 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
AdaptManip: Learning Adaptive Whole-Body Object Lifting and Delivery with Online Recurrent State Estimation
Feb 16, 2026This paper presents Adaptive Whole-body Loco-Manipulation, AdaptManip, a fully autonomous framework for humanoid robots to perform integrated navigation, object lifting, and delivery. Unlike prior imitation learning-based approaches that rely on human demonstrations and are often brittle to disturbances, AdaptManip aims to train a robust loco-manipulation policy via reinforcement learning without human demonstrations or teleoperation data. The proposed framework consists of three coupled components: (1) a recurrent object state estimator that tracks the manipulated object in real time under limited field-of-view and occlusions; (2) a whole-body base policy for robust locomotion with residual manipulation control for stable object lifting and delivery; and (3) a LiDAR-based robot global position estimator that provides drift-robust localization. All components are trained in simulation using reinforcement learning and deployed on real hardware in a zero-shot manner. Experimental results show that AdaptManip significantly outperforms baseline methods, including imitation learning-based approaches, in adaptability and overall success rate, while accurate object state estimation improves manipulation performance even under occlusion. We further demonstrate fully autonomous real-world navigation, object lifting, and delivery on a humanoid robot.
Jacta: A Versatile Planner for Learning Dexterous and Whole-body Manipulation
Aug 02, 2024



Robotic manipulation is challenging due to discontinuous dynamics, as well as high-dimensional state and action spaces. Data-driven approaches that succeed in manipulation tasks require large amounts of data and expert demonstrations, typically from humans. Existing manipulation planners are restricted to specific systems and often depend on specialized algorithms for using demonstration. Therefore, we introduce a flexible motion planner tailored to dexterous and whole-body manipulation tasks. Our planner creates readily usable demonstrations for reinforcement learning algorithms, eliminating the need for additional training pipeline complexities. With this approach, we can efficiently learn policies for complex manipulation tasks, where traditional reinforcement learning alone only makes little progress. Furthermore, we demonstrate that learned policies are transferable to real robotic systems for solving complex dexterous manipulation tasks.
On Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning
Mar 23, 2023As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Relax, it doesn't matter how you get there: A new self-supervised approach for multi-timescale behavior analysis
Mar 15, 2023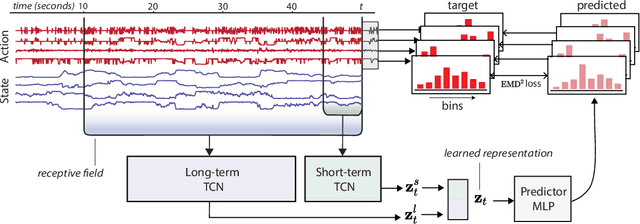

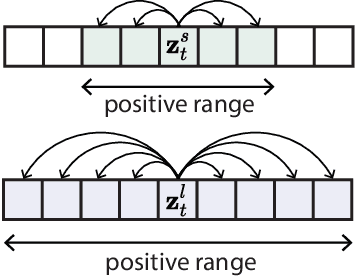
Natural behavior consists of dynamics that are complex and unpredictable, especially when trying to predict many steps into the future. While some success has been found in building representations of behavior under constrained or simplified task-based conditions, many of these models cannot be applied to free and naturalistic settings where behavior becomes increasingly hard to model. In this work, we develop a multi-task representation learning model for behavior that combines two novel components: (i) An action prediction objective that aims to predict the distribution of actions over future timesteps, and (ii) A multi-scale architecture that builds separate latent spaces to accommodate short- and long-term dynamics. After demonstrating the ability of the method to build representations of both local and global dynamics in realistic robots in varying environments and terrains, we apply our method to the MABe 2022 Multi-agent behavior challenge, where our model ranks 1st overall and on all global tasks, and 1st or 2nd on 7 out of 9 frame-level tasks. In all of these cases, we show that our model can build representations that capture the many different factors that drive behavior and solve a wide range of downstream tasks.
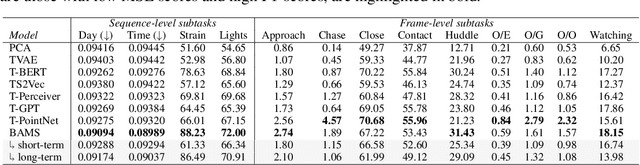
Learning Behavior Representations Through Multi-Timescale Bootstrapping
Jun 14, 2022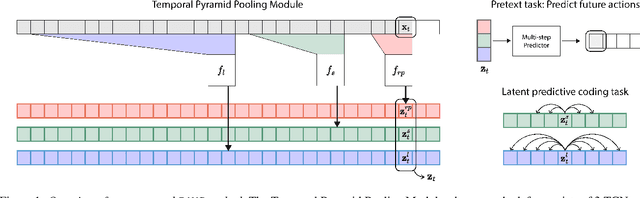
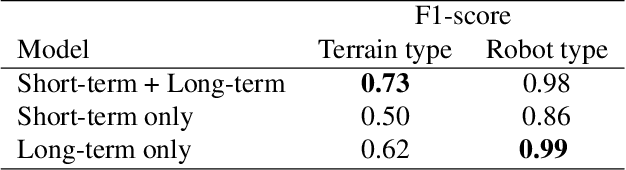
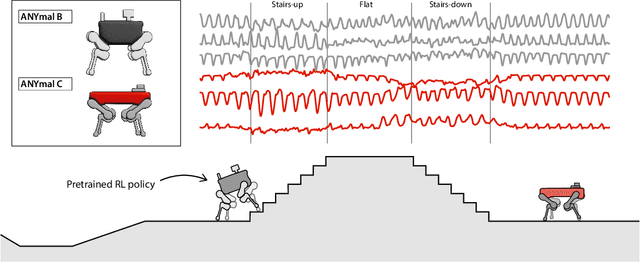
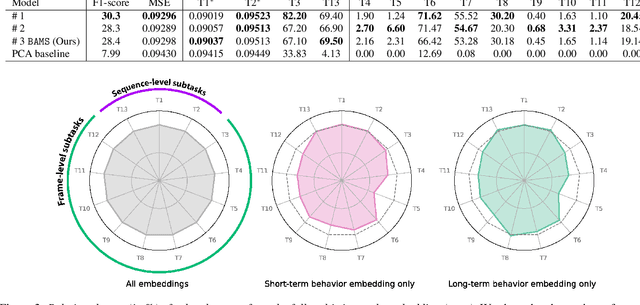
Natural behavior consists of dynamics that are both unpredictable, can switch suddenly, and unfold over many different timescales. While some success has been found in building representations of behavior under constrained or simplified task-based conditions, many of these models cannot be applied to free and naturalistic settings due to the fact that they assume a single scale of temporal dynamics. In this work, we introduce Bootstrap Across Multiple Scales (BAMS), a multi-scale representation learning model for behavior: we combine a pooling module that aggregates features extracted over encoders with different temporal receptive fields, and design a set of latent objectives to bootstrap the representations in each respective space to encourage disentanglement across different timescales. We first apply our method on a dataset of quadrupeds navigating in different terrain types, and show that our model captures the temporal complexity of behavior. We then apply our method to the MABe 2022 Multi-agent behavior challenge, where our model ranks 3rd overall and 1st on two subtasks, and show the importance of incorporating multi-timescales when analyzing behavior.
Human Motion Control of Quadrupedal Robots using Deep Reinforcement Learning
Apr 28, 2022
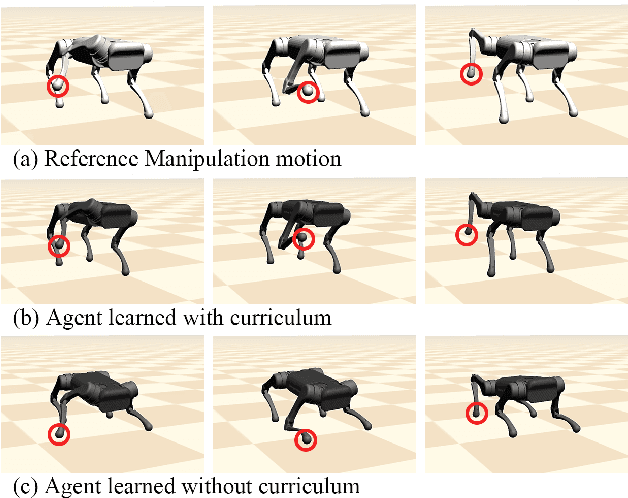


A motion-based control interface promises flexible robot operations in dangerous environments by combining user intuitions with the robot's motor capabilities. However, designing a motion interface for non-humanoid robots, such as quadrupeds or hexapods, is not straightforward because different dynamics and control strategies govern their movements. We propose a novel motion control system that allows a human user to operate various motor tasks seamlessly on a quadrupedal robot. We first retarget the captured human motion into the corresponding robot motion with proper semantics using supervised learning and post-processing techniques. Then we apply the motion imitation learning with curriculum learning to develop a control policy that can track the given retargeted reference. We further improve the performance of both motion retargeting and motion imitation by training a set of experts. As we demonstrate, a user can execute various motor tasks using our system, including standing, sitting, tilting, manipulating, walking, and turning, on simulated and real quadrupeds. We also conduct a set of studies to analyze the performance gain induced by each component.
Learning to Navigate Sidewalks in Outdoor Environments
Sep 12, 2021
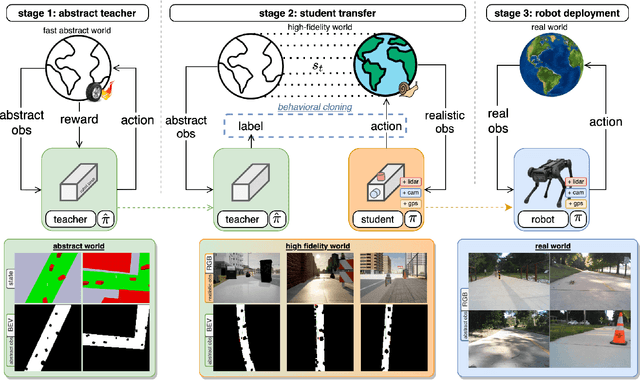
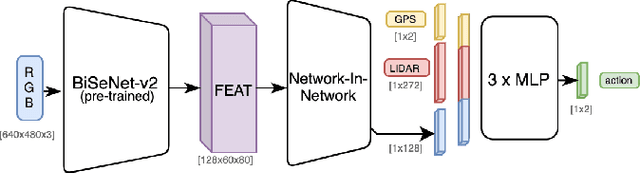
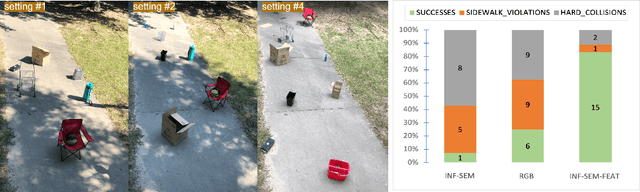
Outdoor navigation on sidewalks in urban environments is the key technology behind important human assistive applications, such as last-mile delivery or neighborhood patrol. This paper aims to develop a quadruped robot that follows a route plan generated by public map services, while remaining on sidewalks and avoiding collisions with obstacles and pedestrians. We devise a two-staged learning framework, which first trains a teacher agent in an abstract world with privileged ground-truth information, and then applies Behavior Cloning to teach the skills to a student agent who only has access to realistic sensors. The main research effort of this paper focuses on overcoming challenges when deploying the student policy on a quadruped robot in the real world. We propose methodologies for designing sensing modalities, network architectures, and training procedures to enable zero-shot policy transfer to unstructured and dynamic real outdoor environments. We evaluate our learning framework on a quadrupedal robot navigating sidewalks in the city of Atlanta, USA. Using the learned navigation policy and its onboard sensors, the robot is able to walk 3.2 kilometers with a limited number of human interventions.
Learning Human Search Behavior from Egocentric Visual Inputs
Nov 06, 2020
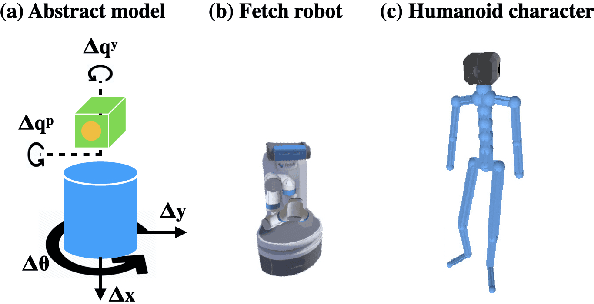
"Looking for things" is a mundane but critical task we repeatedly carry on in our daily life. We introduce a method to develop a human character capable of searching for a randomly located target object in a detailed 3D scene using its locomotion capability and egocentric vision perception represented as RGBD images. By depriving the privileged 3D information from the human character, it is forced to move and look around simultaneously to account for the restricted sensing capability, resulting in natural navigation and search behaviors. Our method consists of two components: 1) a search control policy based on an abstract character model, and 2) an online replanning control module for synthesizing detailed kinematic motion based on the trajectories planned by the search policy. We demonstrate that the combined techniques enable the character to effectively find often occluded household items in indoor environments. The same search policy can be applied to different full-body characters without the need for retraining. We evaluate our method quantitatively by testing it on randomly generated scenarios. Our work is a first step toward creating intelligent virtual agents with humanlike behaviors driven by onboard sensors, paving the road toward future robotic applications.
A Few Shot Adaptation of Visual Navigation Skills to New Observations using Meta-Learning
Nov 06, 2020
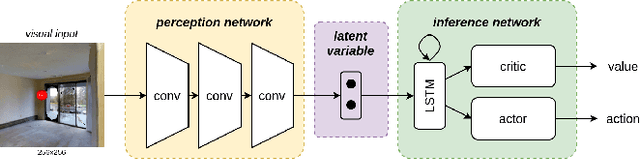
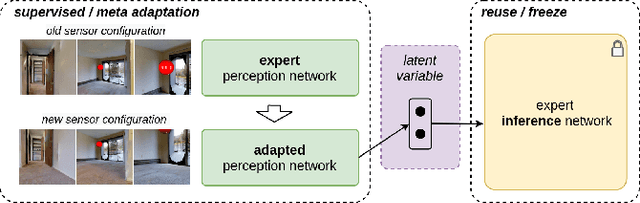
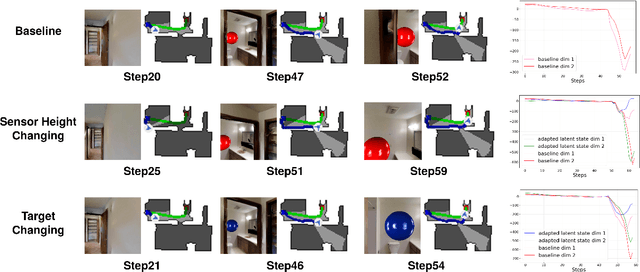
Target-driven visual navigation is a challenging problem that requires a robot to find the goal using only visual inputs. Many researchers have demonstrated promising results using deep reinforcement learning (deep RL) on various robotic platforms, but typical end-to-end learning is known for its poor extrapolation capability to new scenarios. Therefore, learning a navigation policy for a new robot with a new sensor configuration or a new target still remains a challenging problem. In this paper, we introduce a learning algorithm that enables rapid adaptation to new sensor configurations or target objects with a few shots. We design a policy architecture with latent features between perception and inference networks and quickly adapt the perception network via meta-learning while freezing the inference network. Our experiments show that our algorithm adapts the learned navigation policy with only three shots for unseen situations with different sensor configurations or different target colors. We also analyze the proposed algorithm by investigating various hyperparameters.