 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Encoding and Decoding at Scale
Apr 14, 2025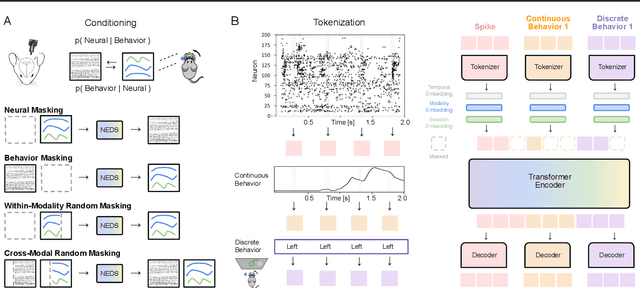

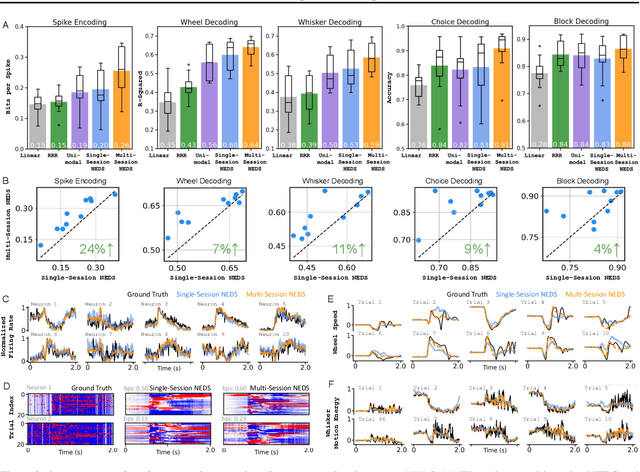
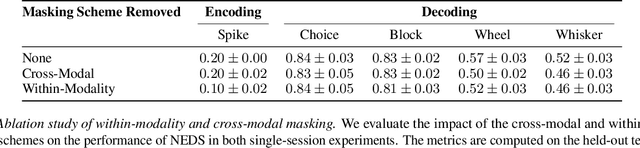
Recent work has demonstrated that large-scale, multi-animal models are powerful tools for characterizing the relationship between neural activity and behavior. Current large-scale approaches, however, focus exclusively on either predicting neural activity from behavior (encoding) or predicting behavior from neural activity (decoding), limiting their ability to capture the bidirectional relationship between neural activity and behavior. To bridge this gap, we introduce a multimodal, multi-task model that enables simultaneous Neural Encoding and Decoding at Scale (NEDS). Central to our approach is a novel multi-task-masking strategy, which alternates between neural, behavioral, within-modality, and cross-modality masking. We pretrain our method on the International Brain Laboratory (IBL) repeated site dataset, which includes recordings from 83 animals performing the same visual decision-making task. In comparison to other large-scale models, we demonstrate that NEDS achieves state-of-the-art performance for both encoding and decoding when pretrained on multi-animal data and then fine-tuned on new animals. Surprisingly, NEDS's learned embeddings exhibit emergent properties: even without explicit training, they are highly predictive of the brain regions in each recording. Altogether, our approach is a step towards a foundation model of the brain that enables seamless translation between neural activity and behavior.
Decoding Visual Experience and Mapping Semantics through Whole-Brain Analysis Using fMRI Foundation Models
Nov 11, 2024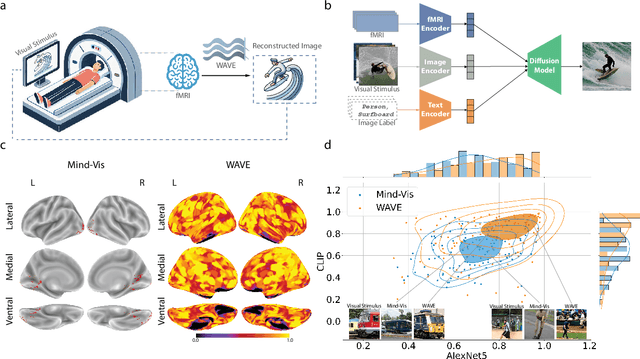



Neural decoding, the process of understanding how brain activity corresponds to different stimuli, has been a primary objective in cognitive sciences. Over the past three decades, advancements in functional Magnetic Resonance Imaging and machine learning have greatly improved our ability to map visual stimuli to brain activity, especially in the visual cortex. Concurrently, research has expanded into decoding more complex processes like language and memory across the whole brain, utilizing techniques to handle greater variability and improve signal accuracy. We argue that "seeing" involves more than just mapping visual stimuli onto the visual cortex; it engages the entire brain, as various emotions and cognitive states can emerge from observing different scenes. In this paper, we develop algorithms to enhance our understanding of visual processes by incorporating whole-brain activation maps while individuals are exposed to visual stimuli. We utilize large-scale fMRI encoders and Image generative models pre-trained on large public datasets, which are then fine-tuned through Image-fMRI contrastive learning. Our models hence can decode visual experience across the entire cerebral cortex, surpassing the traditional confines of the visual cortex. We first compare our method with state-of-the-art approaches to decoding visual processing and show improved predictive semantic accuracy by 43%. A network ablation analysis suggests that beyond the visual cortex, the default mode network contributes most to decoding stimuli, in line with the proposed role of this network in sense-making and semantic processing. Additionally, we implemented zero-shot imagination decoding on an extra validation dataset, achieving a p-value of 0.0206 for mapping the reconstructed images and ground-truth text stimuli, which substantiates the model's capability to capture semantic meanings across various scenarios.
It is Time to Develop an Auditing Framework to Promote Value Aware Chatbots
Sep 03, 2024



The launch of ChatGPT in November 2022 marked the beginning of a new era in AI, the availability of generative AI tools for everyone to use. ChatGPT and other similar chatbots boast a wide range of capabilities from answering student homework questions to creating music and art. Given the large amounts of human data chatbots are built on, it is inevitable that they will inherit human errors and biases. These biases have the potential to inflict significant harm or increase inequity on different subpopulations. Because chatbots do not have an inherent understanding of societal values, they may create new content that is contrary to established norms. Examples of concerning generated content includes child pornography, inaccurate facts, and discriminatory posts. In this position paper, we argue that the speed of advancement of this technology requires us, as computer and data scientists, to mobilize and develop a values-based auditing framework containing a community established standard set of measurements to monitor the health of different chatbots and LLMs. To support our argument, we use a simple audit template to share the results of basic audits we conduct that are focused on measuring potential bias in search engine style tasks, code generation, and story generation. We identify responses from GPT 3.5 and GPT 4 that are both consistent and not consistent with values derived from existing law. While the findings come as no surprise, they do underscore the urgency of developing a robust auditing framework for openly sharing results in a consistent way so that mitigation strategies can be developed by the academic community, government agencies, and companies when our values are not being adhered to. We conclude this paper with recommendations for value-based strategies for improving the technologies.
* arXiv admin note: substantial text overlap with arXiv:2306.07500
Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution
Jul 23, 2024Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.
Adding guardrails to advanced chatbots
Jun 13, 2023Generative AI models continue to become more powerful. The launch of ChatGPT in November 2022 has ushered in a new era of AI. ChatGPT and other similar chatbots have a range of capabilities, from answering student homework questions to creating music and art. There are already concerns that humans may be replaced by chatbots for a variety of jobs. Because of the wide spectrum of data chatbots are built on, we know that they will have human errors and human biases built into them. These biases may cause significant harm and/or inequity toward different subpopulations. To understand the strengths and weakness of chatbot responses, we present a position paper that explores different use cases of ChatGPT to determine the types of questions that are answered fairly and the types that still need improvement. We find that ChatGPT is a fair search engine for the tasks we tested; however, it has biases on both text generation and code generation. We find that ChatGPT is very sensitive to changes in the prompt, where small changes lead to different levels of fairness. This suggests that we need to immediately implement "corrections" or mitigation strategies in order to improve fairness of these systems. We suggest different strategies to improve chatbots and also advocate for an impartial review panel that has access to the model parameters to measure the levels of different types of biases and then recommends safeguards that move toward responses that are less discriminatory and more accurate.
Recurrent Transformer Encoders for Vision-based Estimation of Fatigue and Engagement in Cognitive Training Sessions
Apr 24, 2023
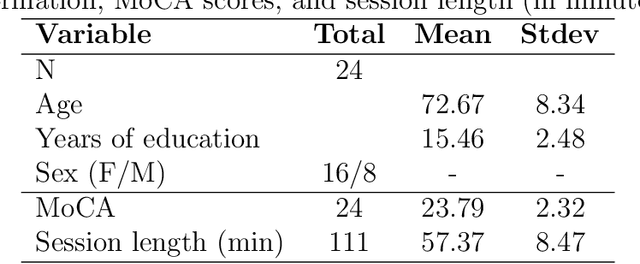
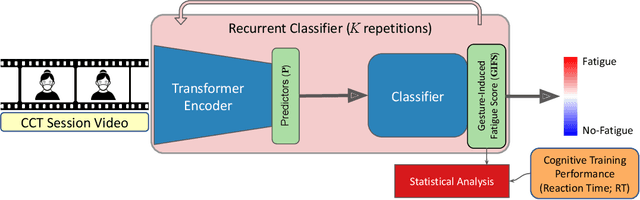
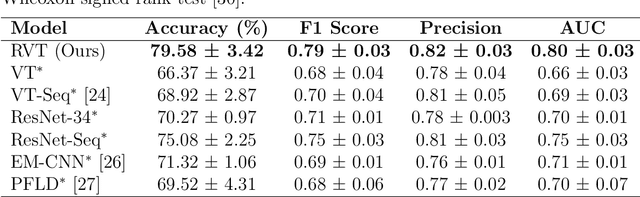
The effectiveness of computerized cognitive training in slowing cognitive decline and brain aging in dementia is often limited by the engagement of participants in the training. Monitoring older users' real-time engagement in domains of attention, motivation, and affect is crucial to understanding the overall effectiveness of such training. In this paper, we propose to predict engagement, quantified via an established mental fatigue measure assessing users' perceived attention, motivation, and affect throughout computerized cognitive training sessions, in older adults with mild cognitive impairment (MCI), by monitoring their real-time video-recorded facial gestures in training sessions. To achieve the goal, we used computer vision, analyzing video frames every 5 seconds to optimize the balance between information retention and data size, and developed a novel Recurrent Video Transformer (RVT). Our RVT model, which combines a clip-wise transformer encoder module and a session-wise Recurrent Neural Network (RNN) classifier, achieved the highest balanced accuracy, F1 score, and precision compared to other state-of-the-art models for both detecting mental fatigue/disengagement cases (binary classification) and rating the level of mental fatigue (multi-class classification). By leveraging dynamic temporal information, the RVT model demonstrates the potential to accurately predict engagement among computerized cognitive training users, which lays the foundation for future work to modulate the level of engagement in computerized cognitive training interventions. The code will be released.