 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Detectability in 3DGS Poisoning: A Stage-wise Benchmark
Jun 02, 20263D Gaussian Splatting (3DGS) has rapidly emerged as a leading representation for real-time novel view synthesis, but recent work shows it is vulnerable to diverse poisoning attacks, including illusory object injection, computation cost amplification, and post hoc model watermarking. Despite this expanding threat surface, existing studies focus mainly on attack success, while defense and detection remain underexplored. From a detection perspective, a key challenge and opportunity arise from the multi-stage nature of the 3DGS reconstruction pipeline, which produces heterogeneous intermediate representations. Forensic signals for detecting poisoning are inherently stage dependent: an attack introduced at one stage may produce signals that emerge only at later stages. This motivates a stage-wise view of detectability that goes beyond single-stage evaluation. We introduce Poison-3DGS, a benchmark for stage-wise characterization of poisoning detection in 3DGS. It exposes stage-specific artifacts, including multi-view images, geometry, training dynamics, and Gaussian parameters, across a diverse set of scenes and attacks. Using it, we conduct a systematic study of detectability across pipeline stages. Our analysis reveals several insights. First, detectability varies significantly across stages, and no single stage consistently dominates across attack types. Second, different attacks exhibit distinct stage-specific forensic signals, so detection effectiveness depends critically on where signals are observed. Third, later-stage signals such as training dynamics and Gaussian parameter statistics provide strong cues not observable at earlier stages. Overall, our work provides a principled benchmark and the first systematic characterization of stage-dependent detectability in 3DGS, offering a foundation for future research on robust and reliable 3DGS systems.
Ego2World: Compiling Egocentric Cooking Videos into Executable Worlds for Belief-State Planning
May 13, 2026Embodied agents in household environments must plan under partial observation: they need to remember objects, track state changes, and recover when actions fail. Existing benchmarks only partially test this ability. Egocentric video datasets capture realistic human activities but remain passive, while interactive simulators support execution but rely on synthetic scenes and hand-crafted dynamics, introducing a sim-to-real gap and often assuming fully observable state. We introduce Ego2World, an executable benchmark that turns egocentric cooking videos into executable symbolic worlds governed by graph-transition rules. Built on HD-EPIC, Ego2World derives reusable transition rules from video annotations and executes them in a hidden symbolic world graph. During evaluation, the simulator maintains the hidden world graph, while the agent plans over its own partial belief graph using only local observations and execution feedback. This separation forces agents to update memory and replan without observing the true world state. Experiments show that action-overlap scores overestimate physical-state success, and that persistent belief memory improves task completion while reducing repeated visual exploration -- suggesting that belief maintenance should be a first-class target of embodied-agent evaluation.
PRISM: : Planning and Reasoning with Intent in Simulated Embodied Environments
May 12, 2026When an LLM-based embodied agent fails at a household task, the culprit could be misidentified objects, forgotten sub-goals, or poor action sequencing -- yet existing benchmarks report only a single success rate, making it impossible to tell which cognitive module is responsible. We present PRISM, a diagnostic benchmark that reframes this problem: rather than asking only \textit{did the agent succeed?}, PRISM asks \textit{which capability is most likely responsible for failure?} Built on five photorealistic multi-room apartments (4--8 rooms each), PRISM structures 300 human-verified tasks into three capability tiers -- \textit{Basic Ability}, \textit{Reasoning Ability}, and \textit{Long-horizon Ability} -- that isolate perception-to-action grounding, implicit intent resolution, and sustained multi-step coordination respectively. PRISM exposes an agent-agnostic executable action API that allows arbitrary agents: LLM agents, VLM agents, symbolic planners, RL policies, and hybrid systems, to be evaluated end-to-end under the same benchmark protocol. To support deeper diagnosis, optional probes for perception, memory, and planning can be adopted, replaced, or bypassed entirely, enabling controlled component-level analysis when desired. Experiments on seven contemporary LLMs establish a clear hierarchy: explicit spatial grounding is not the dominant failure source under oracle perception, implicit intent resolution is a significant bottleneck for all model families, and long-horizon coordination exposes a stark capability cliff -- lightweight models collapse to as low as 20.0\% success while simultaneously consuming more tokens than their frontier counterparts, a signature of compensatory over-reasoning rather than genuine planning capability. Project page: \href{https://sj-li.com/PROJ/PRISM}{link}.
Grounding by Remembering: Cross-Scene and In-Scene Memory for 3D Functional Affordances
May 12, 2026Functional affordance grounding requires more than recognizing an object: an agent must localize the specific region that supports an interaction, such as the handle to pull or the button to press. This is difficult for training-free vision-language pipelines because actionable regions are often small, visually ambiguous, and repeated across multiple same-category instances in a scene. We propose AFFORDMEM, a framework that grounds 3D functional affordances by remembering geometry at two levels. The first is cross-scene affordance memory: the agent maintains a category-level memory bank of RGB images with affordance regions rendered as overlays, and recalls the most informative examples at query time to guide a frozen VLM toward small operable subregions that text-only prompting consistently misses. The second is in-scene spatial memory: as the agent processes the scene, it organizes candidate instances and their 3D spatial relations into a structured scene graph, enabling the language model to resolve references over distant or currently unobserved candidates such as "the second handle from the top." AFFORDMEM requires no model fine-tuning and no target-scene annotation, using a reusable memory bank built from source scenes. On SceneFun3D, our method improves AP50 over the prior training-free state of the art by 3.23 on Split 0 and 3.7 on Split 1. Ablation studies support complementary benefits: cross-scene affordance memory improves fine-grained localization, while in-scene spatial memory provides the larger gain on spatially qualified queries. The project homepage is available at the project page.
Compress Then Adapt? No, Do It Together via Task-aware Union of Subspaces
May 04, 2026Adapting large pretrained models to diverse tasks is now routine, yet the two dominant strategies of parameter-efficient fine-tuning (PEFT) and low-rank compression are typically composed in sequence. This decoupled practice first compresses and then fine-tunes adapters, potentially misaligning the compressed subspace with downstream objectives and squandering a global parameter budget. To overcome this limitation, we introduce JACTUS (Joint Adaptation and Compression with a Task-aware Union of Subspaces), a single framework that unifies compression and adaptation. From a small calibration set, JACTUS estimates input and pre-activation gradient covariances, forms their orthogonal union with the pretrained weight subspace, performs a projected low-rank approximation inside this union, allocates rank globally by marginal gain per parameter, and trains only a compact core matrix. This explicitly mitigates the potential misalignment between the compressed subspace and downstream objectives by coupling the directions preserved for compression with those required for adaptation, yielding a deployable low-rank model that avoids retaining full frozen weights while enabling fast and robust tuning. On vision, JACTUS attains an average 89.2% accuracy on ViT-Base across eight datasets at 80% retained parameters, surpassing strong 100% PEFT baselines (e.g., DoRA 87.9%). On language, JACTUS achieves an 80.9% average on Llama2-7B commonsense QA at the same 80% retained-parameter budget, outperforming 100% PEFT (e.g., DoRA 79.7%) and exceeding prior compress-then-finetune pipelines under the same ratained-parameter budget. We will release code.
Joint Architecture-Token-Bitwidth Multi-Axis Optimization of Vision Transformers for Semiconductor IC Packaging
May 03, 2026Vision Transformers (ViTs) have achieved strong performance in visual recognition, yet their deployment in resource-constrained industrial environments remains limited. Some main challenges are their high computational cost, memory requirement, and energy consumption. While individual efficiency techniques such as neural architecture search (NAS), token compression, and low-precision inference have been extensively studied, most prior work targets only a single optimization axis, limiting overall deployment gains while preserving accuracy. In this paper, we present one of the first holistic frameworks that jointly optimizes three complementary axes: architecture, token, and bit-width. Specifically, the framework identifies compact backbones via Neural Architecture Search (AutoFormer), reduces information processing via token merging (ToMe), and accelerates per-operation execution via fp16 mixed-precision inference. Starting from a DeiT-B/16 baseline, we first analyze accuracy-efficiency trade-offs on ImageNet-1K under aggressive compression. Then, we apply the selected configurations to a real-world in-house 3D X-ray semiconductor defect classification dataset for IC chip packaging inspection. Results show that the proposed multi-axis framework achieves more than 10 times improvement in throughput along with over 10 times reductions in parameter count, FLOPs, and energy consumption, while maintaining the required accuracy on the downstream industrial task. To the best of our knowledge, this is among the earliest works to jointly optimize architecture, token, and bit-width dimensions in ViTs and the first such resource-efficient, deployment-focused study tailored to semiconductor manufacturing.
PanDA: Unsupervised Domain Adaptation for Multimodal 3D Panoptic Segmentation in Autonomous Driving
Apr 21, 2026This paper presents the first study on Unsupervised Domain Adaptation (UDA) for multimodal 3D panoptic segmentation (mm-3DPS), aiming to improve generalization under domain shifts commonly encountered in real-world autonomous driving. A straightforward solution is to employ a pseudo-labeling strategy, which is widely used in UDA to generate supervision for unlabeled target data, combined with an mm-3DPS backbone. However, existing supervised mm-3DPS methods rely heavily on strong cross-modal complementarity between LiDAR and RGB inputs, making them fragile under domain shifts where one modality degrades (e.g., poor lighting or adverse weather). Moreover, conventional pseudo-labeling typically retains only high-confidence regions, leading to fragmented masks and incomplete object supervision, which are issues particularly detrimental to panoptic segmentation. To address these challenges, we propose PanDA, the first UDA framework specifically designed for multimodal 3D panoptic segmentation. To improve robustness against single-sensor degradation, we introduce an asymmetric multimodal augmentation that selectively drops regions to simulate domain shifts and improve robust representation learning. To enhance pseudo-label completeness and reliability, we further develop a dual-expert pseudo-label refinement module that extracts domain-invariant priors from both 2D and 3D modalities. Extensive experiments across diverse domain shifts, spanning time, weather, location, and sensor variations, significantly surpass state-of-the-art UDA baselines for 3D semantic segmentation.
Open-Ended Instruction Realization with LLM-Enabled Multi-Planner Scheduling in Autonomous Vehicles
Apr 09, 2026Most Human-Machine Interaction (HMI) research overlooks the maneuvering needs of passengers in autonomous driving (AD). Natural language offers an intuitive interface, yet translating passenger open-ended instructions into control signals, without sacrificing interpretability and traceability, remains a challenge. This study proposes an instruction-realization framework that leverages a large language model (LLM) to interpret instructions, generates executable scripts that schedule multiple model predictive control (MPC)-based motion planners based on real-time feedback, and converts planned trajectories into control signals. This scheduling-centric design decouples semantic reasoning from vehicle control at different timescales, establishing a transparent, traceable decision-making chain from high-level instructions to low-level actions. Due to the absence of high-fidelity evaluation tools, this study introduces a benchmark for open-ended instruction realization in a closed-loop setting. Comprehensive experiments reveal that the framework significantly improves task-completion rates over instruction-realization baselines, reduces LLM query costs, achieves safety and compliance on par with specialized AD approaches, and exhibits considerable tolerance to LLM inference latency. For more qualitative illustrations and a clearer understanding.
VLM-Guided Group Preference Alignment for Diffusion-based Human Mesh Recovery
Feb 22, 2026Human mesh recovery (HMR) from a single RGB image is inherently ambiguous, as multiple 3D poses can correspond to the same 2D observation. Recent diffusion-based methods tackle this by generating various hypotheses, but often sacrifice accuracy. They yield predictions that are either physically implausible or drift from the input image, especially under occlusion or in cluttered, in-the-wild scenes. To address this, we introduce a dual-memory augmented HMR critique agent with self-reflection to produce context-aware quality scores for predicted meshes. These scores distill fine-grained cues about 3D human motion structure, physical feasibility, and alignment with the input image. We use these scores to build a group-wise HMR preference dataset. Leveraging this dataset, we propose a group preference alignment framework for finetuning diffusion-based HMR models. This process injects the rich preference signals into the model, guiding it to generate more physically plausible and image-consistent human meshes. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
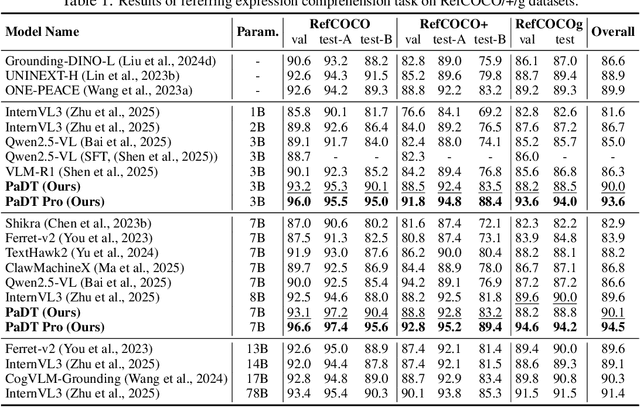

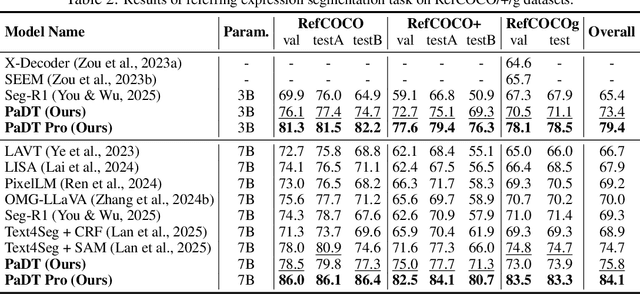
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.