 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Diffusion Policy
Jul 01, 2024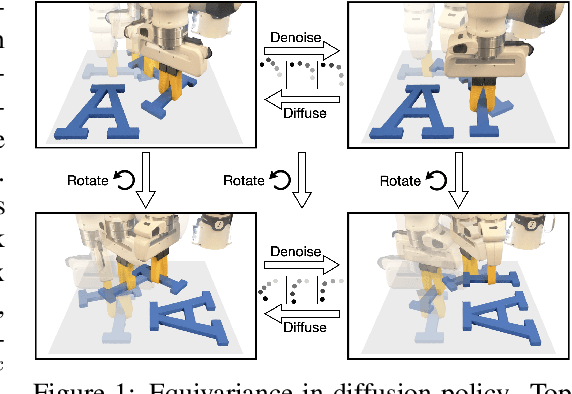



Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the $\mathrm{SO}(2)$ symmetry of full 6-DoF control and characterize when a diffusion model is $\mathrm{SO}(2)$-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
Receding-Horizon Perceptive Trajectory Optimization for Dynamic Legged Locomotion with Learned Initialization
Apr 19, 2021

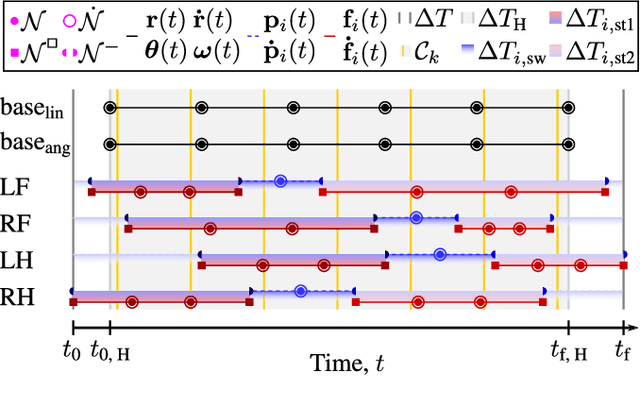
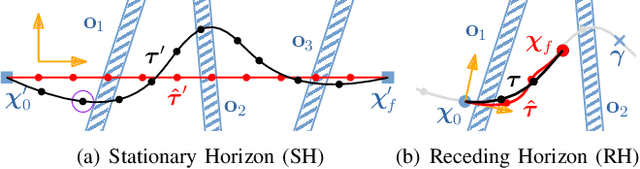
To dynamically traverse challenging terrain, legged robots need to continually perceive and reason about upcoming features, adjust the locations and timings of future footfalls and leverage momentum strategically. We present a pipeline that enables flexibly-parametrized trajectories for perceptive and dynamic quadruped locomotion to be optimized in an online, receding-horizon manner. The initial guess passed to the optimizer affects the computation needed to achieve convergence and the quality of the solution. We consider two methods for generating good guesses. The first is a heuristic initializer which provides a simple guess and requires significant optimization but is nonetheless suitable for adaptation to upcoming terrain. We demonstrate experiments using the ANYmal C quadruped, with fully onboard sensing and computation, to cross obstacles at moderate speeds using this technique. Our second approach uses latent-mode trajectory regression (LMTR) to imitate expert data - while avoiding invalid interpolations between distinct behaviors - such that minimal optimization is needed. This enables high-speed motions that make more expansive use of the robot's capabilities. We demonstrate it on flat ground with the real robot and provide numerical trials that progress toward deployment on terrain. These results illustrate a paradigm for advancing beyond short-horizon dynamic reactions, toward the type of intuitive and adaptive locomotion planning exhibited by animals and humans.
First Steps: Latent-Space Control with Semantic Constraints for Quadruped Locomotion
Jul 03, 2020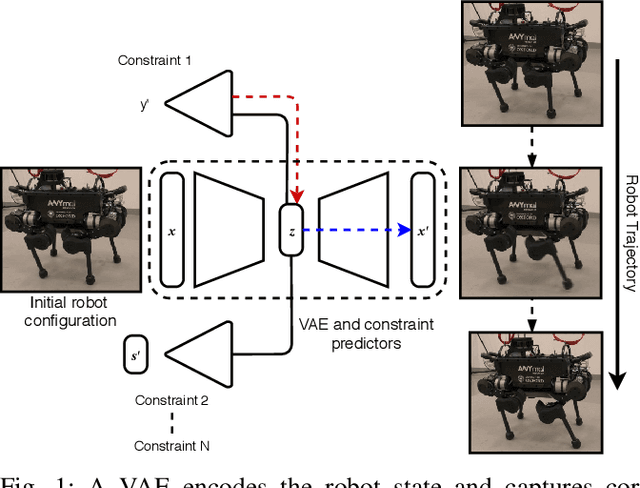

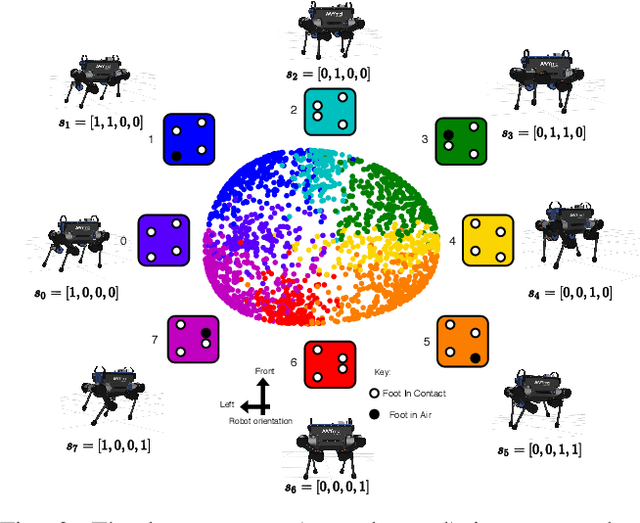
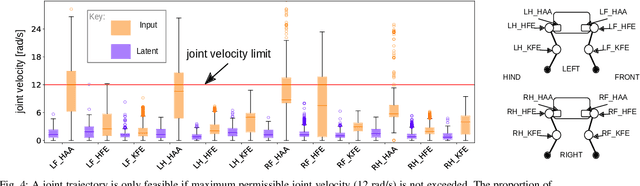
Traditional approaches to quadruped control frequently employ simplified, hand-derived models. This significantly reduces the capability of the robot since its effective kinematic range is curtailed. In addition, kinodynamic constraints are often non-differentiable and difficult to implement in an optimisation approach. In this work, these challenges are addressed by framing quadruped control as optimisation in a structured latent space. A deep generative model captures a statistical representation of feasible joint configurations, whilst complex dynamic and terminal constraints are expressed via high-level, semantic indicators and represented by learned classifiers operating upon the latent space. As a consequence, complex constraints are rendered differentiable and evaluated an order of magnitude faster than analytical approaches. We validate the feasibility of locomotion trajectories optimised using our approach both in simulation and on a real-world ANYmal quadruped. Our results demonstrate that this approach is capable of generating smooth and realisable trajectories. To the best of our knowledge, this is the first time latent space control has been successfully applied to a complex, real robot platform.
Reliable Trajectories for Dynamic Quadrupeds using Analytical Costs and Learned Initializations
Feb 17, 2020
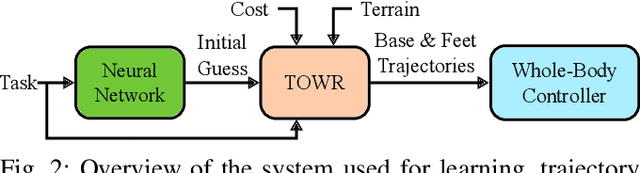
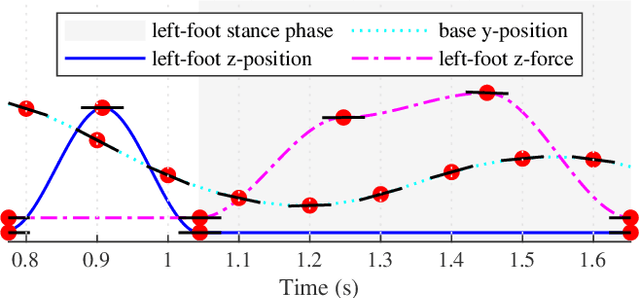
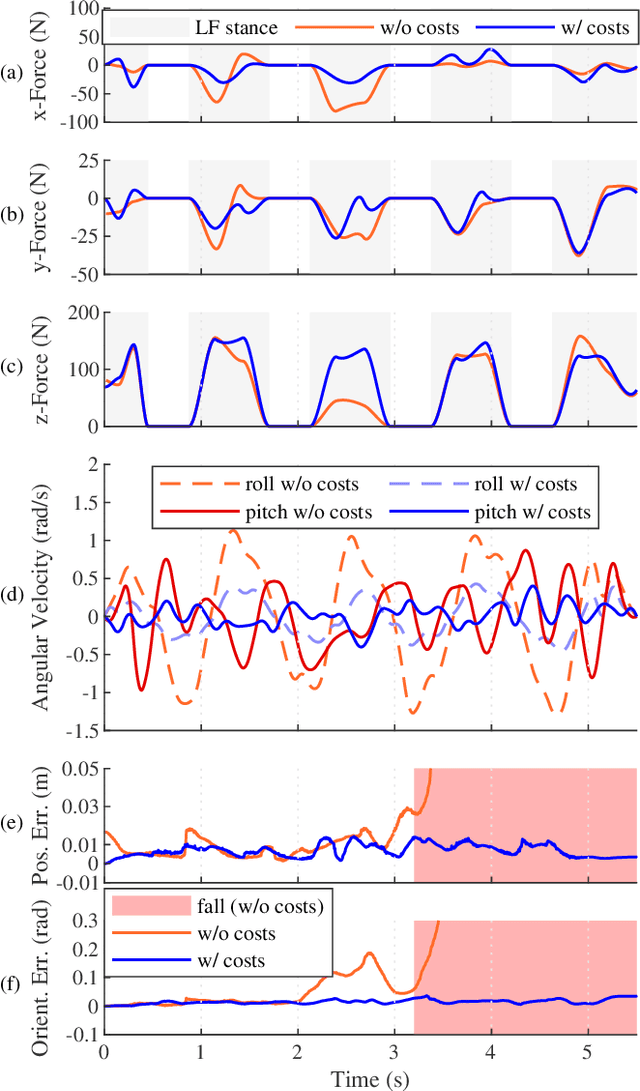
Dynamic traversal of uneven terrain is a major objective in the field of legged robotics. The most recent model predictive control approaches for these systems can generate robust dynamic motion of short duration; however, planning over a longer time horizon may be necessary when navigating complex terrain. A recently-developed framework, Trajectory Optimization for Walking Robots (TOWR), computes such plans but does not guarantee their reliability on real platforms, under uncertainty and perturbations. We extend TOWR with analytical costs to generate trajectories that a state-of-the-art whole-body tracking controller can successfully execute. To reduce online computation time, we implement a learning-based scheme for initialization of the nonlinear program based on offline experience. The execution of trajectories as long as 16 footsteps and 5.5 s over different terrains by a real quadruped demonstrates the effectiveness of the approach on hardware. This work builds toward an online system which can efficiently and robustly replan dynamic trajectories.
Adaptive Tensegrity Locomotion on Rough Terrain via Reinforcement Learning
Sep 27, 2018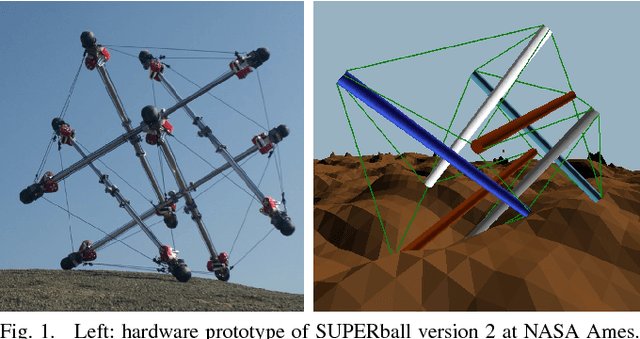
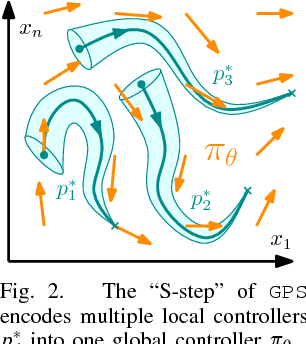
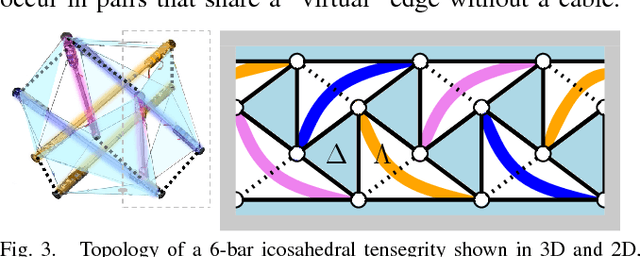
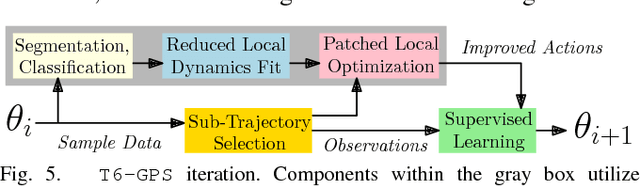
The dynamical properties of tensegrity robots give them appealing ruggedness and adaptability, but present major challenges with respect to locomotion control. Due to high-dimensionality and complex contact responses, data-driven approaches are apt for producing viable feedback policies. Guided Policy Search (GPS), a sample-efficient and model-free hybrid framework for optimization and reinforcement learning, has recently been used to produce periodic locomotion for a spherical 6-bar tensegrity robot on flat or slightly varied surfaces. This work provides an extension to non-periodic locomotion and achieves rough terrain traversal, which requires more broadly varied, adaptive, and non-periodic rover behavior. The contribution alters the control optimization step of GPS, which locally fits and exploits surrogate models of the dynamics, and employs the existing supervised learning step. The proposed solution incorporates new processes to ensure effective local modeling despite the disorganized nature of sample data in rough terrain locomotion. Demonstrations in simulation reveal that the resulting controller sustains the highly adaptive behavior necessary to reliably traverse rough terrain.
Efficient Model Identification for Tensegrity Locomotion
Apr 12, 2018
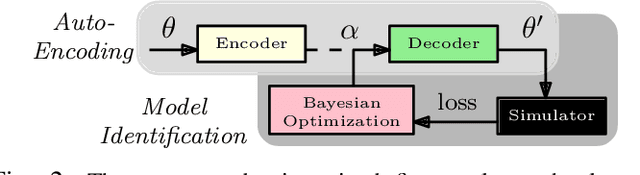
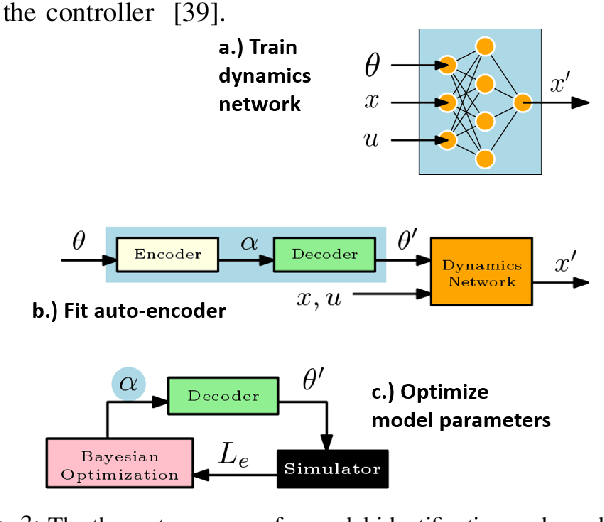
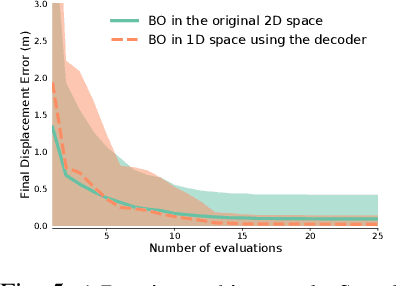
This paper aims to identify in a practical manner unknown physical parameters, such as mechanical models of actuated robot links, which are critical in dynamical robotic tasks. Key features include the use of an off-the-shelf physics engine and the Bayesian optimization framework. The task being considered is locomotion with a high-dimensional, compliant Tensegrity robot. A key insight, in this case, is the need to project the model identification challenge into an appropriate lower dimensional space for efficiency. Comparisons with alternatives indicate that the proposed method can identify the parameters more accurately within the given time budget, which also results in more precise locomotion control.