 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLE-R1: Video-Language Reasoning as the Sole Reward for On-Robot Reinforcement Learning
Mar 30, 2026Vision-language models (VLMs) have shown impressive capabilities across diverse tasks, motivating efforts to leverage these models to supervise robot learning. However, when used as evaluators in reinforcement learning (RL), today's strongest models often fail under partial observability and distribution shift, enabling policies to exploit perceptual errors rather than solve the task. To address this limitation, we introduce SOLE-R1 (Self-Observing LEarner), a video-language reasoning model explicitly designed to serve as the sole reward signal for online RL. Given only raw video observations and a natural-language goal, SOLE-R1 performs per-timestep spatiotemporal chain-of-thought (CoT) reasoning and produces dense estimates of task progress that can be used directly as rewards. To train SOLE-R1, we develop a large-scale video trajectory and reasoning synthesis pipeline that generates temporally grounded CoT traces aligned with continuous progress supervision. This data is combined with foundational spatial and multi-frame temporal reasoning, and used to train the model with a hybrid framework that couples supervised fine-tuning with RL from verifiable rewards. Across four different simulation environments and a real-robot setting, SOLE-R1 enables zero-shot online RL from random initialization: robots learn previously unseen manipulation tasks without ground-truth rewards, success indicators, demonstrations, or task-specific tuning. SOLE-R1 succeeds on 24 unseen tasks and substantially outperforms strong vision-language rewarders, including GPT-5 and Gemini-3-Pro, while exhibiting markedly greater robustness to reward hacking.
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Mar 16, 2026What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.
ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
AnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning
Dec 19, 2025Generalist robot learning remains constrained by data: large-scale, diverse, and high-quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort. We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible: 1) ViPR, a novel task and motion planning agent with VLM-in-the-loop Parallel Refinement; 2) ViPR-Eureka, a reinforcement learning agent with generated dense rewards and LLM-guided contact sampling; 3) ViPR-RL, a hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards. We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks. Our project website is at https://anytask.rai-inst.com .
Sceniris: A Fast Procedural Scene Generation Framework
Dec 18, 2025Synthetic 3D scenes are essential for developing Physical AI and generative models. Existing procedural generation methods often have low output throughput, creating a significant bottleneck in scaling up dataset creation. In this work, we introduce Sceniris, a highly efficient procedural scene generation framework for rapidly generating large-scale, collision-free scene variations. Sceniris also provides an optional robot reachability check, providing manipulation-feasible scenes for robot tasks. Sceniris is designed for maximum efficiency by addressing the primary performance limitations of the prior method, Scene Synthesizer. Leveraging batch sampling and faster collision checking in cuRobo, Sceniris achieves at least 234x speed-up over Scene Synthesizer. Sceniris also expands the object-wise spatial relationships available in prior work to support diverse scene requirements. Our code is available at https://github.com/rai-inst/sceniris
Real-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation
Apr 04, 2025Recent advancements in behavior cloning have enabled robots to perform complex manipulation tasks. However, accurately assessing training performance remains challenging, particularly for real-world applications, as behavior cloning losses often correlate poorly with actual task success. Consequently, researchers resort to success rate metrics derived from costly and time-consuming real-world evaluations, making the identification of optimal policies and detection of overfitting or underfitting impractical. To address these issues, we propose real-is-sim, a novel behavior cloning framework that incorporates a dynamic digital twin (based on Embodied Gaussians) throughout the entire policy development pipeline: data collection, training, and deployment. By continuously aligning the simulated world with the physical world, demonstrations can be collected in the real world with states extracted from the simulator. The simulator enables flexible state representations by rendering image inputs from any viewpoint or extracting low-level state information from objects embodied within the scene. During training, policies can be directly evaluated within the simulator in an offline and highly parallelizable manner. Finally, during deployment, policies are run within the simulator where the real robot directly tracks the simulated robot's joints, effectively decoupling policy execution from real hardware and mitigating traditional domain-transfer challenges. We validate real-is-sim on the PushT manipulation task, demonstrating strong correlation between success rates obtained in the simulator and real-world evaluations. Videos of our system can be found at https://realissim.rai-inst.com.
On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Oct 25, 2024Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Designing dense reward functions is labour-intensive and requires domain expertise. In our work, we propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, our method is easier to scale, as we can use arbitrary videos. GCR combines two loss functions, an implicit value loss function that models how the reward increases when traversing a successful trajectory, and a goal-contrastive loss that discriminates between successful and failed trajectories. We perform experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. We find that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as our baseline reward learning methods. We also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task. Appendix: \url{https://tinyurl.com/gcr-appendix-2}.
Theia: Distilling Diverse Vision Foundation Models for Robot Learning
Jul 29, 2024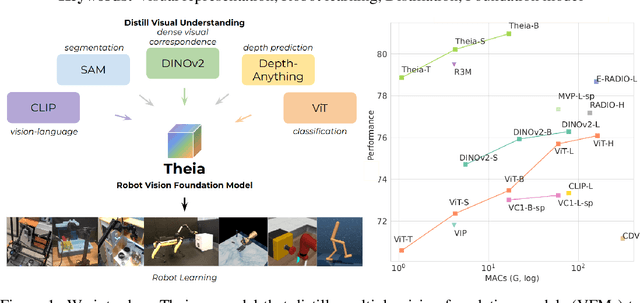



Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance. Code and models are available at https://github.com/bdaiinstitute/theia.
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Jun 17, 2024


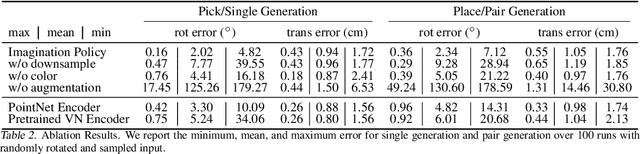
Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.
EFEM: Equivariant Neural Field Expectation Maximization for 3D Object Segmentation Without Scene Supervision
Mar 27, 2023
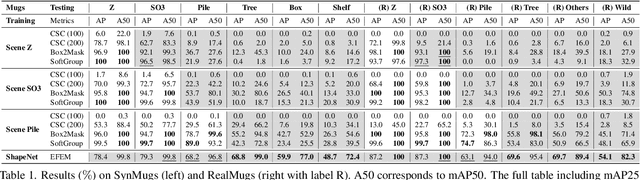
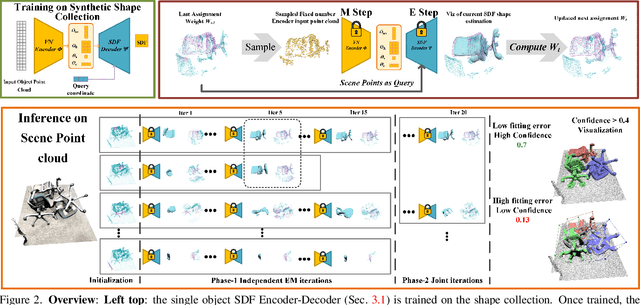
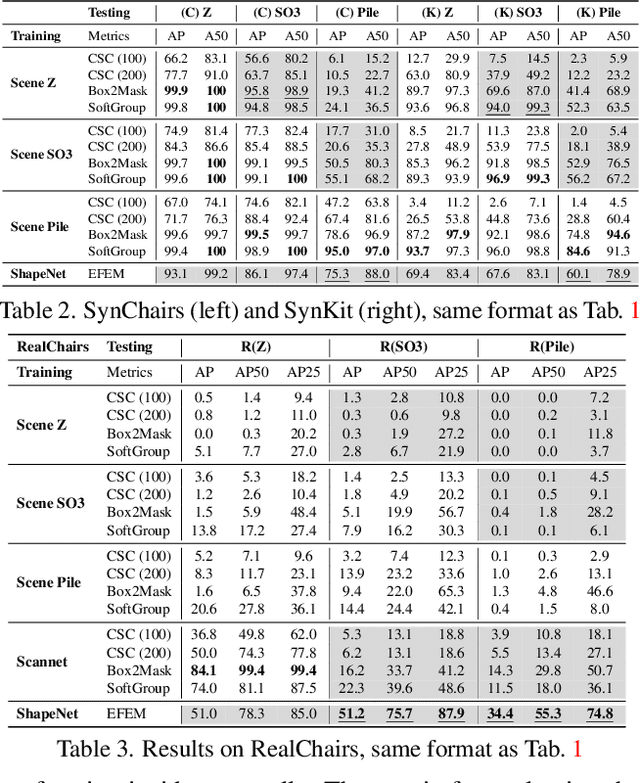
We introduce Equivariant Neural Field Expectation Maximization (EFEM), a simple, effective, and robust geometric algorithm that can segment objects in 3D scenes without annotations or training on scenes. We achieve such unsupervised segmentation by exploiting single object shape priors. We make two novel steps in that direction. First, we introduce equivariant shape representations to this problem to eliminate the complexity induced by the variation in object configuration. Second, we propose a novel EM algorithm that can iteratively refine segmentation masks using the equivariant shape prior. We collect a novel real dataset Chairs and Mugs that contains various object configurations and novel scenes in order to verify the effectiveness and robustness of our method. Experimental results demonstrate that our method achieves consistent and robust performance across different scenes where the (weakly) supervised methods may fail. Code and data available at https://www.cis.upenn.edu/~leijh/projects/efem