 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Apr 02, 2026We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
RedSage: A Cybersecurity Generalist LLM
Jan 29, 2026Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
LC-SLab -- An Object-based Deep Learning Framework for Large-scale Land Cover Classification from Satellite Imagery and Sparse In-situ Labels
Sep 19, 2025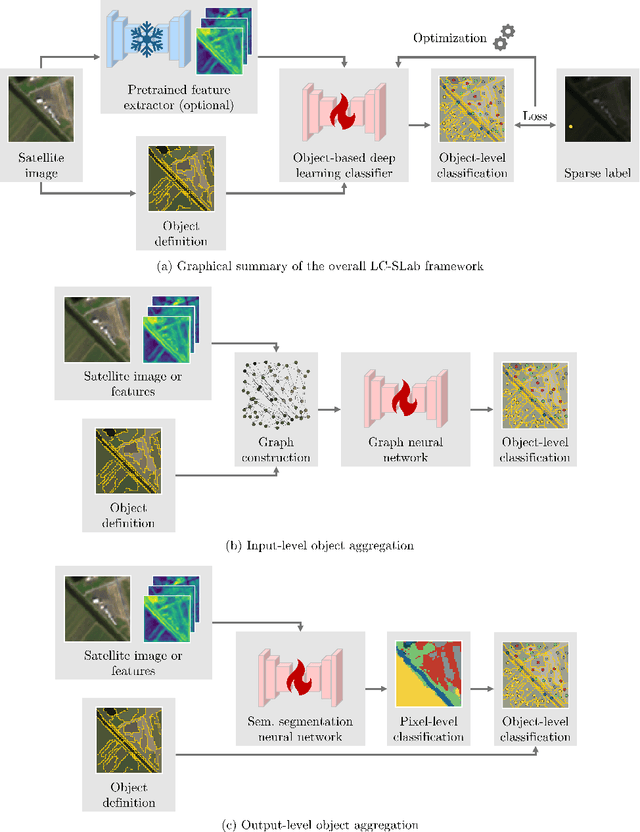
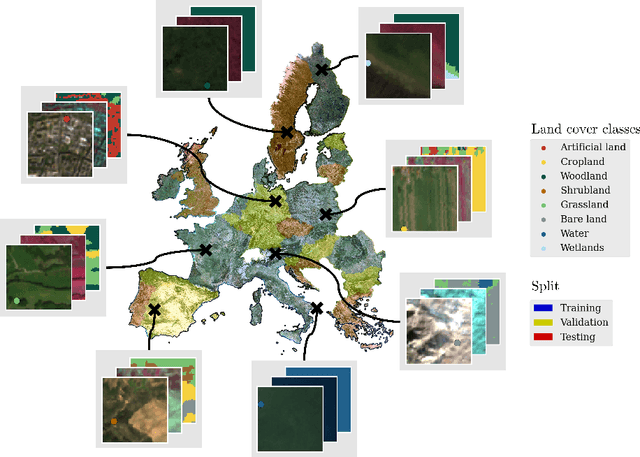
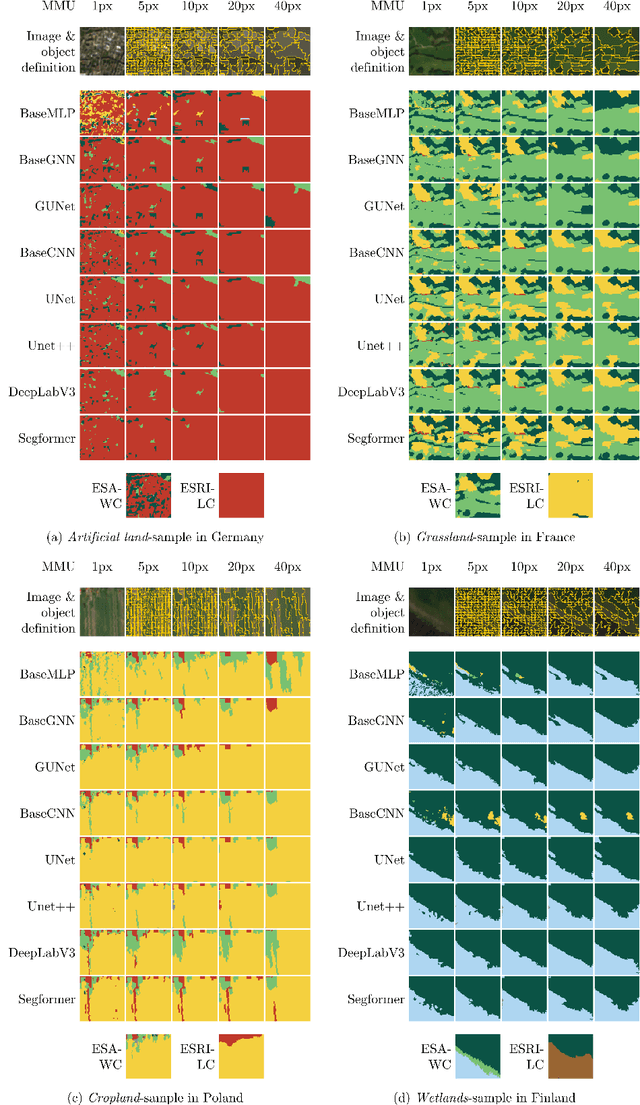
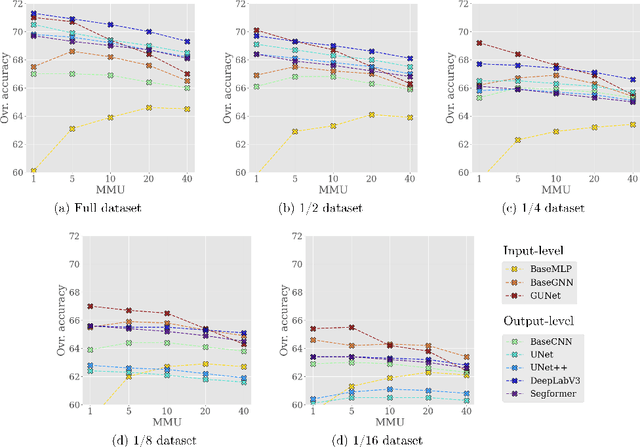
Large-scale land cover maps generated using deep learning play a critical role across a wide range of Earth science applications. Open in-situ datasets from principled land cover surveys offer a scalable alternative to manual annotation for training such models. However, their sparse spatial coverage often leads to fragmented and noisy predictions when used with existing deep learning-based land cover mapping approaches. A promising direction to address this issue is object-based classification, which assigns labels to semantically coherent image regions rather than individual pixels, thereby imposing a minimum mapping unit. Despite this potential, object-based methods remain underexplored in deep learning-based land cover mapping pipelines, especially in the context of medium-resolution imagery and sparse supervision. To address this gap, we propose LC-SLab, the first deep learning framework for systematically exploring object-based deep learning methods for large-scale land cover classification under sparse supervision. LC-SLab supports both input-level aggregation via graph neural networks, and output-level aggregation by postprocessing results from established semantic segmentation models. Additionally, we incorporate features from a large pre-trained network to improve performance on small datasets. We evaluate the framework on annual Sentinel-2 composites with sparse LUCAS labels, focusing on the tradeoff between accuracy and fragmentation, as well as sensitivity to dataset size. Our results show that object-based methods can match or exceed the accuracy of common pixel-wise models while producing substantially more coherent maps. Input-level aggregation proves more robust on smaller datasets, whereas output-level aggregation performs best with more data. Several configurations of LC-SLab also outperform existing land cover products, highlighting the framework's practical utility.
Enhancing Video-Based Robot Failure Detection Using Task Knowledge
Aug 26, 2025Robust robotic task execution hinges on the reliable detection of execution failures in order to trigger safe operation modes, recovery strategies, or task replanning. However, many failure detection methods struggle to provide meaningful performance when applied to a variety of real-world scenarios. In this paper, we propose a video-based failure detection approach that uses spatio-temporal knowledge in the form of the actions the robot performs and task-relevant objects within the field of view. Both pieces of information are available in most robotic scenarios and can thus be readily obtained. We demonstrate the effectiveness of our approach on three datasets that we amend, in part, with additional annotations of the aforementioned task-relevant knowledge. In light of the results, we also propose a data augmentation method that improves performance by applying variable frame rates to different parts of the video. We observe an improvement from 77.9 to 80.0 in F1 score on the ARMBench dataset without additional computational expense and an additional increase to 81.4 with test-time augmentation. The results emphasize the importance of spatio-temporal information during failure detection and suggest further investigation of suitable heuristics in future implementations. Code and annotations are available.
Looking into the Unknown: Exploring Action Discovery for Segmentation of Known and Unknown Actions
Aug 07, 2025We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.
Skeleton Motion Words for Unsupervised Skeleton-Based Temporal Action Segmentation
Aug 06, 2025



Current state-of-the-art methods for skeleton-based temporal action segmentation are predominantly supervised and require annotated data, which is expensive to collect. In contrast, existing unsupervised temporal action segmentation methods have focused primarily on video data, while skeleton sequences remain underexplored, despite their relevance to real-world applications, robustness, and privacy-preserving nature. In this paper, we propose a novel approach for unsupervised skeleton-based temporal action segmentation. Our method utilizes a sequence-to-sequence temporal autoencoder that keeps the information of the different joints disentangled in the embedding space. Latent skeleton sequences are then divided into non-overlapping patches and quantized to obtain distinctive skeleton motion words, driving the discovery of semantically meaningful action clusters. We thoroughly evaluate the proposed approach on three widely used skeleton-based datasets, namely HuGaDB, LARa, and BABEL. The results demonstrate that our model outperforms the current state-of-the-art unsupervised temporal action segmentation methods. Code is available at https://github.com/bachlab/SMQ .
RiverMamba: A State Space Model for Global River Discharge and Flood Forecasting
May 29, 2025



Recent deep learning approaches for river discharge forecasting have improved the accuracy and efficiency in flood forecasting, enabling more reliable early warning systems for risk management. Nevertheless, existing deep learning approaches in hydrology remain largely confined to local-scale applications and do not leverage the inherent spatial connections of bodies of water. Thus, there is a strong need for new deep learning methodologies that are capable of modeling spatio-temporal relations to improve river discharge and flood forecasting for scientific and operational applications. To address this, we present RiverMamba, a novel deep learning model that is pretrained with long-term reanalysis data and that can forecast global river discharge and floods on a $0.05^\circ$ grid up to 7 days lead time, which is of high relevance in early warning. To achieve this, RiverMamba leverages efficient Mamba blocks that enable the model to capture global-scale channel network routing and enhance its forecast capability for longer lead times. The forecast blocks integrate ECMWF HRES meteorological forecasts, while accounting for their inaccuracies through spatio-temporal modeling. Our analysis demonstrates that RiverMamba delivers reliable predictions of river discharge, including extreme floods across return periods and lead times, surpassing both operational AI- and physics-based models.
CamContextI2V: Context-aware Controllable Video Generation
Apr 08, 2025Recently, image-to-video (I2V) diffusion models have demonstrated impressive scene understanding and generative quality, incorporating image conditions to guide generation. However, these models primarily animate static images without extending beyond their provided context. Introducing additional constraints, such as camera trajectories, can enhance diversity but often degrades visual quality, limiting their applicability for tasks requiring faithful scene representation. We propose CamContextI2V, an I2V model that integrates multiple image conditions with 3D constraints alongside camera control to enrich both global semantics and fine-grained visual details. This enables more coherent and context-aware video generation. Moreover, we motivate the necessity of temporal awareness for an effective context representation. Our comprehensive study on the RealEstate10K dataset demonstrates improvements in visual quality and camera controllability. We make our code and models publicly available at: https://github.com/LDenninger/CamContextI2V.
TQD-Track: Temporal Query Denoising for 3D Multi-Object Tracking
Apr 04, 2025Query denoising has become a standard training strategy for DETR-based detectors by addressing the slow convergence issue. Besides that, query denoising can be used to increase the diversity of training samples for modeling complex scenarios which is critical for Multi-Object Tracking (MOT), showing its potential in MOT application. Existing approaches integrate query denoising within the tracking-by-attention paradigm. However, as the denoising process only happens within the single frame, it cannot benefit the tracker to learn temporal-related information. In addition, the attention mask in query denoising prevents information exchange between denoising and object queries, limiting its potential in improving association using self-attention. To address these issues, we propose TQD-Track, which introduces Temporal Query Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal information and instance-specific feature representation. We introduce diverse noise types onto denoising queries that simulate real-world challenges in MOT. We analyze our proposed TQD for different tracking paradigms, and find out the paradigm with explicit learned data association module, e.g. tracking-by-detection or alternating detection and association, benefit from TQD by a larger margin. For these paradigms, we further design an association mask in the association module to ensure the consistent interaction between track and detection queries as during inference. Extensive experiments on the nuScenes dataset demonstrate that our approach consistently enhances different tracking methods by only changing the training process, especially the paradigms with explicit association module.
STING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.