 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordSim: A Scalable Data Generator and Benchmark for Affordance-Aware Robotic Manipulation
Apr 13, 2026Simulation-based data generation has become a dominant paradigm for training robotic manipulation policies, yet existing platforms do not incorporate object affordance information into trajectory generation. As a result, tasks requiring precise interaction with specific functional regions--grasping a mug by its handle, pouring from a cup's rim, or hanging a mug on a hook--cannot be automatically generated with semantically correct trajectories. We introduce AffordSim, the first simulation framework that integrates open-vocabulary 3D affordance prediction into the manipulation data generation pipeline. AffordSim uses our VoxAfford model, an open-vocabulary 3D affordance detector that enhances MLLM output tokens with multi-scale geometric features, to predict affordance maps on object point clouds, guiding grasp pose estimation toward task-relevant functional regions. Built on NVIDIA Isaac Sim with cross-embodiment support (Franka FR3, Panda, UR5e, Kinova), VLM-powered task generation, and novel domain randomization using DA3-based 3D Gaussian reconstruction from real photographs, AffordSim enables automated, scalable generation of affordance-aware manipulation data. We establish a benchmark of 50 tasks across 7 categories (grasping, placing, stacking, pushing/pulling, pouring, mug hanging, long-horizon composite) and evaluate 4 imitation learning baselines (BC, Diffusion Policy, ACT, Pi 0.5). Our results reveal that while grasping is largely solved (53-93% success), affordance-demanding tasks such as pouring into narrow containers (1-43%) and mug hanging (0-47%) remain significantly more challenging for current imitation learning methods, highlighting the need for affordance-aware data generation. Zero-shot sim-to-real experiments on a real Franka FR3 validate the transferability of the generated data.
How Do Images Align and Complement LiDAR? Towards a Harmonized Multi-modal 3D Panoptic Segmentation
May 25, 2025LiDAR-based 3D panoptic segmentation often struggles with the inherent sparsity of data from LiDAR sensors, which makes it challenging to accurately recognize distant or small objects. Recently, a few studies have sought to overcome this challenge by integrating LiDAR inputs with camera images, leveraging the rich and dense texture information provided by the latter. While these approaches have shown promising results, they still face challenges, such as misalignment during data augmentation and the reliance on post-processing steps. To address these issues, we propose Image-Assists-LiDAR (IAL), a novel multi-modal 3D panoptic segmentation framework. In IAL, we first introduce a modality-synchronized data augmentation strategy, PieAug, to ensure alignment between LiDAR and image inputs from the start. Next, we adopt a transformer decoder to directly predict panoptic segmentation results. To effectively fuse LiDAR and image features into tokens for the decoder, we design a Geometric-guided Token Fusion (GTF) module. Additionally, we leverage the complementary strengths of each modality as priors for query initialization through a Prior-based Query Generation (PQG) module, enhancing the decoder's ability to generate accurate instance masks. Our IAL framework achieves state-of-the-art performance compared to previous multi-modal 3D panoptic segmentation methods on two widely used benchmarks. Code and models are publicly available at <https://github.com/IMPL-Lab/IAL.git>.
FTMoMamba: Motion Generation with Frequency and Text State Space Models
Nov 26, 2024Diffusion models achieve impressive performance in human motion generation. However, current approaches typically ignore the significance of frequency-domain information in capturing fine-grained motions within the latent space (e.g., low frequencies correlate with static poses, and high frequencies align with fine-grained motions). Additionally, there is a semantic discrepancy between text and motion, leading to inconsistency between the generated motions and the text descriptions. In this work, we propose a novel diffusion-based FTMoMamba framework equipped with a Frequency State Space Model (FreqSSM) and a Text State Space Model (TextSSM). Specifically, to learn fine-grained representation, FreqSSM decomposes sequences into low-frequency and high-frequency components, guiding the generation of static pose (e.g., sits, lay) and fine-grained motions (e.g., transition, stumble), respectively. To ensure the consistency between text and motion, TextSSM encodes text features at the sentence level, aligning textual semantics with sequential features. Extensive experiments show that FTMoMamba achieves superior performance on the text-to-motion generation task, especially gaining the lowest FID of 0.181 (rather lower than 0.421 of MLD) on the HumanML3D dataset.
Multimodal Sense-Informed Prediction of 3D Human Motions
May 05, 2024



Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
GCNext: Towards the Unity of Graph Convolutions for Human Motion Prediction
Dec 19, 2023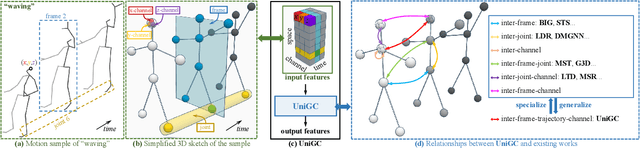
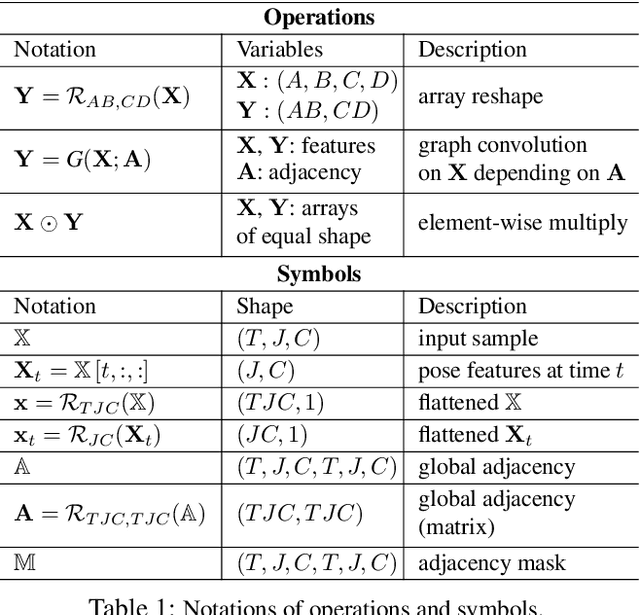
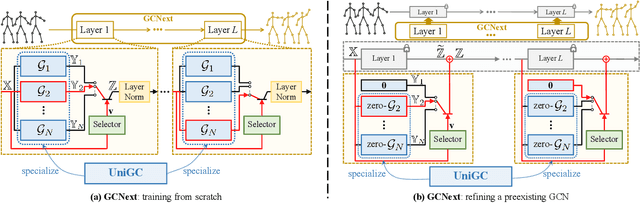
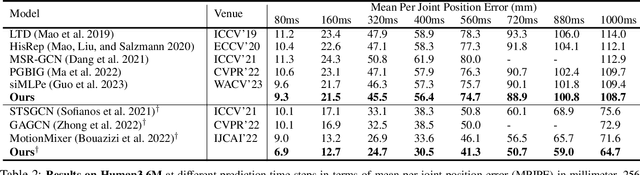
The past few years has witnessed the dominance of Graph Convolutional Networks (GCNs) over human motion prediction.Various styles of graph convolutions have been proposed, with each one meticulously designed and incorporated into a carefully-crafted network architecture. This paper breaks the limits of existing knowledge by proposing Universal Graph Convolution (UniGC), a novel graph convolution concept that re-conceptualizes different graph convolutions as its special cases. Leveraging UniGC on network-level, we propose GCNext, a novel GCN-building paradigm that dynamically determines the best-fitting graph convolutions both sample-wise and layer-wise. GCNext offers multiple use cases, including training a new GCN from scratch or refining a preexisting GCN. Experiments on Human3.6M, AMASS, and 3DPW datasets show that, by incorporating unique module-to-network designs, GCNext yields up to 9x lower computational cost than existing GCN methods, on top of achieving state-of-the-art performance.
Expressive Forecasting of 3D Whole-body Human Motions
Dec 19, 2023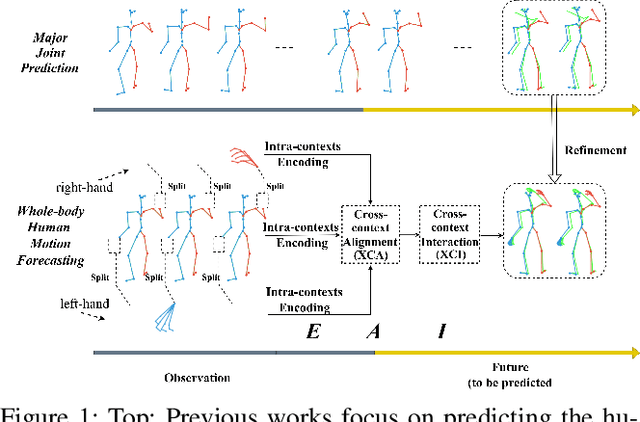
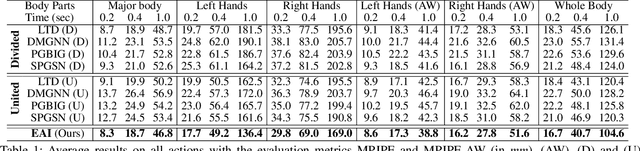
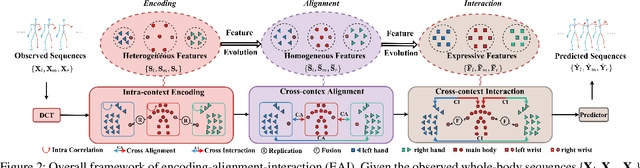
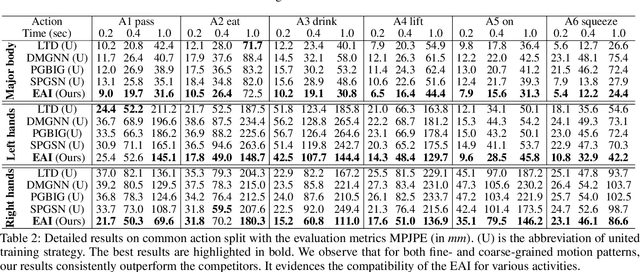
Human motion forecasting, with the goal of estimating future human behavior over a period of time, is a fundamental task in many real-world applications. However, existing works typically concentrate on predicting the major joints of the human body without considering the delicate movements of the human hands. In practical applications, hand gesture plays an important role in human communication with the real world, and expresses the primary intention of human beings. In this work, we are the first to formulate a whole-body human pose forecasting task, which jointly predicts the future body and hand activities. Correspondingly, we propose a novel Encoding-Alignment-Interaction (EAI) framework that aims to predict both coarse (body joints) and fine-grained (gestures) activities collaboratively, enabling expressive and cross-facilitated forecasting of 3D whole-body human motions. Specifically, our model involves two key constituents: cross-context alignment (XCA) and cross-context interaction (XCI). Considering the heterogeneous information within the whole-body, XCA aims to align the latent features of various human components, while XCI focuses on effectively capturing the context interaction among the human components. We conduct extensive experiments on a newly-introduced large-scale benchmark and achieve state-of-the-art performance. The code is public for research purposes at https://github.com/Dingpx/EAI.
Learning Snippet-to-Motion Progression for Skeleton-based Human Motion Prediction
Jul 26, 2023



Existing Graph Convolutional Networks to achieve human motion prediction largely adopt a one-step scheme, which output the prediction straight from history input, failing to exploit human motion patterns. We observe that human motions have transitional patterns and can be split into snippets representative of each transition. Each snippet can be reconstructed from its starting and ending poses referred to as the transitional poses. We propose a snippet-to-motion multi-stage framework that breaks motion prediction into sub-tasks easier to accomplish. Each sub-task integrates three modules: transitional pose prediction, snippet reconstruction, and snippet-to-motion prediction. Specifically, we propose to first predict only the transitional poses. Then we use them to reconstruct the corresponding snippets, obtaining a close approximation to the true motion sequence. Finally we refine them to produce the final prediction output. To implement the network, we propose a novel unified graph modeling, which allows for direct and effective feature propagation compared to existing approaches which rely on separate space-time modeling. Extensive experiments on Human 3.6M, CMU Mocap and 3DPW datasets verify the effectiveness of our method which achieves state-of-the-art performance.
Meta-Auxiliary Learning for Adaptive Human Pose Prediction
Apr 13, 2023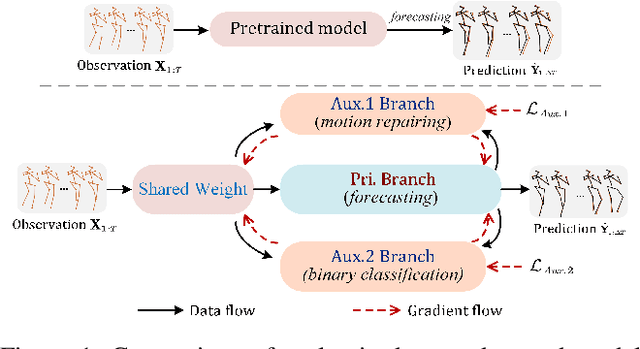
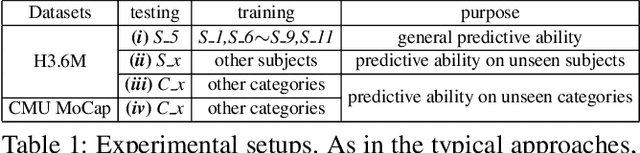
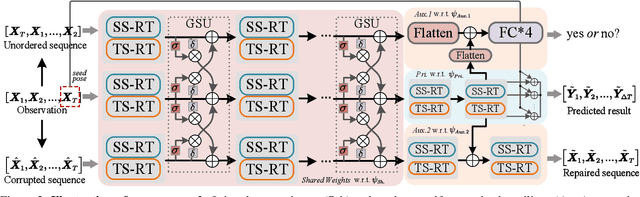
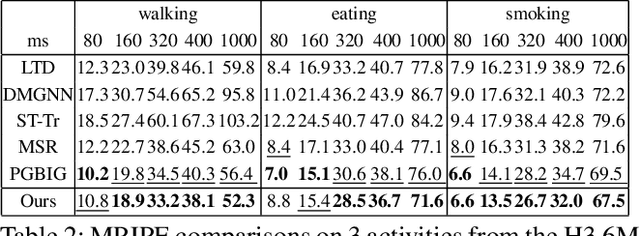
Predicting high-fidelity future human poses, from a historically observed sequence, is decisive for intelligent robots to interact with humans. Deep end-to-end learning approaches, which typically train a generic pre-trained model on external datasets and then directly apply it to all test samples, emerge as the dominant solution to solve this issue. Despite encouraging progress, they remain non-optimal, as the unique properties (e.g., motion style, rhythm) of a specific sequence cannot be adapted. More generally, at test-time, once encountering unseen motion categories (out-of-distribution), the predicted poses tend to be unreliable. Motivated by this observation, we propose a novel test-time adaptation framework that leverages two self-supervised auxiliary tasks to help the primary forecasting network adapt to the test sequence. In the testing phase, our model can adjust the model parameters by several gradient updates to improve the generation quality. However, due to catastrophic forgetting, both auxiliary tasks typically tend to the low ability to automatically present the desired positive incentives for the final prediction performance. For this reason, we also propose a meta-auxiliary learning scheme for better adaptation. In terms of general setup, our approach obtains higher accuracy, and under two new experimental designs for out-of-distribution data (unseen subjects and categories), achieves significant improvements.
Overlooked Poses Actually Make Sense: Distilling Privileged Knowledge for Human Motion Prediction
Aug 02, 2022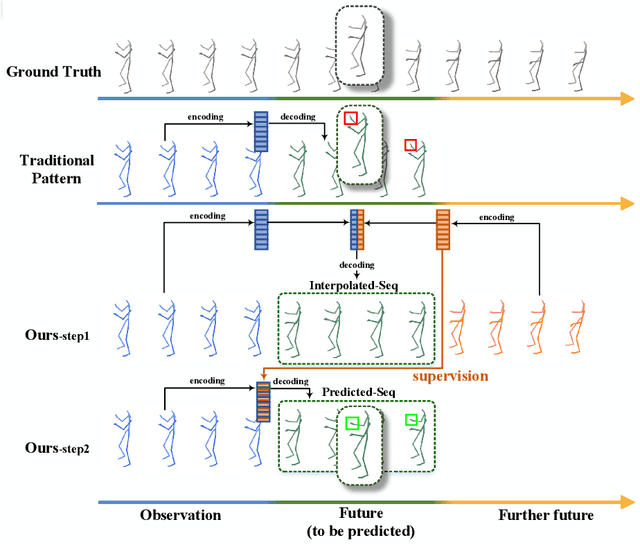
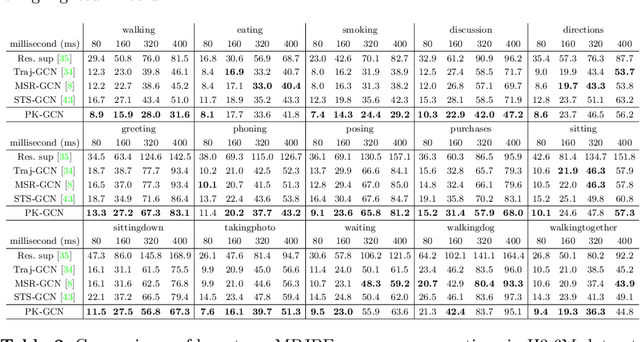
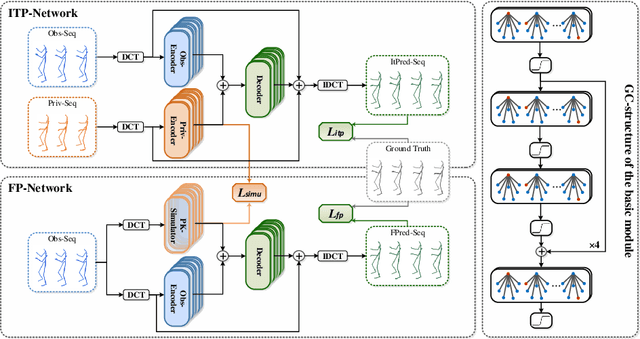
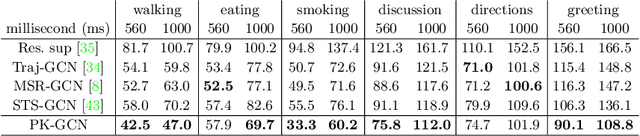
Previous works on human motion prediction follow the pattern of building a mapping relation between the sequence observed and the one to be predicted. However, due to the inherent complexity of multivariate time series data, it still remains a challenge to find the extrapolation relation between motion sequences. In this paper, we present a new prediction pattern, which introduces previously overlooked human poses, to implement the prediction task from the view of interpolation. These poses exist after the predicted sequence, and form the privileged sequence. To be specific, we first propose an InTerPolation learning Network (ITP-Network) that encodes both the observed sequence and the privileged sequence to interpolate the in-between predicted sequence, wherein the embedded Privileged-sequence-Encoder (Priv-Encoder) learns the privileged knowledge (PK) simultaneously. Then, we propose a Final Prediction Network (FP-Network) for which the privileged sequence is not observable, but is equipped with a novel PK-Simulator that distills PK learned from the previous network. This simulator takes as input the observed sequence, but approximates the behavior of Priv-Encoder, enabling FP-Network to imitate the interpolation process. Extensive experimental results demonstrate that our prediction pattern achieves state-of-the-art performance on benchmarked H3.6M, CMU-Mocap and 3DPW datasets in both short-term and long-term predictions.