 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
WebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
Hierarchical Equivariant Policy via Frame Transf
Feb 09, 2025Recent advances in hierarchical policy learning highlight the advantages of decomposing systems into high-level and low-level agents, enabling efficient long-horizon reasoning and precise fine-grained control. However, the interface between these hierarchy levels remains underexplored, and existing hierarchical methods often ignore domain symmetry, resulting in the need for extensive demonstrations to achieve robust performance. To address these issues, we propose Hierarchical Equivariant Policy (HEP), a novel hierarchical policy framework. We propose a frame transfer interface for hierarchical policy learning, which uses the high-level agent's output as a coordinate frame for the low-level agent, providing a strong inductive bias while retaining flexibility. Additionally, we integrate domain symmetries into both levels and theoretically demonstrate the system's overall equivariance. HEP achieves state-of-the-art performance in complex robotic manipulation tasks, demonstrating significant improvements in both simulation and real-world settings.
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Jul 16, 2024



Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Jun 17, 2024


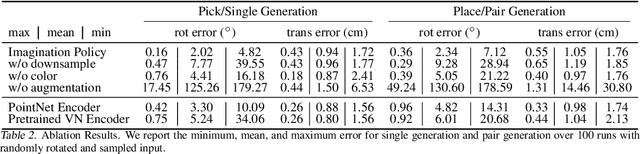
Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.