better local explanations than LIME in terms of sensitivity and faithfulness, and (ii) logic explanations are more useful and user-friendly than feature scoring provided by LIME as attested by a human survey.