 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Aware Monocular Semantic Scene Completion with State Space Models
Paper and Code
Mar 09, 2025


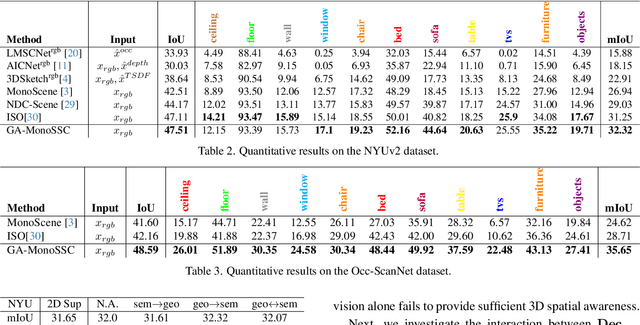
Monocular Semantic Scene Completion (MonoSSC) reconstructs and interprets 3D environments from a single image, enabling diverse real-world applications. However, existing methods are often constrained by the local receptive field of Convolutional Neural Networks (CNNs), making it challenging to handle the non-uniform distribution of projected points (Fig. \ref{fig:perspective}) and effectively reconstruct missing information caused by the 3D-to-2D projection. In this work, we introduce GA-MonoSSC, a hybrid architecture for MonoSSC that effectively captures global context in both the 2D image domain and 3D space. Specifically, we propose a Dual-Head Multi-Modality Encoder, which leverages a Transformer architecture to capture spatial relationships across all features in the 2D image domain, enabling more comprehensive 2D feature extraction. Additionally, we introduce the Frustum Mamba Decoder, built on the State Space Model (SSM), to efficiently capture long-range dependencies in 3D space. Furthermore, we propose a frustum reordering strategy within the Frustum Mamba Decoder to mitigate feature discontinuities in the reordered voxel sequence, ensuring better alignment with the scan mechanism of the State Space Model (SSM) for improved 3D representation learning. We conduct extensive experiments on the widely used Occ-ScanNet and NYUv2 datasets, demonstrating that our proposed method achieves state-of-the-art performance, validating its effectiveness. The code will be released upon acceptance.