 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
Approximately Optimal Global Planning for Contact-Rich SE(2) Manipulation on a Graph of Reachable Sets
Jan 15, 2026If we consider human manipulation, it is clear that contact-rich manipulation (CRM)-the ability to use any surface of the manipulator to make contact with objects-can be far more efficient and natural than relying solely on end-effectors (i.e., fingertips). However, state-of-the-art model-based planners for CRM are still focused on feasibility rather than optimality, limiting their ability to fully exploit CRM's advantages. We introduce a new paradigm that computes approximately optimal manipulator plans. This approach has two phases. Offline, we construct a graph of mutual reachable sets, where each set contains all object orientations reachable from a starting object orientation and grasp. Online, we plan over this graph, effectively computing and sequencing local plans for globally optimized motion. On a challenging, representative contact-rich task, our approach outperforms a leading planner, reducing task cost by 61%. It also achieves a 91% success rate across 250 queries and maintains sub-minute query times, ultimately demonstrating that globally optimized contact-rich manipulation is now practical for real-world tasks.
SAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
Dec 14, 2025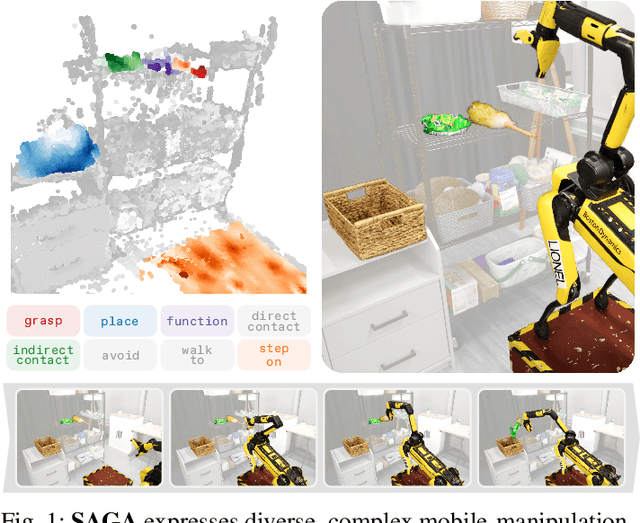
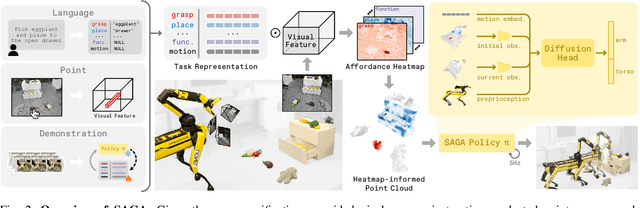
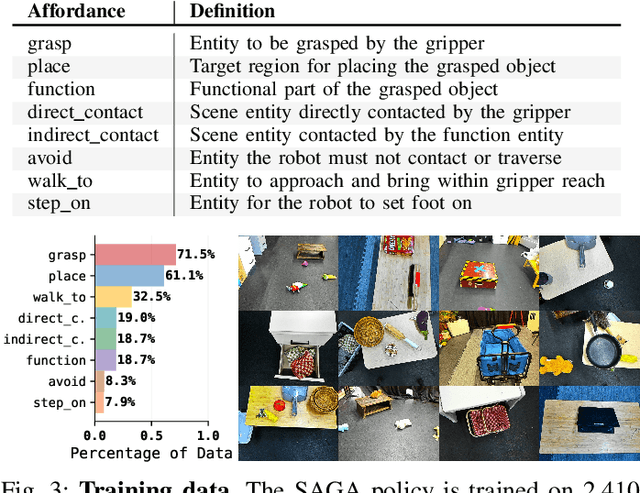
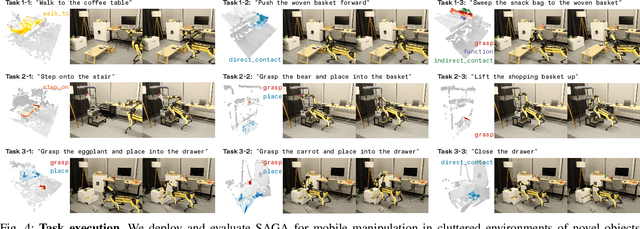
We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot's visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
Versatile Loco-Manipulation through Flexible Interlimb Coordination
Jun 09, 2025The ability to flexibly leverage limbs for loco-manipulation is essential for enabling autonomous robots to operate in unstructured environments. Yet, prior work on loco-manipulation is often constrained to specific tasks or predetermined limb configurations. In this work, we present Reinforcement Learning for Interlimb Coordination (ReLIC), an approach that enables versatile loco-manipulation through flexible interlimb coordination. The key to our approach is an adaptive controller that seamlessly bridges the execution of manipulation motions and the generation of stable gaits based on task demands. Through the interplay between two controller modules, ReLIC dynamically assigns each limb for manipulation or locomotion and robustly coordinates them to achieve the task success. Using efficient reinforcement learning in simulation, ReLIC learns to perform stable gaits in accordance with the manipulation goals in the real world. To solve diverse and complex tasks, we further propose to interface the learned controller with different types of task specifications, including target trajectories, contact points, and natural language instructions. Evaluated on 12 real-world tasks that require diverse and complex coordination patterns, ReLIC demonstrates its versatility and robustness by achieving a success rate of 78.9% on average. Videos and code can be found at https://relic-locoman.github.io/.
ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis
Apr 10, 2025While recent work in scene reconstruction and understanding has made strides in grounding natural language to physical 3D environments, it is still challenging to ground abstract, high-level instructions to a 3D scene. High-level instructions might not explicitly invoke semantic elements in the scene, and even the process of breaking a high-level task into a set of more concrete subtasks, a process called hierarchical task analysis, is environment-dependent. In this work, we propose ASHiTA, the first framework that generates a task hierarchy grounded to a 3D scene graph by breaking down high-level tasks into grounded subtasks. ASHiTA alternates LLM-assisted hierarchical task analysis, to generate the task breakdown, with task-driven 3D scene graph construction to generate a suitable representation of the environment. Our experiments show that ASHiTA performs significantly better than LLM baselines in breaking down high-level tasks into environment-dependent subtasks and is additionally able to achieve grounding performance comparable to state-of-the-art methods.
Physics-Driven Data Generation for Contact-Rich Manipulation via Trajectory Optimization
Feb 27, 2025



We present a low-cost data generation pipeline that integrates physics-based simulation, human demonstrations, and model-based planning to efficiently generate large-scale, high-quality datasets for contact-rich robotic manipulation tasks. Starting with a small number of embodiment-flexible human demonstrations collected in a virtual reality simulation environment, the pipeline refines these demonstrations using optimization-based kinematic retargeting and trajectory optimization to adapt them across various robot embodiments and physical parameters. This process yields a diverse, physically consistent dataset that enables cross-embodiment data transfer, and offers the potential to reuse legacy datasets collected under different hardware configurations or physical parameters. We validate the pipeline's effectiveness by training diffusion policies from the generated datasets for challenging contact-rich manipulation tasks across multiple robot embodiments, including a floating Allegro hand and bimanual robot arms. The trained policies are deployed zero-shot on hardware for bimanual iiwa arms, achieving high success rates with minimal human input. Project website: https://lujieyang.github.io/physicsgen/.
Should We Learn Contact-Rich Manipulation Policies from Sampling-Based Planners?
Dec 12, 2024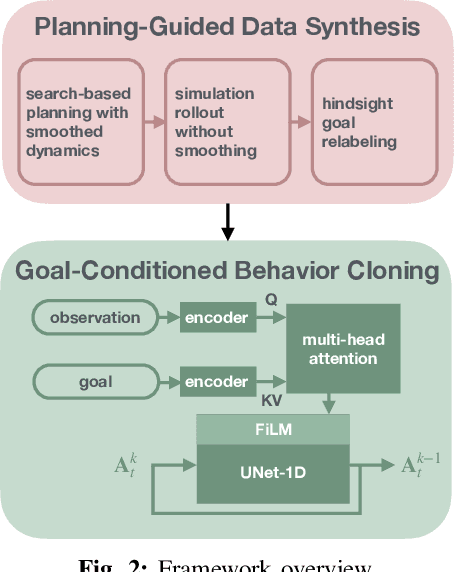
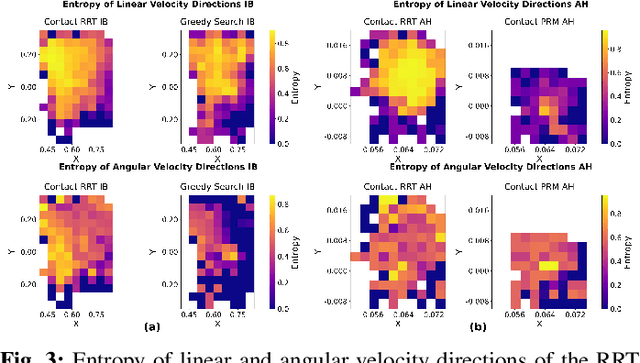

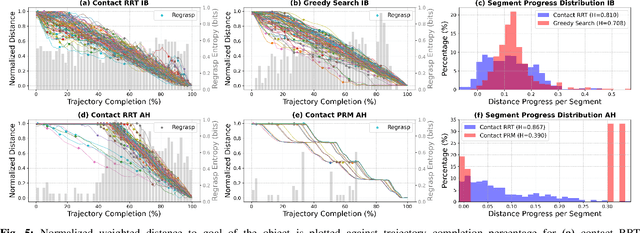
The tremendous success of behavior cloning (BC) in robotic manipulation has been largely confined to tasks where demonstrations can be effectively collected through human teleoperation. However, demonstrations for contact-rich manipulation tasks that require complex coordination of multiple contacts are difficult to collect due to the limitations of current teleoperation interfaces. We investigate how to leverage model-based planning and optimization to generate training data for contact-rich dexterous manipulation tasks. Our analysis reveals that popular sampling-based planners like rapidly exploring random tree (RRT), while efficient for motion planning, produce demonstrations with unfavorably high entropy. This motivates modifications to our data generation pipeline that prioritizes demonstration consistency while maintaining solution diversity. Combined with a diffusion-based goal-conditioned BC approach, our method enables effective policy learning and zero-shot transfer to hardware for two challenging contact-rich manipulation tasks.
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
Dec 03, 2024



Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/
Is Linear Feedback on Smoothed Dynamics Sufficient for Stabilizing Contact-Rich Plans?
Nov 14, 2024



Designing planners and controllers for contact-rich manipulation is extremely challenging as contact violates the smoothness conditions that many gradient-based controller synthesis tools assume. Contact smoothing approximates a non-smooth system with a smooth one, allowing one to use these synthesis tools more effectively. However, applying classical control synthesis methods to smoothed contact dynamics remains relatively under-explored. This paper analyzes the efficacy of linear controller synthesis using differential simulators based on contact smoothing. We introduce natural baselines for leveraging contact smoothing to compute (a) open-loop plans robust to uncertain conditions and/or dynamics, and (b) feedback gains to stabilize around open-loop plans. Using robotic bimanual whole-body manipulation as a testbed, we perform extensive empirical experiments on over 300 trajectories and analyze why LQR seems insufficient for stabilizing contact-rich plans. The video summarizing this paper and hardware experiments is found here: https://youtu.be/HLaKi6qbwQg?si=_zCAmBBD6rGSitm9.
NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN
Nov 12, 2024



Landmark-based navigation (e.g. go to the wooden desk) and relative positional navigation (e.g. move 5 meters forward) are distinct navigation challenges solved very differently in existing robotics navigation methodology. We present a new dataset, OC-VLN, in order to distinctly evaluate grounding object-centric natural language navigation instructions in a method for performing landmark-based navigation. We also propose Natural Language grounded SLAM (NL-SLAM), a method to ground natural language instruction to robot observations and poses. We actively perform NL-SLAM in order to follow object-centric natural language navigation instructions. Our methods leverage pre-trained vision and language foundation models and require no task-specific training. We construct two strong baselines from state-of-the-art methods on related tasks, Object Goal Navigation and Vision Language Navigation, and we show that our approach, NL-SLAM, outperforms these baselines across all our metrics of success on OC-VLN. Finally, we successfully demonstrate the effectiveness of NL-SLAM for performing navigation instruction following in the real world on a Boston Dynamics Spot robot.