 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable, real-time neural decoding with hybrid state-space models
Jun 05, 2025Real-time decoding of neural activity is central to neuroscience and neurotechnology applications, from closed-loop experiments to brain-computer interfaces, where models are subject to strict latency constraints. Traditional methods, including simple recurrent neural networks, are fast and lightweight but often struggle to generalize to unseen data. In contrast, recent Transformer-based approaches leverage large-scale pretraining for strong generalization performance, but typically have much larger computational requirements and are not always suitable for low-resource or real-time settings. To address these shortcomings, we present POSSM, a novel hybrid architecture that combines individual spike tokenization via a cross-attention module with a recurrent state-space model (SSM) backbone to enable (1) fast and causal online prediction on neural activity and (2) efficient generalization to new sessions, individuals, and tasks through multi-dataset pretraining. We evaluate POSSM's decoding performance and inference speed on intracortical decoding of monkey motor tasks, and show that it extends to clinical applications, namely handwriting and speech decoding in human subjects. Notably, we demonstrate that pretraining on monkey motor-cortical recordings improves decoding performance on the human handwriting task, highlighting the exciting potential for cross-species transfer. In all of these tasks, we find that POSSM achieves decoding accuracy comparable to state-of-the-art Transformers, at a fraction of the inference cost (up to 9x faster on GPU). These results suggest that hybrid SSMs are a promising approach to bridging the gap between accuracy, inference speed, and generalization when training neural decoders for real-time, closed-loop applications.
Neural Encoding and Decoding at Scale
Apr 14, 2025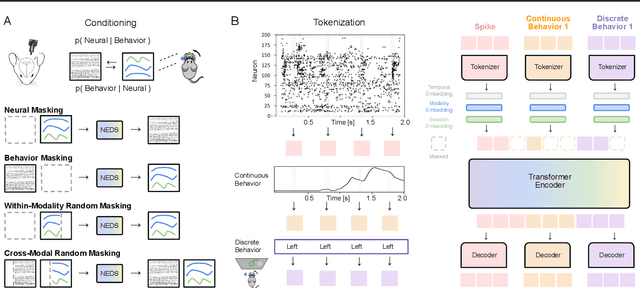

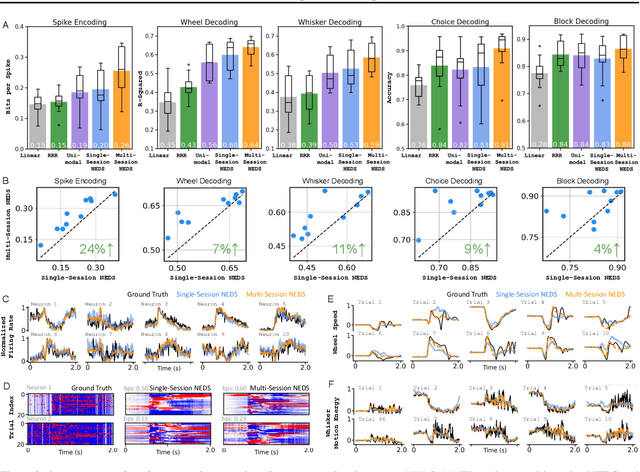
Recent work has demonstrated that large-scale, multi-animal models are powerful tools for characterizing the relationship between neural activity and behavior. Current large-scale approaches, however, focus exclusively on either predicting neural activity from behavior (encoding) or predicting behavior from neural activity (decoding), limiting their ability to capture the bidirectional relationship between neural activity and behavior. To bridge this gap, we introduce a multimodal, multi-task model that enables simultaneous Neural Encoding and Decoding at Scale (NEDS). Central to our approach is a novel multi-task-masking strategy, which alternates between neural, behavioral, within-modality, and cross-modality masking. We pretrain our method on the International Brain Laboratory (IBL) repeated site dataset, which includes recordings from 83 animals performing the same visual decision-making task. In comparison to other large-scale models, we demonstrate that NEDS achieves state-of-the-art performance for both encoding and decoding when pretrained on multi-animal data and then fine-tuned on new animals. Surprisingly, NEDS's learned embeddings exhibit emergent properties: even without explicit training, they are highly predictive of the brain regions in each recording. Altogether, our approach is a step towards a foundation model of the brain that enables seamless translation between neural activity and behavior.
Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution
Jul 23, 2024
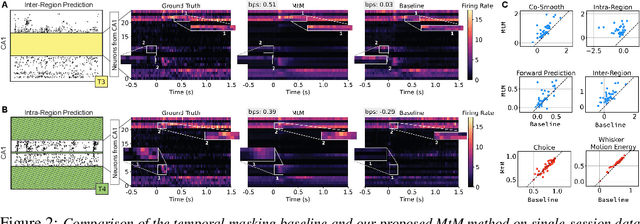
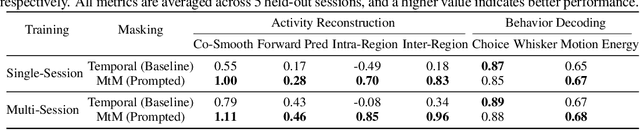

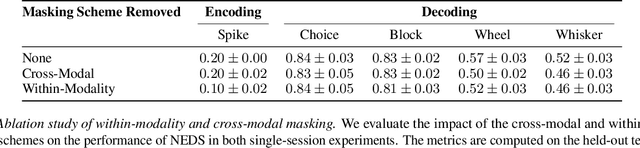
Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.
GraphFM: A Scalable Framework for Multi-Graph Pretraining
Jul 16, 2024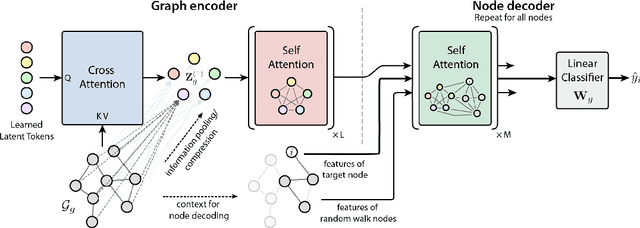
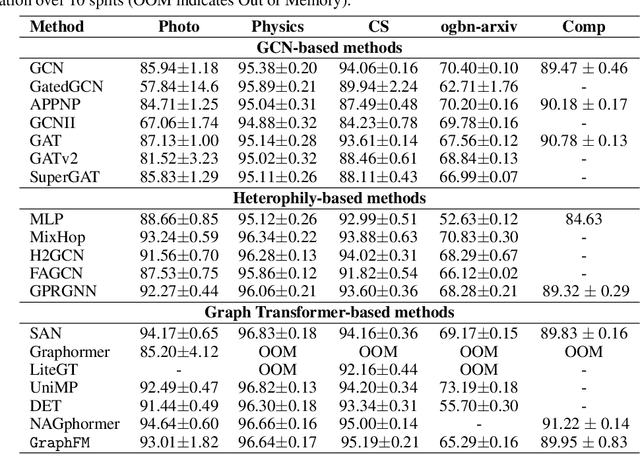
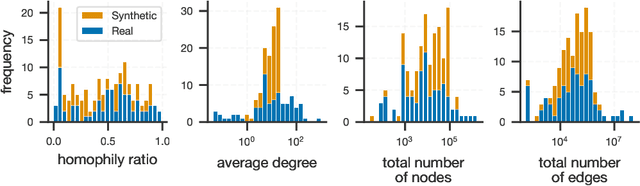
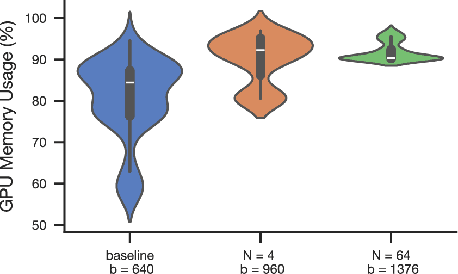
Graph neural networks are typically trained on individual datasets, often requiring highly specialized models and extensive hyperparameter tuning. This dataset-specific approach arises because each graph dataset often has unique node features and diverse connectivity structures, making it difficult to build a generalist model. To address these challenges, we introduce a scalable multi-graph multi-task pretraining approach specifically tailored for node classification tasks across diverse graph datasets from different domains. Our method, Graph Foundation Model (GraphFM), leverages a Perceiver-based encoder that employs learned latent tokens to compress domain-specific features into a common latent space. This approach enhances the model's ability to generalize across different graphs and allows for scaling across diverse data. We demonstrate the efficacy of our approach by training a model on 152 different graph datasets comprising over 7.4 million nodes and 189 million edges, establishing the first set of scaling laws for multi-graph pretraining on datasets spanning many domains (e.g., molecules, citation and product graphs). Our results show that pretraining on a diverse array of real and synthetic graphs improves the model's adaptability and stability, while performing competitively with state-of-the-art specialist models. This work illustrates that multi-graph pretraining can significantly reduce the burden imposed by the current graph training paradigm, unlocking new capabilities for the field of graph neural networks by creating a single generalist model that performs competitively across a wide range of datasets and tasks.
A Unified, Scalable Framework for Neural Population Decoding
Oct 24, 2023



Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both model size and datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale.
Half-Hop: A graph upsampling approach for slowing down message passing
Aug 17, 2023
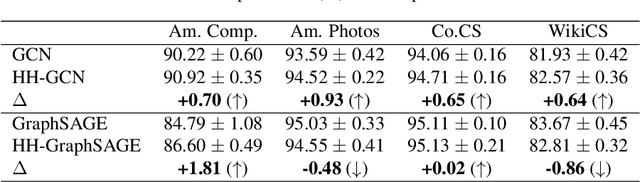

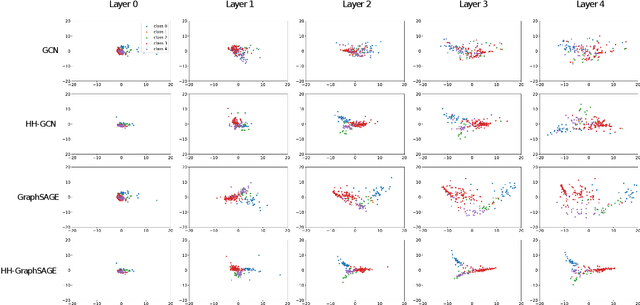
Message passing neural networks have shown a lot of success on graph-structured data. However, there are many instances where message passing can lead to over-smoothing or fail when neighboring nodes belong to different classes. In this work, we introduce a simple yet general framework for improving learning in message passing neural networks. Our approach essentially upsamples edges in the original graph by adding "slow nodes" at each edge that can mediate communication between a source and a target node. Our method only modifies the input graph, making it plug-and-play and easy to use with existing models. To understand the benefits of slowing down message passing, we provide theoretical and empirical analyses. We report results on several supervised and self-supervised benchmarks, and show improvements across the board, notably in heterophilic conditions where adjacent nodes are more likely to have different labels. Finally, we show how our approach can be used to generate augmentations for self-supervised learning, where slow nodes are randomly introduced into different edges in the graph to generate multi-scale views with variable path lengths.
Relax, it doesn't matter how you get there: A new self-supervised approach for multi-timescale behavior analysis
Mar 15, 2023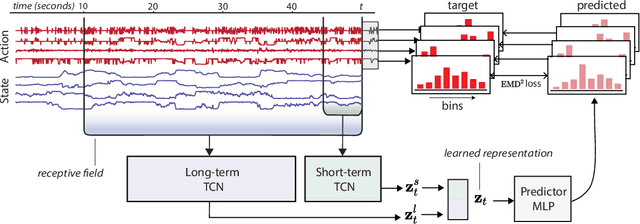

Natural behavior consists of dynamics that are complex and unpredictable, especially when trying to predict many steps into the future. While some success has been found in building representations of behavior under constrained or simplified task-based conditions, many of these models cannot be applied to free and naturalistic settings where behavior becomes increasingly hard to model. In this work, we develop a multi-task representation learning model for behavior that combines two novel components: (i) An action prediction objective that aims to predict the distribution of actions over future timesteps, and (ii) A multi-scale architecture that builds separate latent spaces to accommodate short- and long-term dynamics. After demonstrating the ability of the method to build representations of both local and global dynamics in realistic robots in varying environments and terrains, we apply our method to the MABe 2022 Multi-agent behavior challenge, where our model ranks 1st overall and on all global tasks, and 1st or 2nd on 7 out of 9 frame-level tasks. In all of these cases, we show that our model can build representations that capture the many different factors that drive behavior and solve a wide range of downstream tasks.
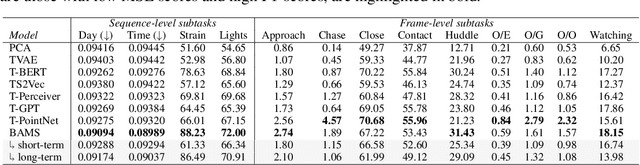
Learning signatures of decision making from many individuals playing the same game
Feb 21, 2023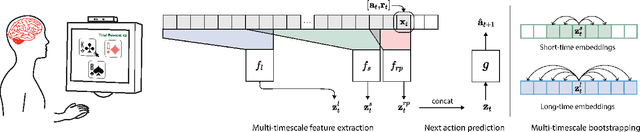
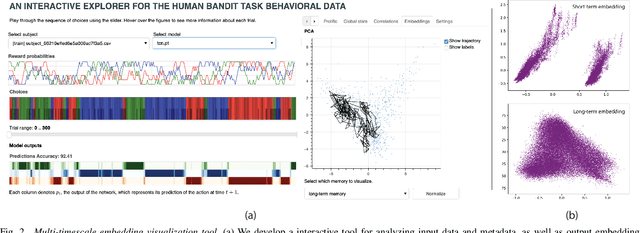


Human behavior is incredibly complex and the factors that drive decision making--from instinct, to strategy, to biases between individuals--often vary over multiple timescales. In this paper, we design a predictive framework that learns representations to encode an individual's 'behavioral style', i.e. long-term behavioral trends, while simultaneously predicting future actions and choices. The model explicitly separates representations into three latent spaces: the recent past space, the short-term space, and the long-term space where we hope to capture individual differences. To simultaneously extract both global and local variables from complex human behavior, our method combines a multi-scale temporal convolutional network with latent prediction tasks, where we encourage embeddings across the entire sequence, as well as subsets of the sequence, to be mapped to similar points in the latent space. We develop and apply our method to a large-scale behavioral dataset from 1,000 humans playing a 3-armed bandit task, and analyze what our model's resulting embeddings reveal about the human decision making process. In addition to predicting future choices, we show that our model can learn rich representations of human behavior over multiple timescales and provide signatures of differences in individuals.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023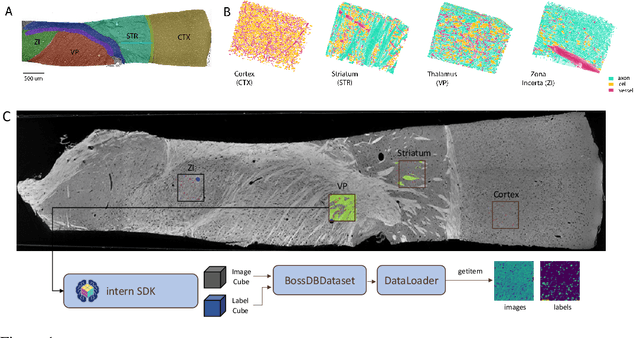
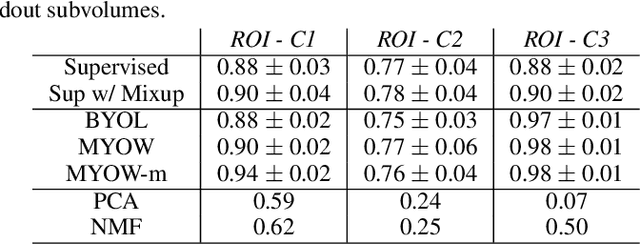

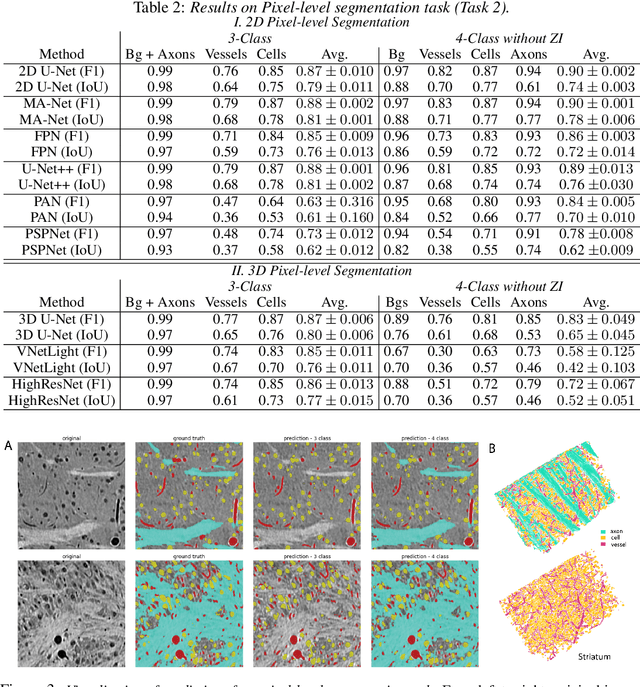
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
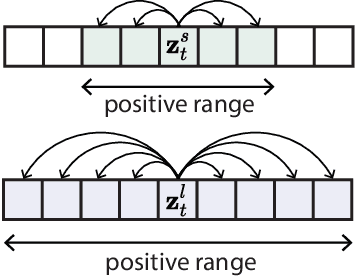
Learning Behavior Representations Through Multi-Timescale Bootstrapping
Jun 14, 2022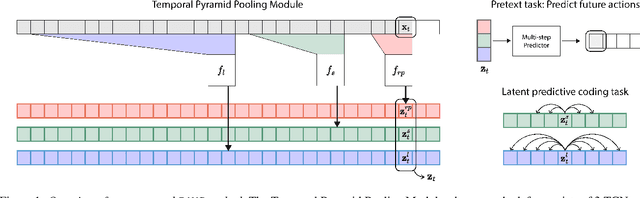
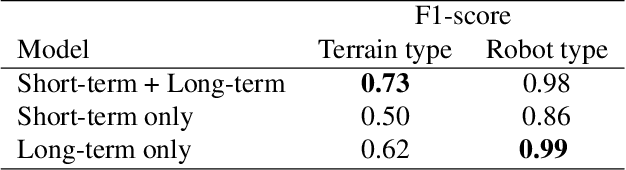
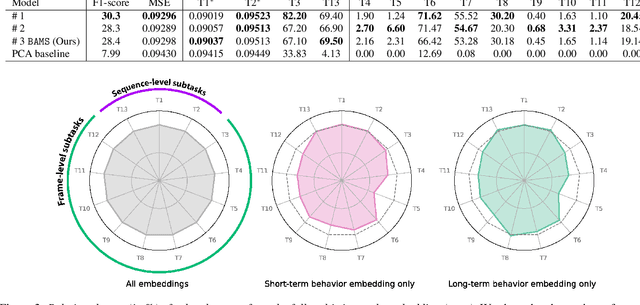
Natural behavior consists of dynamics that are both unpredictable, can switch suddenly, and unfold over many different timescales. While some success has been found in building representations of behavior under constrained or simplified task-based conditions, many of these models cannot be applied to free and naturalistic settings due to the fact that they assume a single scale of temporal dynamics. In this work, we introduce Bootstrap Across Multiple Scales (BAMS), a multi-scale representation learning model for behavior: we combine a pooling module that aggregates features extracted over encoders with different temporal receptive fields, and design a set of latent objectives to bootstrap the representations in each respective space to encourage disentanglement across different timescales. We first apply our method on a dataset of quadrupeds navigating in different terrain types, and show that our model captures the temporal complexity of behavior. We then apply our method to the MABe 2022 Multi-agent behavior challenge, where our model ranks 3rd overall and 1st on two subtasks, and show the importance of incorporating multi-timescales when analyzing behavior.