 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning
Apr 08, 2025Continued advances in self-supervised learning have led to significant progress in video representation learning, offering a scalable alternative to supervised approaches by removing the need for manual annotations. Despite strong performance on standard action recognition benchmarks, video self-supervised learning methods are largely evaluated under narrow protocols, typically pretraining on Kinetics-400 and fine-tuning on similar datasets, limiting our understanding of their generalization in real world scenarios. In this work, we present a comprehensive evaluation of modern video self-supervised models, focusing on generalization across four key downstream factors: domain shift, sample efficiency, action granularity, and task diversity. Building on our prior work analyzing benchmark sensitivity in CNN-based contrastive learning, we extend the study to cover state-of-the-art transformer-based video-only and video-text models. Specifically, we benchmark 12 transformer-based methods (7 video-only, 5 video-text) and compare them to 10 CNN-based methods, totaling over 1100 experiments across 8 datasets and 7 downstream tasks. Our analysis shows that, despite architectural advances, transformer-based models remain sensitive to downstream conditions. No method generalizes consistently across all factors, video-only transformers perform better under domain shifts, CNNs outperform for fine-grained tasks, and video-text models often underperform despite large scale pretraining. We also find that recent transformer models do not consistently outperform earlier approaches. Our findings provide a detailed view of the strengths and limitations of current video SSL methods and offer a unified benchmark for evaluating generalization in video representation learning.
The Sound of Water: Inferring Physical Properties from Pouring Liquids
Nov 18, 2024We study the connection between audio-visual observations and the underlying physics of a mundane yet intriguing everyday activity: pouring liquids. Given only the sound of liquid pouring into a container, our objective is to automatically infer physical properties such as the liquid level, the shape and size of the container, the pouring rate and the time to fill. To this end, we: (i) show in theory that these properties can be determined from the fundamental frequency (pitch); (ii) train a pitch detection model with supervision from simulated data and visual data with a physics-inspired objective; (iii) introduce a new large dataset of real pouring videos for a systematic study; (iv) show that the trained model can indeed infer these physical properties for real data; and finally, (v) we demonstrate strong generalization to various container shapes, other datasets, and in-the-wild YouTube videos. Our work presents a keen understanding of a narrow yet rich problem at the intersection of acoustics, physics, and learning. It opens up applications to enhance multisensory perception in robotic pouring.
NurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
Test of Time: Instilling Video-Language Models with a Sense of Time
Jan 05, 2023Modeling and understanding time remains a challenge in contemporary video understanding models. With language emerging as a key driver towards powerful generalization, it is imperative for foundational video-language models to have a sense of time. In this paper, we consider a specific aspect of temporal understanding: consistency of time order as elicited by before/after relations. We establish that six existing video-language models struggle to understand even such simple temporal relations. We then question whether it is feasible to equip these foundational models with temporal awareness without re-training them from scratch. Towards this, we propose a temporal adaptation recipe on top of one such model, VideoCLIP, based on post-pretraining on a small amount of video-text data. We conduct a zero-shot evaluation of the adapted models on six datasets for three downstream tasks which require a varying degree of time awareness. We observe encouraging performance gains especially when the task needs higher time awareness. Our work serves as a first step towards probing and instilling a sense of time in existing video-language models without the need for data and compute-intense training from scratch.
How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?
Mar 27, 2022
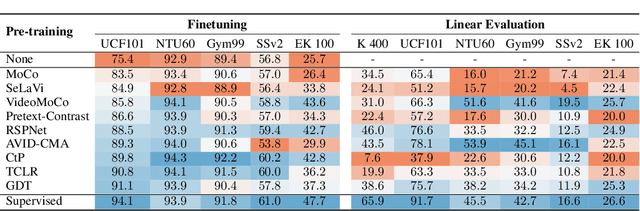
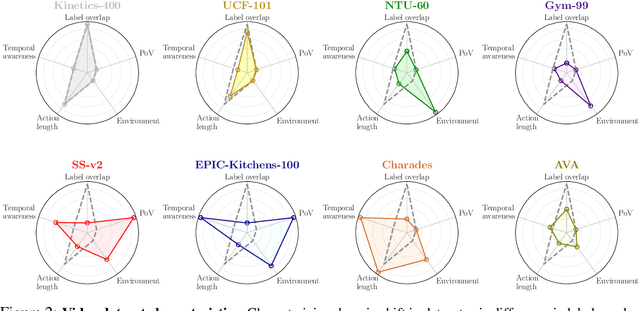
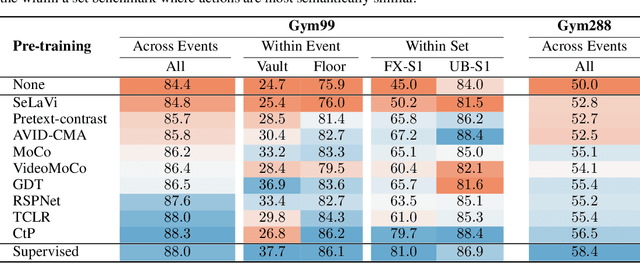
Despite the recent success of video self-supervised learning, there is much still to be understood about their generalization capability. In this paper, we investigate how sensitive video self-supervised learning is to the currently used benchmark convention and whether methods generalize beyond the canonical evaluation setting. We do this across four different factors of sensitivity: domain, samples, actions and task. Our comprehensive set of over 500 experiments, which encompasses 7 video datasets, 9 self-supervised methods and 6 video understanding tasks, reveals that current benchmarks in video self-supervised learning are not a good indicator of generalization along these sensitivity factors. Further, we find that self-supervised methods considerably lag behind vanilla supervised pre-training, especially when domain shift is large and the amount of available downstream samples are low. From our analysis we distill the SEVERE-benchmark, a subset of our experiments, and discuss its implication for evaluating the generalizability of representations obtained by existing and future self-supervised video learning methods.
Impact of data-splits on generalization: Identifying COVID-19 from cough and context
Jun 05, 2021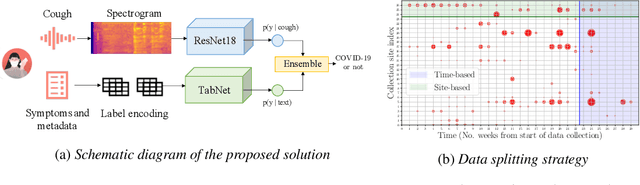

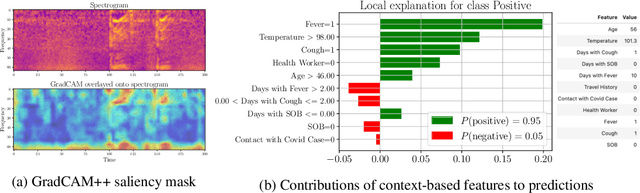
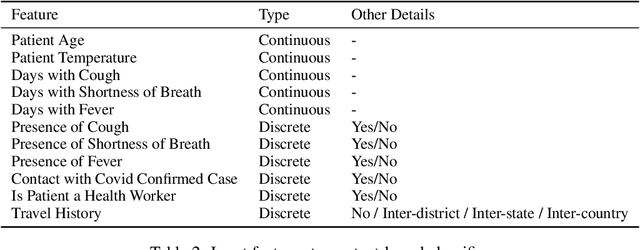
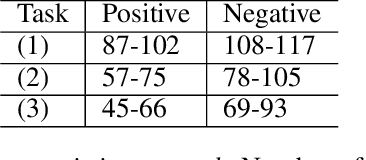
Rapidly scaling screening, testing and quarantine has shown to be an effective strategy to combat the COVID-19 pandemic. We consider the application of deep learning techniques to distinguish individuals with COVID from non-COVID by using data acquirable from a phone. Using cough and context (symptoms and meta-data) represent such a promising approach. Several independent works in this direction have shown promising results. However, none of them report performance across clinically relevant data splits. Specifically, the performance where the development and test sets are split in time (retrospective validation) and across sites (broad validation). Although there is meaningful generalization across these splits the performance significantly varies (up to 0.1 AUC score). In addition, we study the performance of symptomatic and asymptomatic individuals across these three splits. Finally, we show that our model focuses on meaningful features of the input, cough bouts for cough and relevant symptoms for context. The code and checkpoints are available at https://github.com/WadhwaniAI/cough-against-covid
Cough Against COVID: Evidence of COVID-19 Signature in Cough Sounds
Sep 23, 2020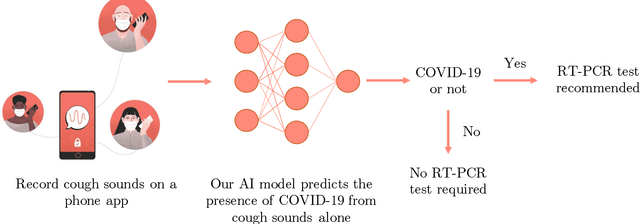


Testing capacity for COVID-19 remains a challenge globally due to the lack of adequate supplies, trained personnel, and sample-processing equipment. These problems are even more acute in rural and underdeveloped regions. We demonstrate that solicited-cough sounds collected over a phone, when analysed by our AI model, have statistically significant signal indicative of COVID-19 status (AUC 0.72, t-test,p <0.01,95% CI 0.61-0.83). This holds true for asymptomatic patients as well. Towards this, we collect the largest known(to date) dataset of microbiologically confirmed COVID-19 cough sounds from 3,621 individuals. When used in a triaging step within an overall testing protocol, by enabling risk-stratification of individuals before confirmatory tests, our tool can increase the testing capacity of a healthcare system by 43% at disease prevalence of 5%, without additional supplies, trained personnel, or physical infrastructure