 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndroid Coach: Improve Online Agentic Training Efficiency with Single State Multiple Actions
Apr 08, 2026Online reinforcement learning (RL) serves as an effective method for enhancing the capabilities of Android agents. However, guiding agents to learn through online interaction is prohibitively expensive due to the high latency of emulators and the sample inefficiency of existing RL algorithms. We identify a fundamental limitation in current approaches: the Single State Single Action paradigm, which updates the policy with one-to-one state-action pairs from online one-way rollouts without fully exploring each costly emulator state. In this paper, we propose Android Coach, a novel framework that shifts the training paradigm to Single State Multiple Actions, allowing the agent to sample and utilize multiple actions for a single online state. We enable this without additional emulator overhead by learning a critic that estimates action values. To ensure the critic serves as a reliable coach, we integrate a process reward model and introduce a group-wise advantage estimator based on the averaged critic outputs. Extensive experiments demonstrate the effectiveness and efficiency of Android Coach: it achieves 7.5% and 8.3% success rate improvements on AndroidLab and AndroidWorld over UI-TARS-1.5-7B, and attains 1.4x higher training efficiency than Single State Single Action methods PPO and GRPO at matched success rates.
Three-dimensional visualization of X-ray micro-CT with large-scale datasets: Efficiency and accuracy for real-time interaction
Jan 21, 2026As Micro-CT technology continues to refine its characterization of material microstructures, industrial CT ultra-precision inspection is generating increasingly large datasets, necessitating solutions to the trade-off between accuracy and efficiency in the 3D characterization of defects during ultra-precise detection. This article provides a unique perspective on recent advances in accurate and efficient 3D visualization using Micro-CT, tracing its evolution from medical imaging to industrial non-destructive testing (NDT). Among the numerous CT reconstruction and volume rendering methods, this article selectively reviews and analyzes approaches that balance accuracy and efficiency, offering a comprehensive analysis to help researchers quickly grasp highly efficient and accurate 3D reconstruction methods for microscopic features. By comparing the principles of computed tomography with advancements in microstructural technology, this article examines the evolution of CT reconstruction algorithms from analytical methods to deep learning techniques, as well as improvements in volume rendering algorithms, acceleration, and data reduction. Additionally, it explores advanced lighting models for high-accuracy, photorealistic, and efficient volume rendering. Furthermore, this article envisions potential directions in CT reconstruction and volume rendering. It aims to guide future research in quickly selecting efficient and precise methods and developing new ideas and approaches for real-time online monitoring of internal material defects through virtual-physical interaction, for applying digital twin model to structural health monitoring (SHM).
Spatial Multi-Task Learning for Breast Cancer Molecular Subtype Prediction from Single-Phase DCE-MRI
Jan 11, 2026Accurate molecular subtype classification is essential for personalized breast cancer treatment, yet conventional immunohistochemical analysis relies on invasive biopsies and is prone to sampling bias. Although dynamic contrast-enhanced magnetic resonance imaging (DCE-MRI) enables non-invasive tumor characterization, clinical workflows typically acquire only single-phase post-contrast images to reduce scan time and contrast agent dose. In this study, we propose a spatial multi-task learning framework for breast cancer molecular subtype prediction from clinically practical single-phase DCE-MRI. The framework simultaneously predicts estrogen receptor (ER), progesterone receptor (PR), human epidermal growth factor receptor 2 (HER2) status, and the Ki-67 proliferation index -- biomarkers that collectively define molecular subtypes. The architecture integrates a deep feature extraction network with multi-scale spatial attention to capture intratumoral and peritumoral characteristics, together with a region-of-interest weighting module that emphasizes the tumor core, rim, and surrounding tissue. Multi-task learning exploits biological correlations among biomarkers through shared representations with task-specific prediction branches. Experiments on a dataset of 960 cases (886 internal cases split 7:1:2 for training/validation/testing, and 74 external cases evaluated via five-fold cross-validation) demonstrate that the proposed method achieves an AUC of 0.893, 0.824, and 0.857 for ER, PR, and HER2 classification, respectively, and a mean absolute error of 8.2\% for Ki-67 regression, significantly outperforming radiomics and single-task deep learning baselines. These results indicate the feasibility of accurate, non-invasive molecular subtype prediction using standard imaging protocols.
TokenSeg: Efficient 3D Medical Image Segmentation via Hierarchical Visual Token Compression
Jan 08, 2026Three-dimensional medical image segmentation is a fundamental yet computationally demanding task due to the cubic growth of voxel processing and the redundant computation on homogeneous regions. To address these limitations, we propose \textbf{TokenSeg}, a boundary-aware sparse token representation framework for efficient 3D medical volume segmentation. Specifically, (1) we design a \emph{multi-scale hierarchical encoder} that extracts 400 candidate tokens across four resolution levels to capture both global anatomical context and fine boundary details; (2) we introduce a \emph{boundary-aware tokenizer} that combines VQ-VAE quantization with importance scoring to select 100 salient tokens, over 60\% of which lie near tumor boundaries; and (3) we develop a \emph{sparse-to-dense decoder} that reconstructs full-resolution masks through token reprojection, progressive upsampling, and skip connections. Extensive experiments on a 3D breast DCE-MRI dataset comprising 960 cases demonstrate that TokenSeg achieves state-of-the-art performance with 94.49\% Dice and 89.61\% IoU, while reducing GPU memory and inference latency by 64\% and 68\%, respectively. To verify the generalization capability, our evaluations on MSD cardiac and brain MRI benchmark datasets demonstrate that TokenSeg consistently delivers optimal performance across heterogeneous anatomical structures. These results highlight the effectiveness of anatomically informed sparse representation for accurate and efficient 3D medical image segmentation.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025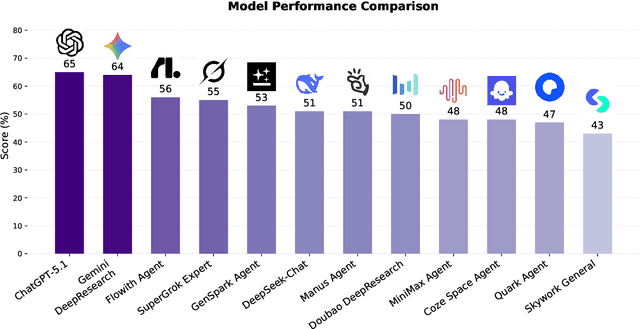
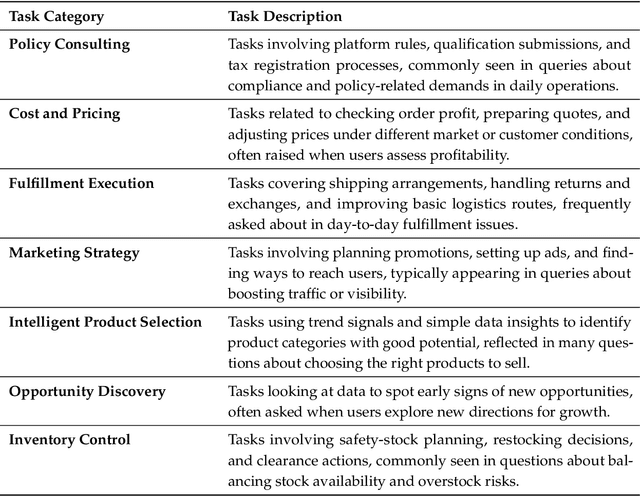

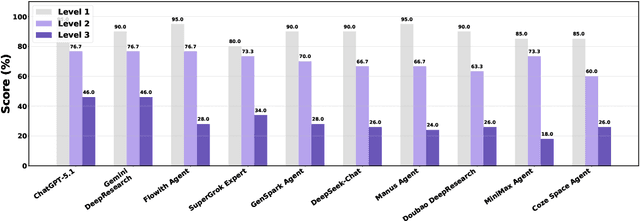
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Optimal Interference Signal for Masking an Acoustic Source
Aug 20, 2025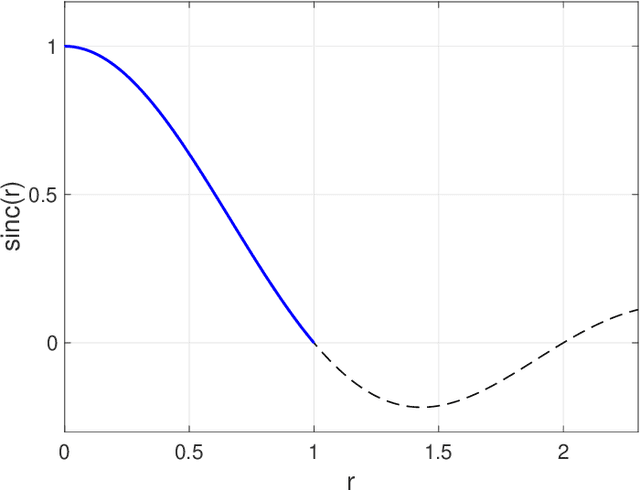
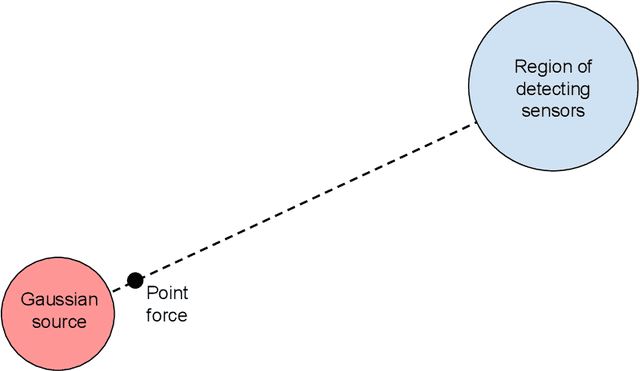
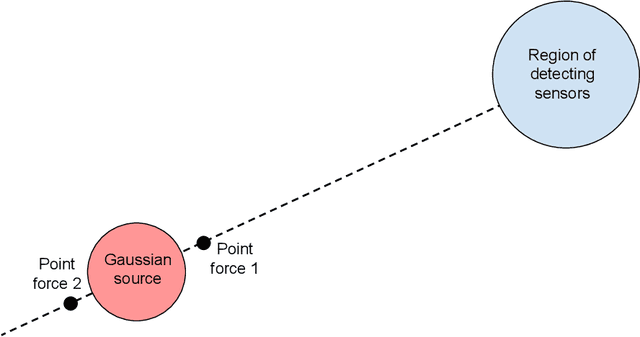
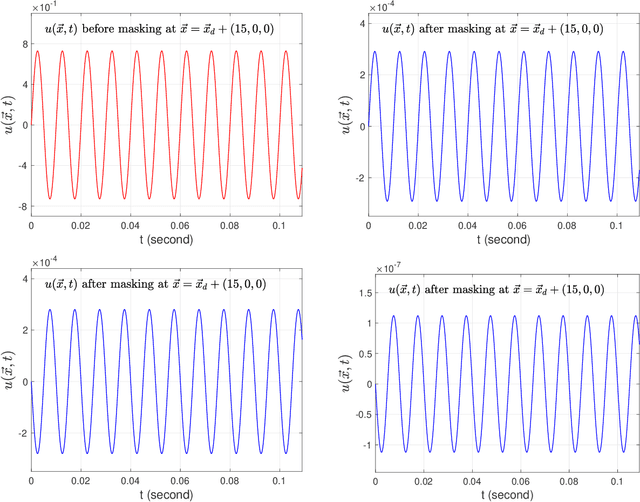
In an environment where acoustic privacy or deliberate signal obfuscation is desired, it is necessary to mask the acoustic signature generated in essential operations. We consider the problem of masking the effect of an acoustic source in a target region where possible detection sensors are located. Masking is achieved by placing interference signals near the acoustic source. We introduce a theoretical and computational framework for designing such interference signals with the goal of minimizing the residual amplitude in the target region. For the three-dimensional (3D) forced wave equation with spherical symmetry, we derive analytical quasi-steady periodic solutions for several canonical cases. We examine the phenomenon of self-masking where an acoustic source with certain spatial forcing profile masks itself from detection outside its forcing footprint. We then use superposition of spherically symmetric solutions to investigate masking in a given target region. We analyze and optimize the performance of using one or two point-forces deployed near the acoustic source for masking in the target region. For the general case where the spatial forcing profile of the acoustic source lacks spherical symmetry, we develop an efficient numerical method for solving the 3D wave equation. Potential applications of this work include undersea acoustic communication security, undersea vehicles stealth, and protection against acoustic surveillance.
Reinforcement Learning in Vision: A Survey
Aug 11, 2025Recent advances at the intersection of reinforcement learning (RL) and visual intelligence have enabled agents that not only perceive complex visual scenes but also reason, generate, and act within them. This survey offers a critical and up-to-date synthesis of the field. We first formalize visual RL problems and trace the evolution of policy-optimization strategies from RLHF to verifiable reward paradigms, and from Proximal Policy Optimization to Group Relative Policy Optimization. We then organize more than 200 representative works into four thematic pillars: multi-modal large language models, visual generation, unified model frameworks, and vision-language-action models. For each pillar we examine algorithmic design, reward engineering, benchmark progress, and we distill trends such as curriculum-driven training, preference-aligned diffusion, and unified reward modeling. Finally, we review evaluation protocols spanning set-level fidelity, sample-level preference, and state-level stability, and we identify open challenges that include sample efficiency, generalization, and safe deployment. Our goal is to provide researchers and practitioners with a coherent map of the rapidly expanding landscape of visual RL and to highlight promising directions for future inquiry. Resources are available at: https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning.
Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
Dec 15, 20243D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
ZipAR: Accelerating Autoregressive Image Generation through Spatial Locality
Dec 05, 2024

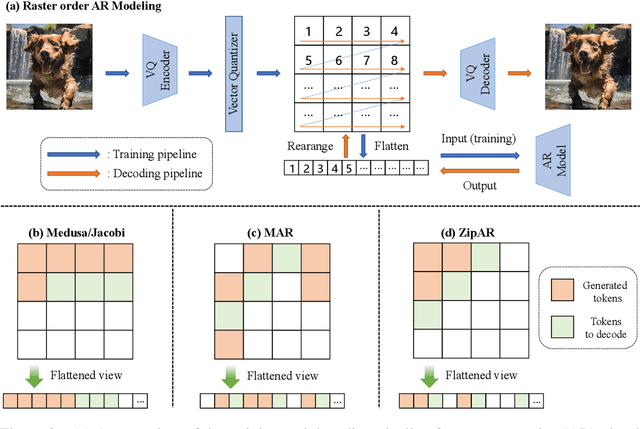

In this paper, we propose ZipAR, a training-free, plug-and-play parallel decoding framework for accelerating auto-regressive (AR) visual generation. The motivation stems from the observation that images exhibit local structures, and spatially distant regions tend to have minimal interdependence. Given a partially decoded set of visual tokens, in addition to the original next-token prediction scheme in the row dimension, the tokens corresponding to spatially adjacent regions in the column dimension can be decoded in parallel, enabling the ``next-set prediction'' paradigm. By decoding multiple tokens simultaneously in a single forward pass, the number of forward passes required to generate an image is significantly reduced, resulting in a substantial improvement in generation efficiency. Experiments demonstrate that ZipAR can reduce the number of model forward passes by up to 91% on the Emu3-Gen model without requiring any additional retraining.
Experimental Design Using Interlacing Polynomials
Oct 15, 2024We present a unified deterministic approach for experimental design problems using the method of interlacing polynomials. Our framework recovers the best-known approximation guarantees for the well-studied D/A/E-design problems with simple analysis. Furthermore, we obtain improved non-trivial approximation guarantee for E-design in the challenging small budget regime. Additionally, our approach provides an optimal approximation guarantee for a generalized ratio objective that generalizes both D-design and A-design.