 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Rotation Correction using Tactile Equivariance
Nov 11, 2025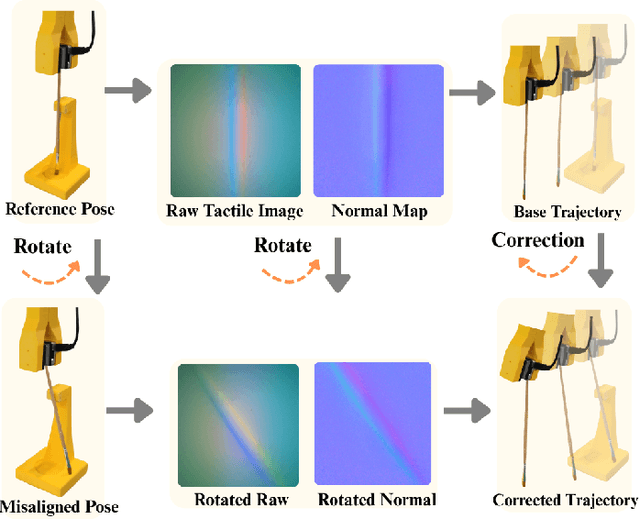
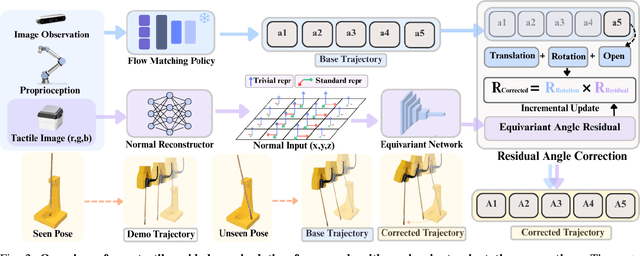
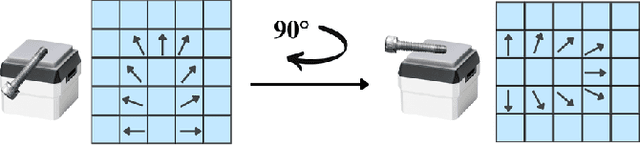

Visuotactile policy learning augments vision-only policies with tactile input, facilitating contact-rich manipulation. However, the high cost of tactile data collection makes sample efficiency the key requirement for developing visuotactile policies. We present EquiTac, a framework that exploits the inherent SO(2) symmetry of in-hand object rotation to improve sample efficiency and generalization for visuotactile policy learning. EquiTac first reconstructs surface normals from raw RGB inputs of vision-based tactile sensors, so rotations of the normal vector field correspond to in-hand object rotations. An SO(2)-equivariant network then predicts a residual rotation action that augments a base visuomotor policy at test time, enabling real-time rotation correction without additional reorientation demonstrations. On a real robot, EquiTac accurately achieves robust zero-shot generalization to unseen in-hand orientations with very few training samples, where baselines fail even with more training data. To our knowledge, this is the first tactile learning method to explicitly encode tactile equivariance for policy learning, yielding a lightweight, symmetry-aware module that improves reliability in contact-rich tasks.
Argus: Federated Non-convex Bilevel Learning over 6G Space-Air-Ground Integrated Network
May 14, 2025
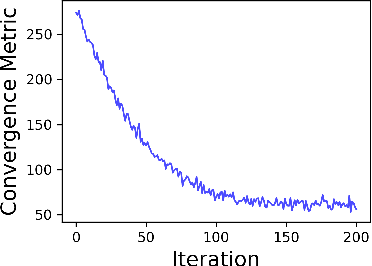

The space-air-ground integrated network (SAGIN) has recently emerged as a core element in the 6G networks. However, traditional centralized and synchronous optimization algorithms are unsuitable for SAGIN due to infrastructureless and time-varying environments. This paper aims to develop a novel Asynchronous algorithm a.k.a. Argus for tackling non-convex and non-smooth decentralized federated bilevel learning over SAGIN. The proposed algorithm allows networked agents (e.g. autonomous aerial vehicles) to tackle bilevel learning problems in time-varying networks asynchronously, thereby averting stragglers from impeding the overall training speed. We provide a theoretical analysis of the iteration complexity, communication complexity, and computational complexity of Argus. Its effectiveness is further demonstrated through numerical experiments.
Hierarchical Equivariant Policy via Frame Transf
Feb 09, 2025Recent advances in hierarchical policy learning highlight the advantages of decomposing systems into high-level and low-level agents, enabling efficient long-horizon reasoning and precise fine-grained control. However, the interface between these hierarchy levels remains underexplored, and existing hierarchical methods often ignore domain symmetry, resulting in the need for extensive demonstrations to achieve robust performance. To address these issues, we propose Hierarchical Equivariant Policy (HEP), a novel hierarchical policy framework. We propose a frame transfer interface for hierarchical policy learning, which uses the high-level agent's output as a coordinate frame for the low-level agent, providing a strong inductive bias while retaining flexibility. Additionally, we integrate domain symmetries into both levels and theoretically demonstrate the system's overall equivariance. HEP achieves state-of-the-art performance in complex robotic manipulation tasks, demonstrating significant improvements in both simulation and real-world settings.
Equivariant Diffusion Policy
Jul 01, 2024Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the $\mathrm{SO}(2)$ symmetry of full 6-DoF control and characterize when a diffusion model is $\mathrm{SO}(2)$-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
StableGarment: Garment-Centric Generation via Stable Diffusion
Mar 16, 2024



In this paper, we introduce StableGarment, a unified framework to tackle garment-centric(GC) generation tasks, including GC text-to-image, controllable GC text-to-image, stylized GC text-to-image, and robust virtual try-on. The main challenge lies in retaining the intricate textures of the garment while maintaining the flexibility of pre-trained Stable Diffusion. Our solution involves the development of a garment encoder, a trainable copy of the denoising UNet equipped with additive self-attention (ASA) layers. These ASA layers are specifically devised to transfer detailed garment textures, also facilitating the integration of stylized base models for the creation of stylized images. Furthermore, the incorporation of a dedicated try-on ControlNet enables StableGarment to execute virtual try-on tasks with precision. We also build a novel data engine that produces high-quality synthesized data to preserve the model's ability to follow prompts. Extensive experiments demonstrate that our approach delivers state-of-the-art (SOTA) results among existing virtual try-on methods and exhibits high flexibility with broad potential applications in various garment-centric image generation.
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model
Mar 12, 2024Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.