 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlineHMR: Video-based Online World-Grounded Human Mesh Recovery
Mar 18, 2026Human mesh recovery (HMR) models 3D human body from monocular videos, with recent works extending it to world-coordinate human trajectory and motion reconstruction. However, most existing methods remain offline, relying on future frames or global optimization, which limits their applicability in interactive feedback and perception-action loop scenarios such as AR/VR and telepresence. To address this, we propose OnlineHMR, a fully online framework that jointly satisfies four essential criteria of online processing, including system-level causality, faithfulness, temporal consistency, and efficiency. Built upon a two-branch architecture, OnlineHMR enables streaming inference via a causal key-value cache design and a curated sliding-window learning strategy. Meanwhile, a human-centric incremental SLAM provides online world-grounded alignment under physically plausible trajectory correction. Experimental results show that our method achieves performance comparable to existing chunk-based approaches on the standard EMDB benchmark and highly dynamic custom videos, while uniquely supporting online processing. Page and code are available at https://tsukasane.github.io/Video-OnlineHMR/.
DuoMo: Dual Motion Diffusion for World-Space Human Reconstruction
Mar 03, 2026We present DuoMo, a generative method that recovers human motion in world-space coordinates from unconstrained videos with noisy or incomplete observations. Reconstructing such motion requires solving a fundamental trade-off: generalizing from diverse and noisy video inputs while maintaining global motion consistency. Our approach addresses this problem by factorizing motion learning into two diffusion models. The camera-space model first estimates motion from videos in camera coordinates. The world-space model then lifts this initial estimate into world coordinates and refines it to be globally consistent. Together, the two models can reconstruct motion across diverse scenes and trajectories, even from highly noisy or incomplete observations. Moreover, our formulation is general, generating the motion of mesh vertices directly and bypassing parametric models. DuoMo achieves state-of-the-art performance. On EMDB, our method obtains a 16% reduction in world-space reconstruction error while maintaining low foot skating. On RICH, it obtains a 30% reduction in world-space error. Project page: https://yufu-wang.github.io/duomo/
Zero-shot Reconstruction of In-Scene Object Manipulation from Video
Dec 22, 2025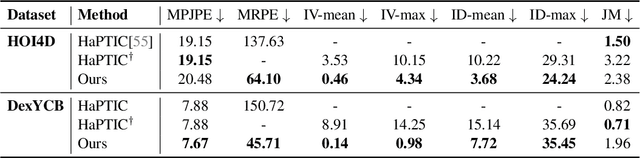
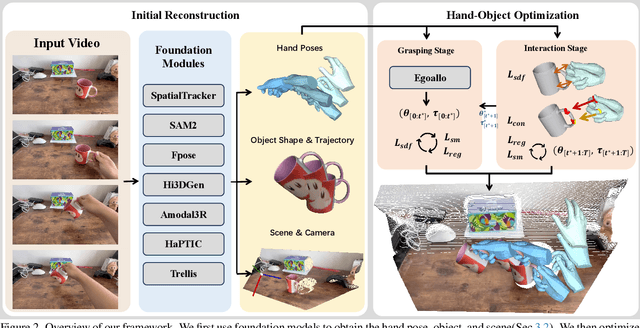
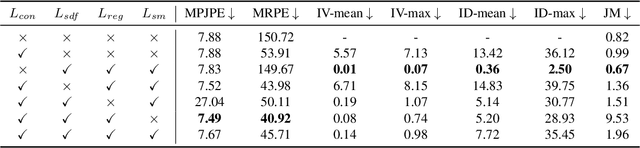
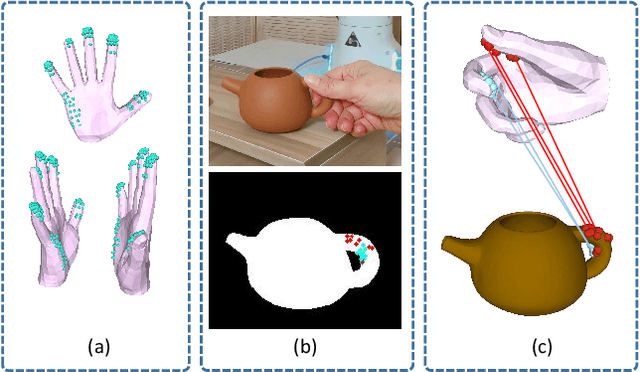
We build the first system to address the problem of reconstructing in-scene object manipulation from a monocular RGB video. It is challenging due to ill-posed scene reconstruction, ambiguous hand-object depth, and the need for physically plausible interactions. Existing methods operate in hand centric coordinates and ignore the scene, hindering metric accuracy and practical use. In our method, we first use data-driven foundation models to initialize the core components, including the object mesh and poses, the scene point cloud, and the hand poses. We then apply a two-stage optimization that recovers a complete hand-object motion from grasping to interaction, which remains consistent with the scene information observed in the input video.
PromptHMR: Promptable Human Mesh Recovery
Apr 08, 2025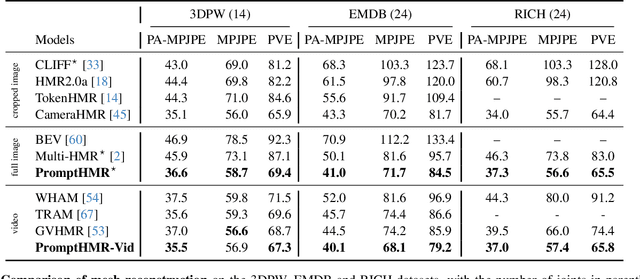
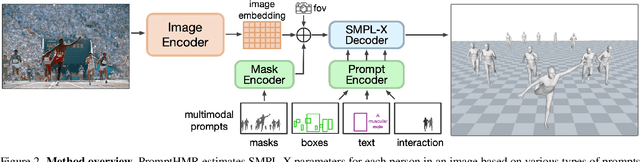
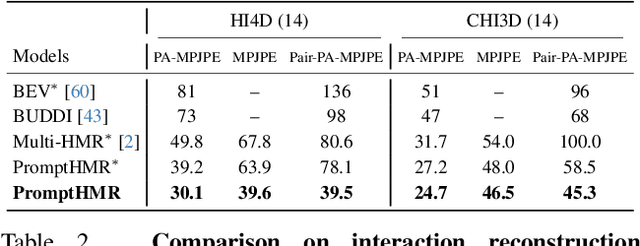
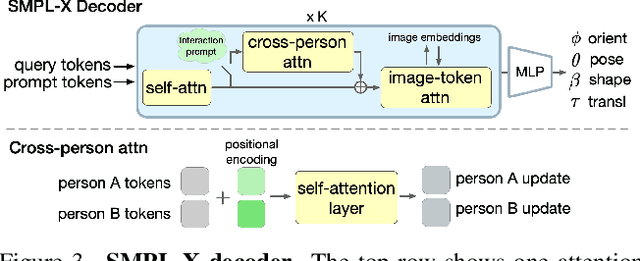
Human pose and shape (HPS) estimation presents challenges in diverse scenarios such as crowded scenes, person-person interactions, and single-view reconstruction. Existing approaches lack mechanisms to incorporate auxiliary "side information" that could enhance reconstruction accuracy in such challenging scenarios. Furthermore, the most accurate methods rely on cropped person detections and cannot exploit scene context while methods that process the whole image often fail to detect people and are less accurate than methods that use crops. While recent language-based methods explore HPS reasoning through large language or vision-language models, their metric accuracy is well below the state of the art. In contrast, we present PromptHMR, a transformer-based promptable method that reformulates HPS estimation through spatial and semantic prompts. Our method processes full images to maintain scene context and accepts multiple input modalities: spatial prompts like bounding boxes and masks, and semantic prompts like language descriptions or interaction labels. PromptHMR demonstrates robust performance across challenging scenarios: estimating people from bounding boxes as small as faces in crowded scenes, improving body shape estimation through language descriptions, modeling person-person interactions, and producing temporally coherent motions in videos. Experiments on benchmarks show that PromptHMR achieves state-of-the-art performance while offering flexible prompt-based control over the HPS estimation process.
Continuous-Time Human Motion Field from Events
Dec 02, 2024This paper addresses the challenges of estimating a continuous-time human motion field from a stream of events. Existing Human Mesh Recovery (HMR) methods rely predominantly on frame-based approaches, which are prone to aliasing and inaccuracies due to limited temporal resolution and motion blur. In this work, we predict a continuous-time human motion field directly from events by leveraging a recurrent feed-forward neural network to predict human motion in the latent space of possible human motions. Prior state-of-the-art event-based methods rely on computationally intensive optimization across a fixed number of poses at high frame rates, which becomes prohibitively expensive as we increase the temporal resolution. In comparison, we present the first work that replaces traditional discrete-time predictions with a continuous human motion field represented as a time-implicit function, enabling parallel pose queries at arbitrary temporal resolutions. Despite the promises of event cameras, few benchmarks have tested the limit of high-speed human motion estimation. We introduce Beam-splitter Event Agile Human Motion Dataset-a hardware-synchronized high-speed human dataset to fill this gap. On this new data, our method improves joint errors by 23.8% compared to previous event human methods while reducing the computational time by 69%.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
The intelligent prediction and assessment of financial information risk in the cloud computing model
Apr 14, 2024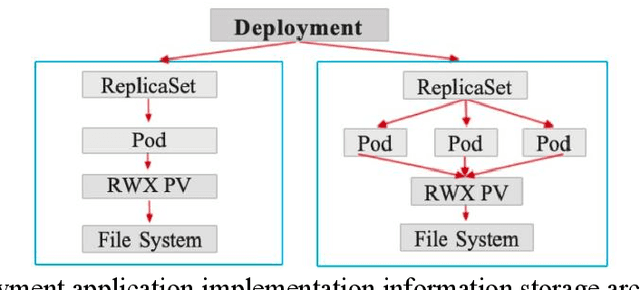
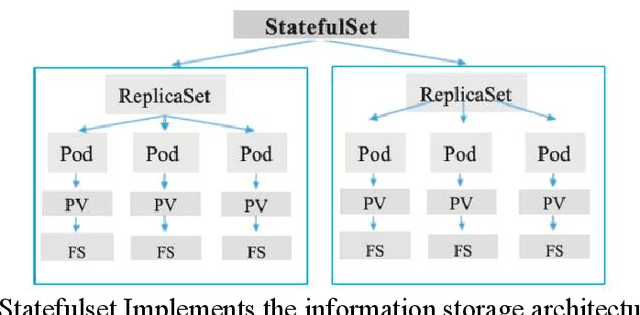

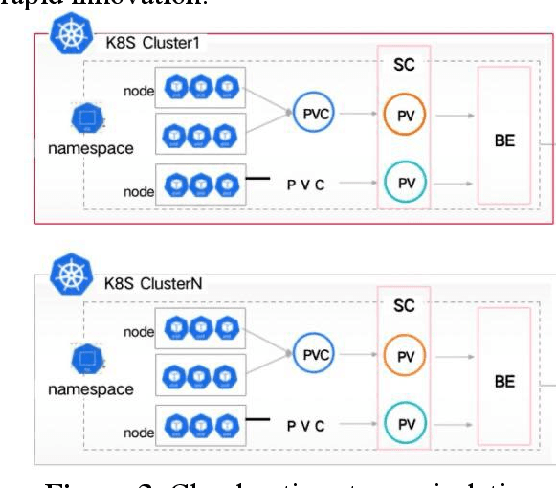
Cloud computing (cloud computing) is a kind of distributed computing, referring to the network "cloud" will be a huge data calculation and processing program into countless small programs, and then, through the system composed of multiple servers to process and analyze these small programs to get the results and return to the user. This report explores the intersection of cloud computing and financial information processing, identifying risks and challenges faced by financial institutions in adopting cloud technology. It discusses the need for intelligent solutions to enhance data processing efficiency and accuracy while addressing security and privacy concerns. Drawing on regulatory frameworks, the report proposes policy recommendations to mitigate concentration risks associated with cloud computing in the financial industry. By combining intelligent forecasting and evaluation technologies with cloud computing models, the study aims to provide effective solutions for financial data processing and management, facilitating the industry's transition towards digital transformation.
TRAM: Global Trajectory and Motion of 3D Humans from in-the-wild Videos
Mar 26, 2024



We propose TRAM, a two-stage method to reconstruct a human's global trajectory and motion from in-the-wild videos. TRAM robustifies SLAM to recover the camera motion in the presence of dynamic humans and uses the scene background to derive the motion scale. Using the recovered camera as a metric-scale reference frame, we introduce a video transformer model (VIMO) to regress the kinematic body motion of a human. By composing the two motions, we achieve accurate recovery of 3D humans in the world space, reducing global motion errors by 60% from prior work. https://yufu-wang.github.io/tram4d/
GART: Gaussian Articulated Template Models
Nov 27, 2023We introduce Gaussian Articulated Template Model GART, an explicit, efficient, and expressive representation for non-rigid articulated subject capturing and rendering from monocular videos. GART utilizes a mixture of moving 3D Gaussians to explicitly approximate a deformable subject's geometry and appearance. It takes advantage of a categorical template model prior (SMPL, SMAL, etc.) with learnable forward skinning while further generalizing to more complex non-rigid deformations with novel latent bones. GART can be reconstructed via differentiable rendering from monocular videos in seconds or minutes and rendered in novel poses faster than 150fps.