 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMultiAgents: A Multi-Agent Framework for Video Question Answering
Apr 30, 2025Video Question Answering (VQA) inherently relies on multimodal reasoning, integrating visual, temporal, and linguistic cues to achieve a deeper understanding of video content. However, many existing methods rely on feeding frame-level captions into a single model, making it difficult to adequately capture temporal and interactive contexts. To address this limitation, we introduce VideoMultiAgents, a framework that integrates specialized agents for vision, scene graph analysis, and text processing. It enhances video understanding leveraging complementary multimodal reasoning from independently operating agents. Our approach is also supplemented with a question-guided caption generation, which produces captions that highlight objects, actions, and temporal transitions directly relevant to a given query, thus improving the answer accuracy. Experimental results demonstrate that our method achieves state-of-the-art performance on Intent-QA (79.0%, +6.2% over previous SOTA), EgoSchema subset (75.4%, +3.4%), and NExT-QA (79.6%, +0.4%). The source code is available at https://github.com/PanasonicConnect/VideoMultiAgents.
When Federated Learning Meets Quantum Computing: Survey and Research Opportunities
Apr 09, 2025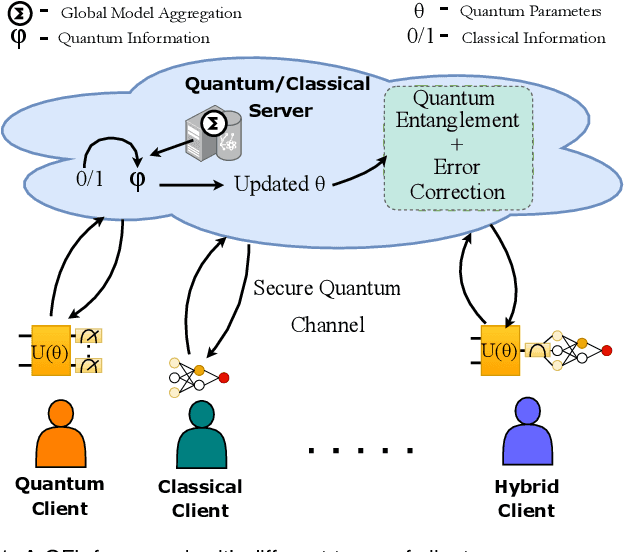
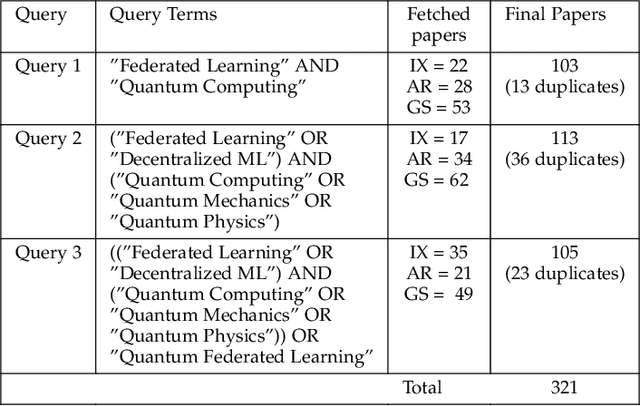
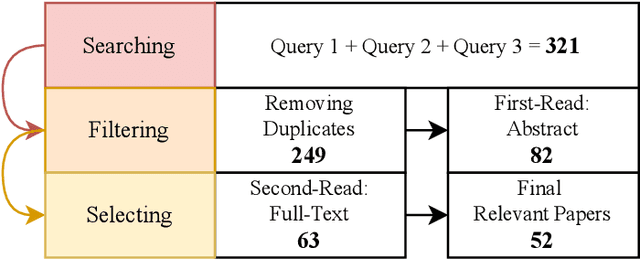
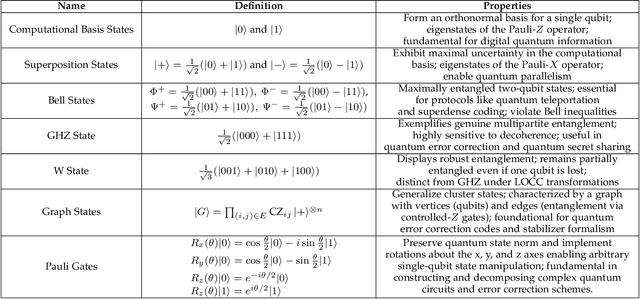
Quantum Federated Learning (QFL) is an emerging field that harnesses advances in Quantum Computing (QC) to improve the scalability and efficiency of decentralized Federated Learning (FL) models. This paper provides a systematic and comprehensive survey of the emerging problems and solutions when FL meets QC, from research protocol to a novel taxonomy, particularly focusing on both quantum and federated limitations, such as their architectures, Noisy Intermediate Scale Quantum (NISQ) devices, and privacy preservation, so on. This work explores key developments and integration strategies, along with the impact of quantum computing on FL, keeping a sharp focus on hybrid quantum-classical approaches. The paper offers an in-depth understanding of how the strengths of QC, such as gradient hiding, state entanglement, quantum key distribution, quantum security, and quantum-enhanced differential privacy, have been integrated into FL to ensure the privacy of participants in an enhanced, fast, and secure framework. Finally, this study proposes potential future directions to address the identified research gaps and challenges, aiming to inspire faster and more secure QFL models for practical use.
Tackling Selfish Clients in Federated Learning
Jul 22, 2024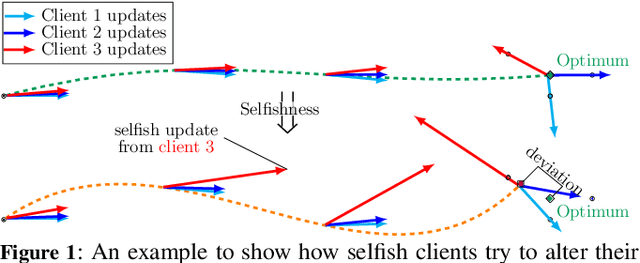
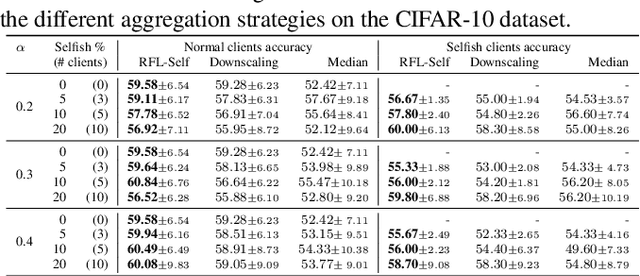
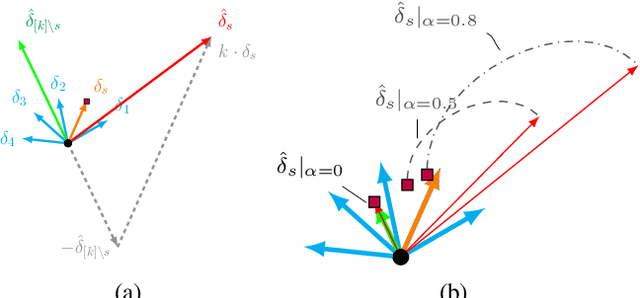
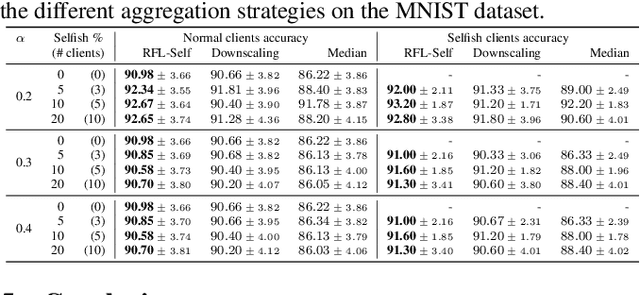
Federated Learning (FL) is a distributed machine learning paradigm facilitating participants to collaboratively train a model without revealing their local data. However, when FL is deployed into the wild, some intelligent clients can deliberately deviate from the standard training process to make the global model inclined toward their local model, thereby prioritizing their local data distribution. We refer to this novel category of misbehaving clients as selfish. In this paper, we propose a Robust aggregation strategy for FL server to mitigate the effect of Selfishness (in short RFL-Self). RFL-Self incorporates an innovative method to recover (or estimate) the true updates of selfish clients from the received ones, leveraging robust statistics (median of norms) of the updates at every round. By including the recovered updates in aggregation, our strategy offers strong robustness against selfishness. Our experimental results, obtained on MNIST and CIFAR-10 datasets, demonstrate that just 2% of clients behaving selfishly can decrease the accuracy by up to 36%, and RFL-Self can mitigate that effect without degrading the global model performance.
NurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
Is Meta-Learning the Right Approach for the Cold-Start Problem in Recommender Systems?
Aug 16, 2023



Recommender systems have become fundamental building blocks of modern online products and services, and have a substantial impact on user experience. In the past few years, deep learning methods have attracted a lot of research, and are now heavily used in modern real-world recommender systems. Nevertheless, dealing with recommendations in the cold-start setting, e.g., when a user has done limited interactions in the system, is a problem that remains far from solved. Meta-learning techniques, and in particular optimization-based meta-learning, have recently become the most popular approaches in the academic research literature for tackling the cold-start problem in deep learning models for recommender systems. However, current meta-learning approaches are not practical for real-world recommender systems, which have billions of users and items, and strict latency requirements. In this paper we show that it is possible to obtaining similar, or higher, performance on commonly used benchmarks for the cold-start problem without using meta-learning techniques. In more detail, we show that, when tuned correctly, standard and widely adopted deep learning models perform just as well as newer meta-learning models. We further show that an extremely simple modular approach using common representation learning techniques, can perform comparably to meta-learning techniques specifically designed for the cold-start setting while being much more easily deployable in real-world applications.
Physics-informed radial basis network : A local approximating neural network for solving nonlinear PDEs
Apr 20, 2023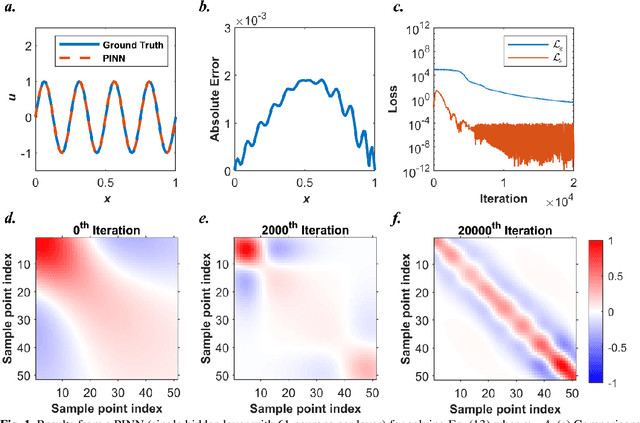
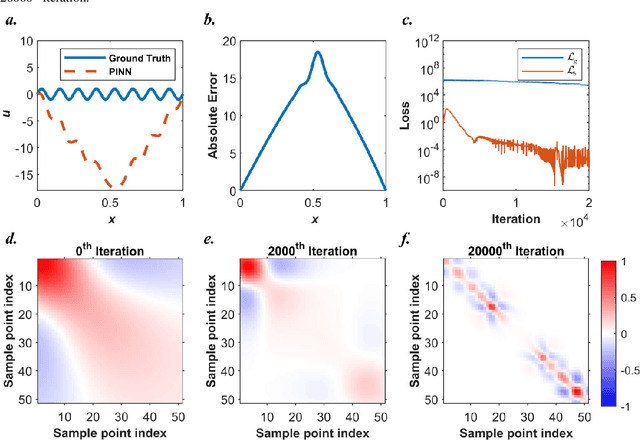
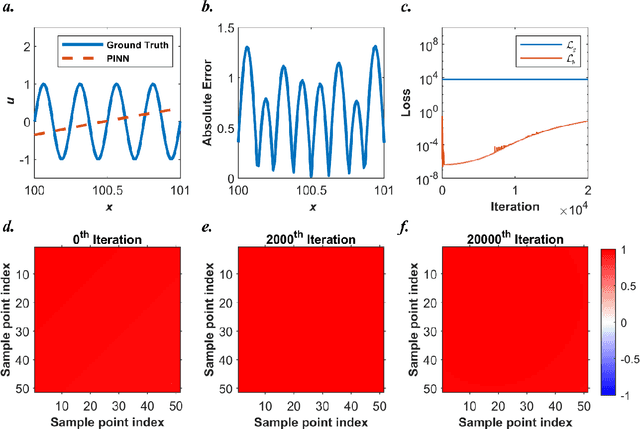
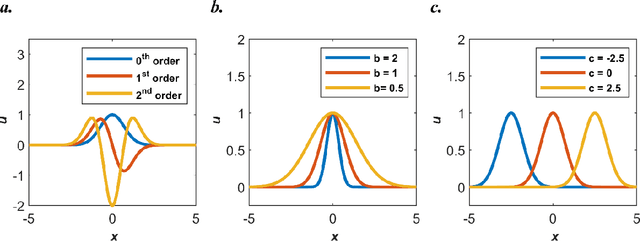
Our recent intensive study has found that physics-informed neural networks (PINN) tend to be local approximators after training. This observation leads to this novel physics-informed radial basis network (PIRBN), which can maintain the local property throughout the entire training process. Compared to deep neural networks, a PIRBN comprises of only one hidden layer and a radial basis "activation" function. Under appropriate conditions, we demonstrated that the training of PIRBNs using gradient descendent methods can converge to Gaussian processes. Besides, we studied the training dynamics of PIRBN via the neural tangent kernel (NTK) theory. In addition, comprehensive investigations regarding the initialisation strategies of PIRBN were conducted. Based on numerical examples, PIRBN has been demonstrated to be more effective and efficient than PINN in solving PDEs with high-frequency features and ill-posed computational domains. Moreover, the existing PINN numerical techniques, such as adaptive learning, decomposition and different types of loss functions, are applicable to PIRBN. The programs that can regenerate all numerical results can be found at https://github.com/JinshuaiBai/PIRBN.
Securing Federated Learning against Overwhelming Collusive Attackers
Sep 28, 2022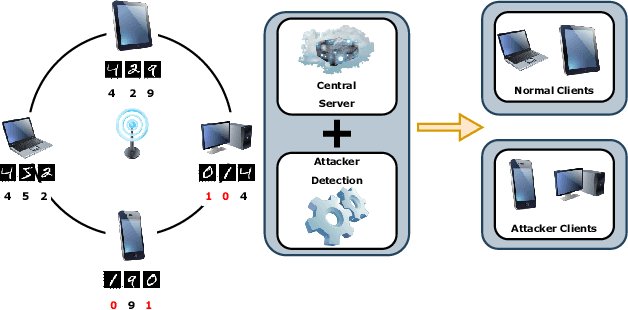
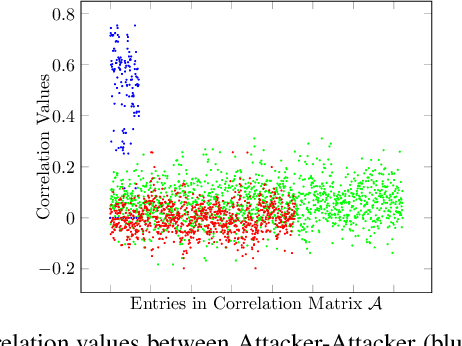
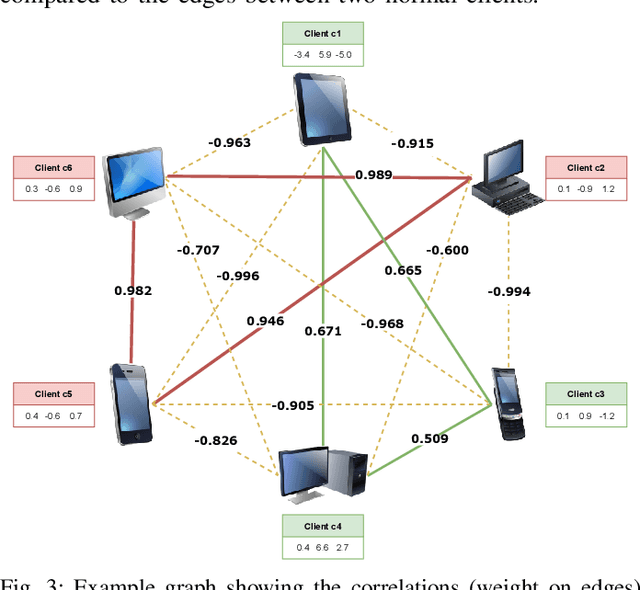
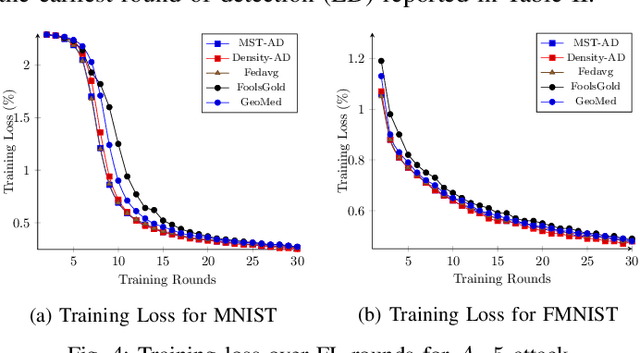
In the era of a data-driven society with the ubiquity of Internet of Things (IoT) devices storing large amounts of data localized at different places, distributed learning has gained a lot of traction, however, assuming independent and identically distributed data (iid) across the devices. While relaxing this assumption that anyway does not hold in reality due to the heterogeneous nature of devices, federated learning (FL) has emerged as a privacy-preserving solution to train a collaborative model over non-iid data distributed across a massive number of devices. However, the appearance of malicious devices (attackers), who intend to corrupt the FL model, is inevitable due to unrestricted participation. In this work, we aim to identify such attackers and mitigate their impact on the model, essentially under a setting of bidirectional label flipping attacks with collusion. We propose two graph theoretic algorithms, based on Minimum Spanning Tree and k-Densest graph, by leveraging correlations between local models. Our FL model can nullify the influence of attackers even when they are up to 70% of all the clients whereas prior works could not afford more than 50% of clients as attackers. The effectiveness of our algorithms is ascertained through experiments on two benchmark datasets, namely MNIST and Fashion-MNIST, with overwhelming attackers. We establish the superiority of our algorithms over the existing ones using accuracy, attack success rate, and early detection round.
FedAR+: A Federated Learning Approach to Appliance Recognition with Mislabeled Data in Residential Buildings
Sep 03, 2022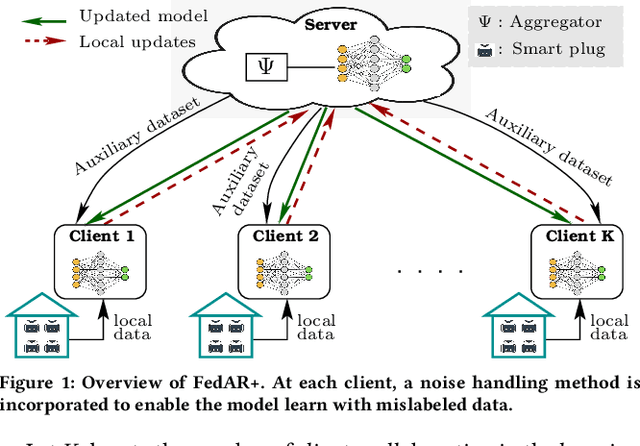
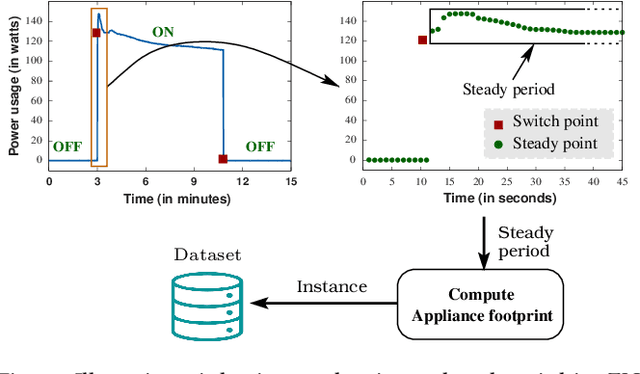
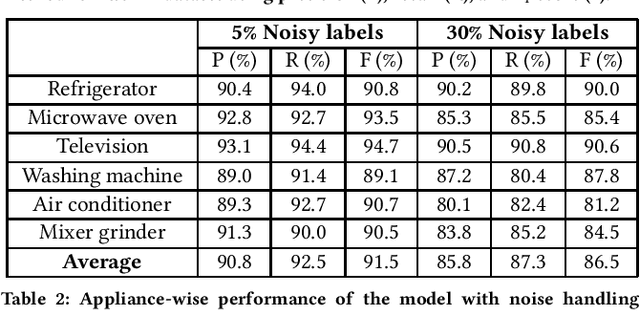
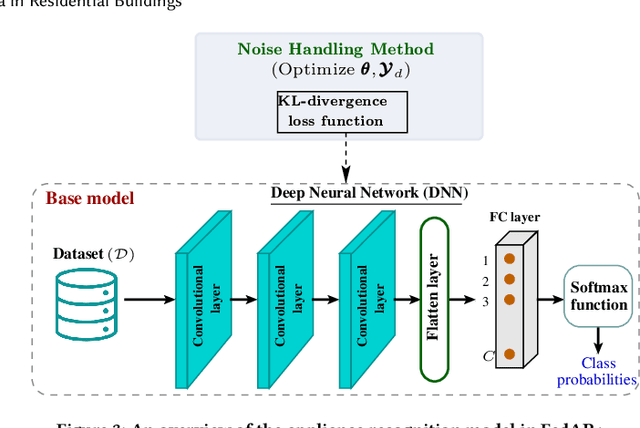
With the enhancement of people's living standards and rapid growth of communication technologies, residential environments are becoming smart and well-connected, increasing overall energy consumption substantially. As household appliances are the primary energy consumers, their recognition becomes crucial to avoid unattended usage, thereby conserving energy and making smart environments more sustainable. An appliance recognition model is traditionally trained at a central server (service provider) by collecting electricity consumption data, recorded via smart plugs, from the clients (consumers), causing a privacy breach. Besides that, the data are susceptible to noisy labels that may appear when an appliance gets connected to a non-designated smart plug. While addressing these issues jointly, we propose a novel federated learning approach to appliance recognition, called FedAR+, enabling decentralized model training across clients in a privacy preserving way even with mislabeled training data. FedAR+ introduces an adaptive noise handling method, essentially a joint loss function incorporating weights and label distribution, to empower the appliance recognition model against noisy labels. By deploying smart plugs in an apartment complex, we collect a labeled dataset that, along with two existing datasets, are utilized to evaluate the performance of FedAR+. Experimental results show that our approach can effectively handle up to $30\%$ concentration of noisy labels while outperforming the prior solutions by a large margin on accuracy.
A Novel Multi-Task Learning Approach for Context-Sensitive Compound Type Identification in Sanskrit
Aug 22, 2022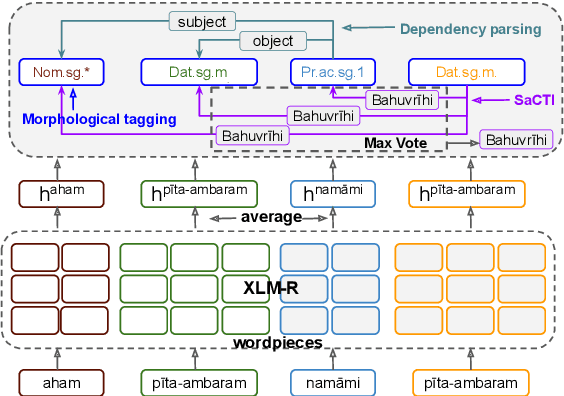
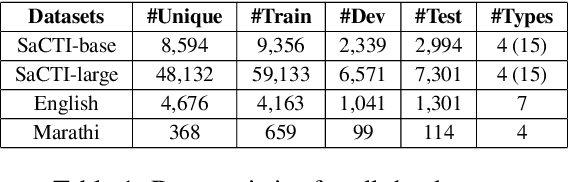
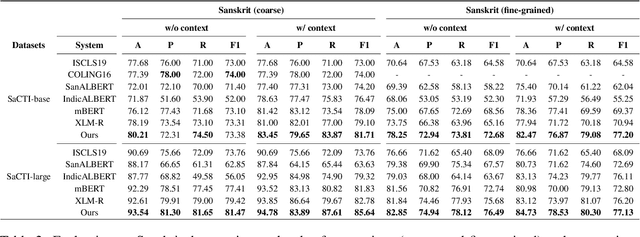
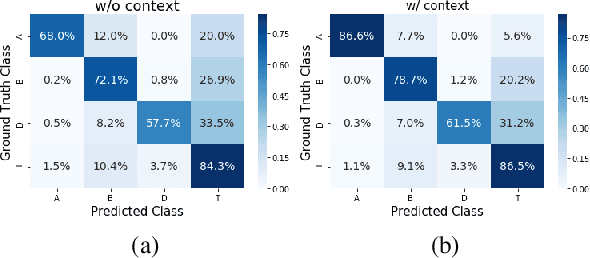
The phenomenon of compounding is ubiquitous in Sanskrit. It serves for achieving brevity in expressing thoughts, while simultaneously enriching the lexical and structural formation of the language. In this work, we focus on the Sanskrit Compound Type Identification (SaCTI) task, where we consider the problem of identifying semantic relations between the components of a compound word. Earlier approaches solely rely on the lexical information obtained from the components and ignore the most crucial contextual and syntactic information useful for SaCTI. However, the SaCTI task is challenging primarily due to the implicitly encoded context-sensitive semantic relation between the compound components. Thus, we propose a novel multi-task learning architecture which incorporates the contextual information and enriches the complementary syntactic information using morphological tagging and dependency parsing as two auxiliary tasks. Experiments on the benchmark datasets for SaCTI show 6.1 points (Accuracy) and 7.7 points (F1-score) absolute gain compared to the state-of-the-art system. Further, our multi-lingual experiments demonstrate the efficacy of the proposed architecture in English and Marathi languages.The code and datasets are publicly available at https://github.com/ashishgupta2598/SaCTI
Long-Short History of Gradients is All You Need: Detecting Malicious and Unreliable Clients in Federated Learning
Aug 14, 2022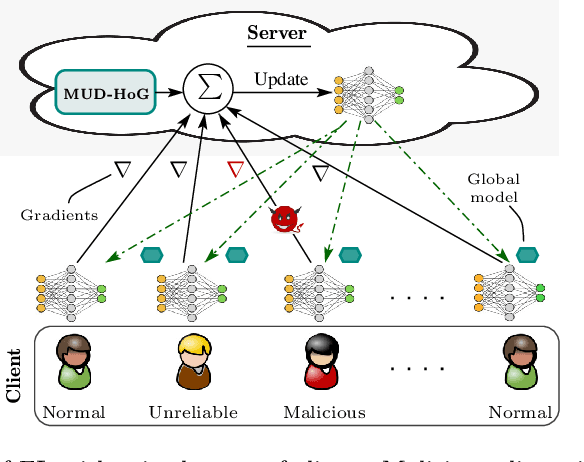
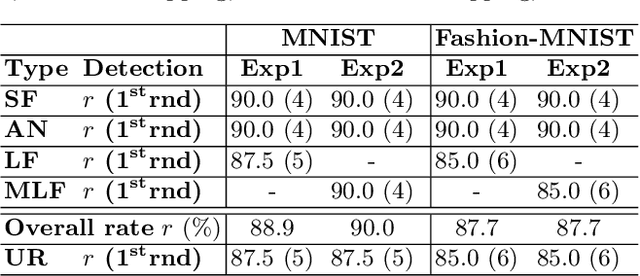
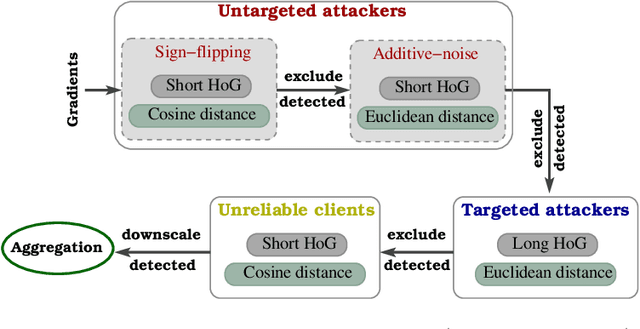
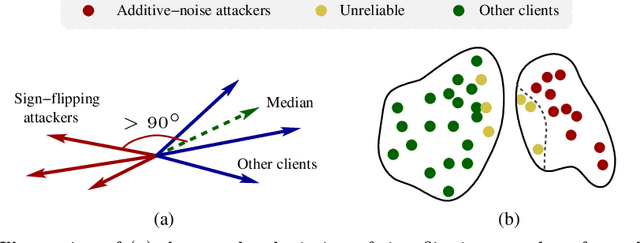
Federated learning offers a framework of training a machine learning model in a distributed fashion while preserving privacy of the participants. As the server cannot govern the clients' actions, nefarious clients may attack the global model by sending malicious local gradients. In the meantime, there could also be unreliable clients who are benign but each has a portion of low-quality training data (e.g., blur or low-resolution images), thus may appearing similar as malicious clients. Therefore, a defense mechanism will need to perform a three-fold differentiation which is much more challenging than the conventional (two-fold) case. This paper introduces MUD-HoG, a novel defense algorithm that addresses this challenge in federated learning using long-short history of gradients, and treats the detected malicious and unreliable clients differently. Not only this, but we can also distinguish between targeted and untargeted attacks among malicious clients, unlike most prior works which only consider one type of the attacks. Specifically, we take into account sign-flipping, additive-noise, label-flipping, and multi-label-flipping attacks, under a non-IID setting. We evaluate MUD-HoG with six state-of-the-art methods on two datasets. The results show that MUD-HoG outperforms all of them in terms of accuracy as well as precision and recall, in the presence of a mixture of multiple (four) types of attackers as well as unreliable clients. Moreover, unlike most prior works which can only tolerate a low population of harmful users, MUD-HoG can work with and successfully detect a wide range of malicious and unreliable clients - up to 47.5% and 10%, respectively, of the total population. Our code is open-sourced at https://github.com/LabSAINT/MUD-HoG_Federated_Learning.