 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLORO: A Multimodal Geospatial Foundation Model for Ecological Remote Sensing Across Sensors and Scales
May 27, 2026Foundation models offer a promising route to transferable remote sensing representations, but many current approaches depend on very large pretraining datasets and fixed sensor configurations, limiting their suitability for ecological and environmental applications, where observations often vary across platforms, spatial and spectral resolutions, and available modalities. We introduce FLORO, a multimodal geospatial foundation model designed to learn transferable representations from a small but highly diverse remote sensing corpus. FLORO is pretrained using masked autoencoding on a heterogeneous combination of Sentinel-1, Sentinel-2, SkySAT imagery, elevation, and UAV-derived data. To accommodate sensor variability, FLORO incorporates availability-aware inputs that indicate which spectral bands and auxiliary modalities are present in each sample, enabling a unified input space across heterogeneous sensor configurations. We evaluated FLORO on the PANGAEA benchmark under a frozen-encoder protocol across scene classification, segmentation, and regression tasks. Despite being pretrained on a smaller corpus than competing foundation models, FLORO achieved strong and stable transfer across optical, optical-SAR, and optical-elevation benchmarks spanning medium-resolution satellite, airborne, and ultra-high-resolution UAV imagery. FLORO obtained the second-best average segmentation performance across six PANGAEA benchmarks, trailing only a recently introduced foundation model pretrained on over two orders of magnitude more images, remained competitive on scene classification, and was robust in regression tasks, while qualitative results showed improved preservation of spatial structure in flood, urban, biomass, and canopy-height prediction settings. In a separate controlled experiment on EuroSAT-MS, geo-positional encoding further improved classification relative to absolute positional encoding.
TrackMAE: Video Representation Learning via Track Mask and Predict
Mar 28, 2026Masked video modeling (MVM) has emerged as a simple and scalable self-supervised pretraining paradigm, but only encodes motion information implicitly, limiting the encoding of temporal dynamics in the learned representations. As a result, such models struggle on motion-centric tasks that require fine-grained motion awareness. To address this, we propose TrackMAE, a simple masked video modeling paradigm that explicitly uses motion information as a reconstruction signal. In TrackMAE, we use an off-the-shelf point tracker to sparsely track points in the input videos, generating motion trajectories. Furthermore, we exploit the extracted trajectories to improve random tube masking with a motion-aware masking strategy. We enhance video representations learned in both pixel and feature semantic reconstruction spaces by providing a complementary supervision signal in the form of motion targets. We evaluate on six datasets across diverse downstream settings and find that TrackMAE consistently outperforms state-of-the-art video self-supervised learning baselines, learning more discriminative and generalizable representations. Code available at https://github.com/rvandeghen/TrackMAE
SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning
Apr 08, 2025Continued advances in self-supervised learning have led to significant progress in video representation learning, offering a scalable alternative to supervised approaches by removing the need for manual annotations. Despite strong performance on standard action recognition benchmarks, video self-supervised learning methods are largely evaluated under narrow protocols, typically pretraining on Kinetics-400 and fine-tuning on similar datasets, limiting our understanding of their generalization in real world scenarios. In this work, we present a comprehensive evaluation of modern video self-supervised models, focusing on generalization across four key downstream factors: domain shift, sample efficiency, action granularity, and task diversity. Building on our prior work analyzing benchmark sensitivity in CNN-based contrastive learning, we extend the study to cover state-of-the-art transformer-based video-only and video-text models. Specifically, we benchmark 12 transformer-based methods (7 video-only, 5 video-text) and compare them to 10 CNN-based methods, totaling over 1100 experiments across 8 datasets and 7 downstream tasks. Our analysis shows that, despite architectural advances, transformer-based models remain sensitive to downstream conditions. No method generalizes consistently across all factors, video-only transformers perform better under domain shifts, CNNs outperform for fine-grained tasks, and video-text models often underperform despite large scale pretraining. We also find that recent transformer models do not consistently outperform earlier approaches. Our findings provide a detailed view of the strengths and limitations of current video SSL methods and offer a unified benchmark for evaluating generalization in video representation learning.
SMILE: Infusing Spatial and Motion Semantics in Masked Video Learning
Apr 01, 2025Masked video modeling, such as VideoMAE, is an effective paradigm for video self-supervised learning (SSL). However, they are primarily based on reconstructing pixel-level details on natural videos which have substantial temporal redundancy, limiting their capability for semantic representation and sufficient encoding of motion dynamics. To address these issues, this paper introduces a novel SSL approach for video representation learning, dubbed as SMILE, by infusing both spatial and motion semantics. In SMILE, we leverage image-language pretrained models, such as CLIP, to guide the learning process with their high-level spatial semantics. We enhance the representation of motion by introducing synthetic motion patterns in the training data, allowing the model to capture more complex and dynamic content. Furthermore, using SMILE, we establish a new self-supervised video learning paradigm capable of learning strong video representations without requiring any natural video data. We have carried out extensive experiments on 7 datasets with various downstream scenarios. SMILE surpasses current state-of-the-art SSL methods, showcasing its effectiveness in learning more discriminative and generalizable video representations. Code is available: https://github.com/fmthoker/SMILE
Structured-Noise Masked Modeling for Video, Audio and Beyond
Mar 20, 2025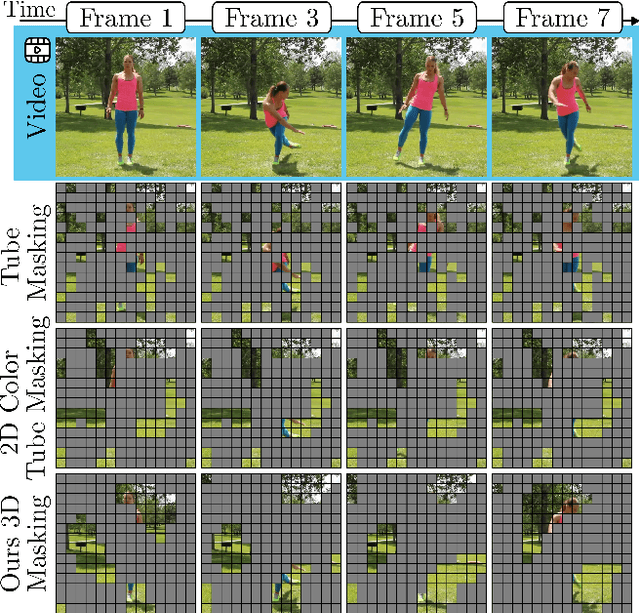
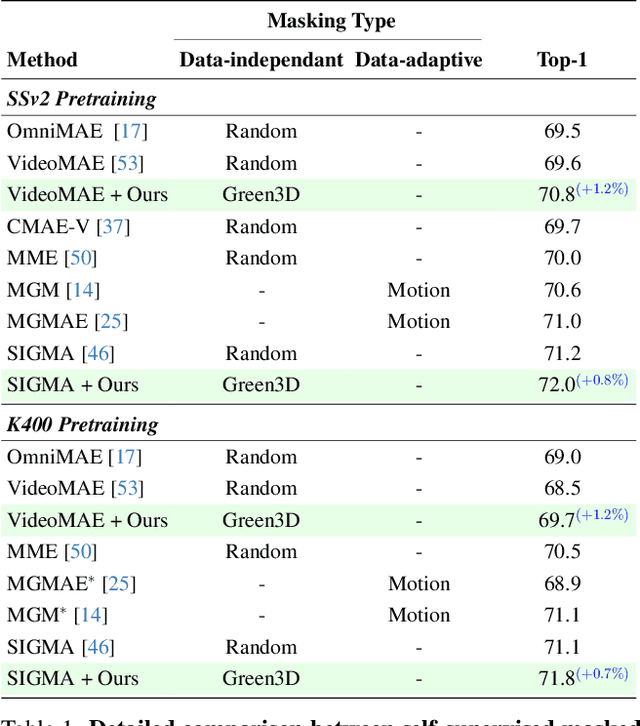
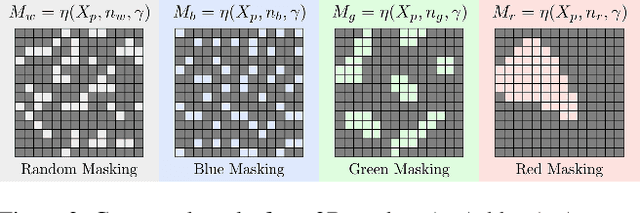

Masked modeling has emerged as a powerful self-supervised learning framework, but existing methods largely rely on random masking, disregarding the structural properties of different modalities. In this work, we introduce structured noise-based masking, a simple yet effective approach that naturally aligns with the spatial, temporal, and spectral characteristics of video and audio data. By filtering white noise into distinct color noise distributions, we generate structured masks that preserve modality-specific patterns without requiring handcrafted heuristics or access to the data. Our approach improves the performance of masked video and audio modeling frameworks without any computational overhead. Extensive experiments demonstrate that structured noise masking achieves consistent improvement over random masking for standard and advanced masked modeling methods, highlighting the importance of modality-aware masking strategies for representation learning.
LocoMotion: Learning Motion-Focused Video-Language Representations
Oct 15, 2024



This paper strives for motion-focused video-language representations. Existing methods to learn video-language representations use spatial-focused data, where identifying the objects and scene is often enough to distinguish the relevant caption. We instead propose LocoMotion to learn from motion-focused captions that describe the movement and temporal progression of local object motions. We achieve this by adding synthetic motions to videos and using the parameters of these motions to generate corresponding captions. Furthermore, we propose verb-variation paraphrasing to increase the caption variety and learn the link between primitive motions and high-level verbs. With this, we are able to learn a motion-focused video-language representation. Experiments demonstrate our approach is effective for a variety of downstream tasks, particularly when limited data is available for fine-tuning. Code is available: https://hazeldoughty.github.io/Papers/LocoMotion/
SIGMA: Sinkhorn-Guided Masked Video Modeling
Jul 22, 2024



Video-based pretraining offers immense potential for learning strong visual representations on an unprecedented scale. Recently, masked video modeling methods have shown promising scalability, yet fall short in capturing higher-level semantics due to reconstructing predefined low-level targets such as pixels. To tackle this, we present Sinkhorn-guided Masked Video Modelling (SIGMA), a novel video pretraining method that jointly learns the video model in addition to a target feature space using a projection network. However, this simple modification means that the regular L2 reconstruction loss will lead to trivial solutions as both networks are jointly optimized. As a solution, we distribute features of space-time tubes evenly across a limited number of learnable clusters. By posing this as an optimal transport problem, we enforce high entropy in the generated features across the batch, infusing semantic and temporal meaning into the feature space. The resulting cluster assignments are used as targets for a symmetric prediction task where the video model predicts cluster assignment of the projection network and vice versa. Experimental results on ten datasets across three benchmarks validate the effectiveness of SIGMA in learning more performant, temporally-aware, and robust video representations improving upon state-of-the-art methods. Our project website with code is available at: https://quva-lab.github.io/SIGMA.
Tubelet-Contrastive Self-Supervision for Video-Efficient Generalization
Mar 20, 2023
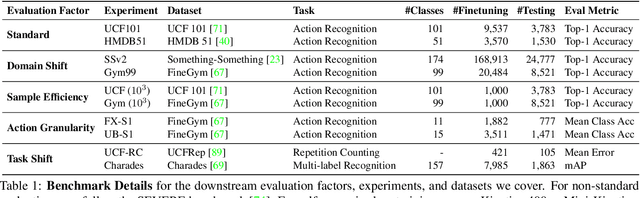
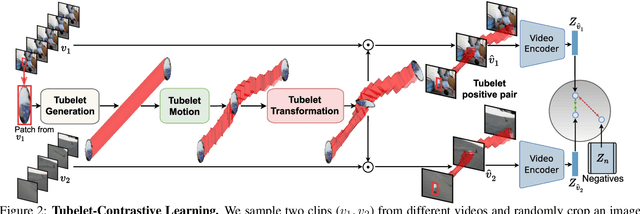
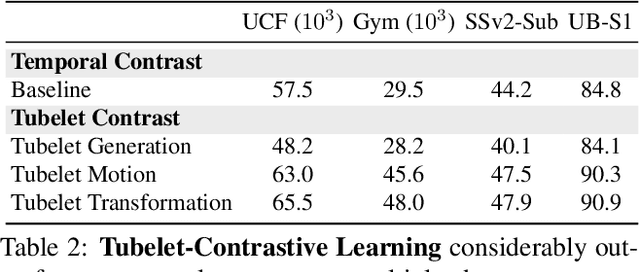
We propose a self-supervised method for learning motion-focused video representations. Existing approaches minimize distances between temporally augmented videos, which maintain high spatial similarity. We instead propose to learn similarities between videos with identical local motion dynamics but an otherwise different appearance. We do so by adding synthetic motion trajectories to videos which we refer to as tubelets. By simulating different tubelet motions and applying transformations, such as scaling and rotation, we introduce motion patterns beyond what is present in the pretraining data. This allows us to learn a video representation that is remarkably data-efficient: our approach maintains performance when using only 25% of the pretraining videos. Experiments on 10 diverse downstream settings demonstrate our competitive performance and generalizability to new domains and fine-grained actions.
How Severe is Benchmark-Sensitivity in Video Self-Supervised Learning?
Mar 27, 2022
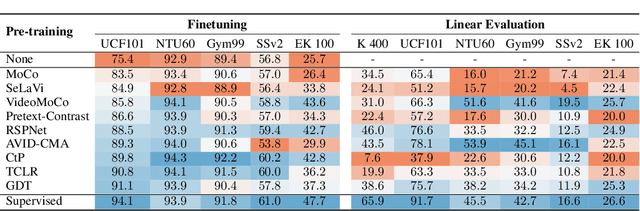
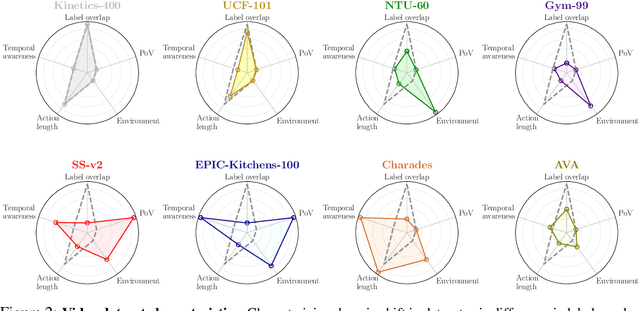
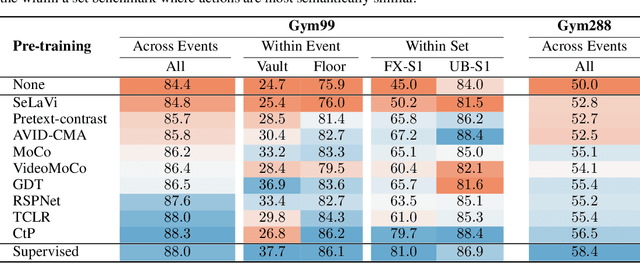
Despite the recent success of video self-supervised learning, there is much still to be understood about their generalization capability. In this paper, we investigate how sensitive video self-supervised learning is to the currently used benchmark convention and whether methods generalize beyond the canonical evaluation setting. We do this across four different factors of sensitivity: domain, samples, actions and task. Our comprehensive set of over 500 experiments, which encompasses 7 video datasets, 9 self-supervised methods and 6 video understanding tasks, reveals that current benchmarks in video self-supervised learning are not a good indicator of generalization along these sensitivity factors. Further, we find that self-supervised methods considerably lag behind vanilla supervised pre-training, especially when domain shift is large and the amount of available downstream samples are low. From our analysis we distill the SEVERE-benchmark, a subset of our experiments, and discuss its implication for evaluating the generalizability of representations obtained by existing and future self-supervised video learning methods.
Skeleton-Contrastive 3D Action Representation Learning
Aug 08, 2021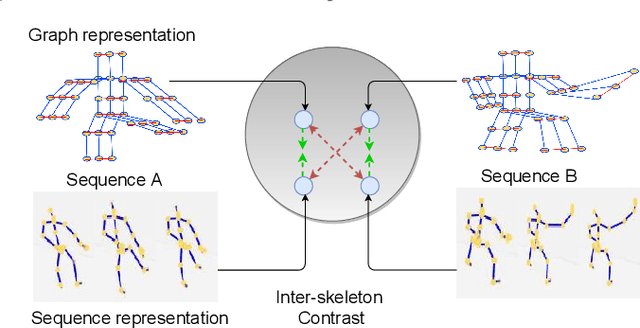
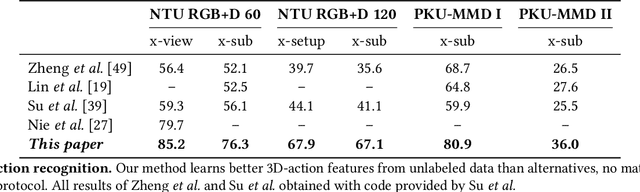
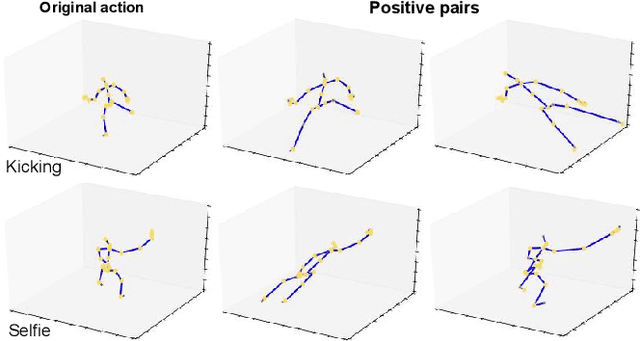
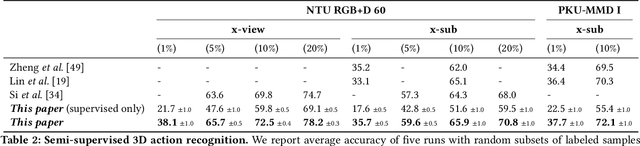
This paper strives for self-supervised learning of a feature space suitable for skeleton-based action recognition. Our proposal is built upon learning invariances to input skeleton representations and various skeleton augmentations via a noise contrastive estimation. In particular, we propose inter-skeleton contrastive learning, which learns from multiple different input skeleton representations in a cross-contrastive manner. In addition, we contribute several skeleton-specific spatial and temporal augmentations which further encourage the model to learn the spatio-temporal dynamics of skeleton data. By learning similarities between different skeleton representations as well as augmented views of the same sequence, the network is encouraged to learn higher-level semantics of the skeleton data than when only using the augmented views. Our approach achieves state-of-the-art performance for self-supervised learning from skeleton data on the challenging PKU and NTU datasets with multiple downstream tasks, including action recognition, action retrieval and semi-supervised learning. Code is available at https://github.com/fmthoker/skeleton-contrast.