 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Encoding and Decoding at Scale
Apr 14, 2025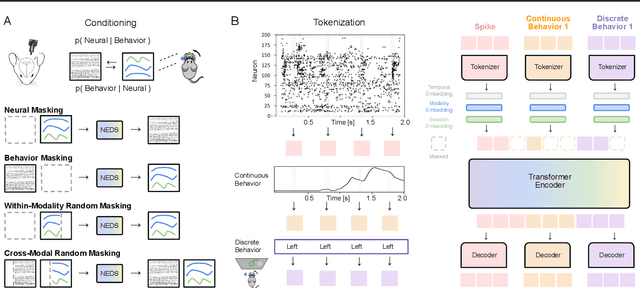

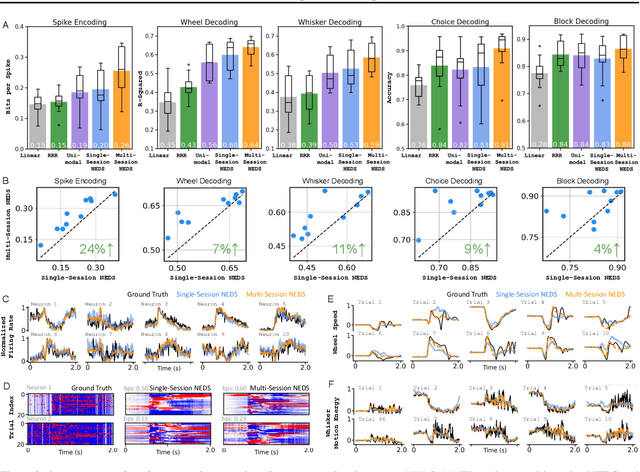
Recent work has demonstrated that large-scale, multi-animal models are powerful tools for characterizing the relationship between neural activity and behavior. Current large-scale approaches, however, focus exclusively on either predicting neural activity from behavior (encoding) or predicting behavior from neural activity (decoding), limiting their ability to capture the bidirectional relationship between neural activity and behavior. To bridge this gap, we introduce a multimodal, multi-task model that enables simultaneous Neural Encoding and Decoding at Scale (NEDS). Central to our approach is a novel multi-task-masking strategy, which alternates between neural, behavioral, within-modality, and cross-modality masking. We pretrain our method on the International Brain Laboratory (IBL) repeated site dataset, which includes recordings from 83 animals performing the same visual decision-making task. In comparison to other large-scale models, we demonstrate that NEDS achieves state-of-the-art performance for both encoding and decoding when pretrained on multi-animal data and then fine-tuned on new animals. Surprisingly, NEDS's learned embeddings exhibit emergent properties: even without explicit training, they are highly predictive of the brain regions in each recording. Altogether, our approach is a step towards a foundation model of the brain that enables seamless translation between neural activity and behavior.
Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution
Jul 23, 2024
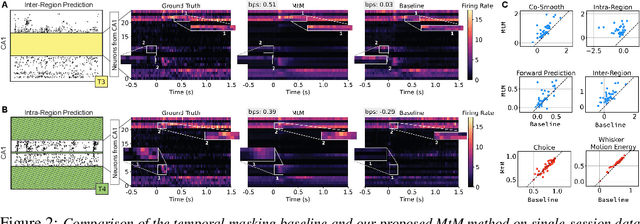
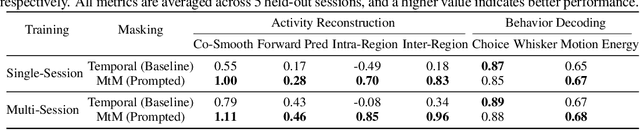

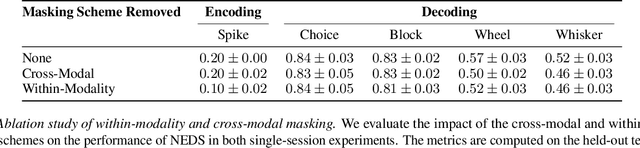
Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.
TimeInf: Time Series Data Contribution via Influence Functions
Jul 23, 2024



Evaluating the contribution of individual data points to a model's prediction is critical for interpreting model predictions and improving model performance. Existing data contribution methods have been applied to various data types, including tabular data, images, and texts; however, their primary focus has been on i.i.d. settings. Despite the pressing need for principled approaches tailored to time series datasets, the problem of estimating data contribution in such settings remains unexplored, possibly due to challenges associated with handling inherent temporal dependencies. This paper introduces TimeInf, a data contribution estimation method for time-series datasets. TimeInf uses influence functions to attribute model predictions to individual time points while preserving temporal structures. Our extensive empirical results demonstrate that TimeInf outperforms state-of-the-art methods in identifying harmful anomalies and helpful time points for forecasting. Additionally, TimeInf offers intuitive and interpretable attributions of data values, allowing us to easily distinguish diverse anomaly patterns through visualizations.
Variational Auto-encoder for Recommender Systems with Exploration-Exploitation
Jun 10, 2020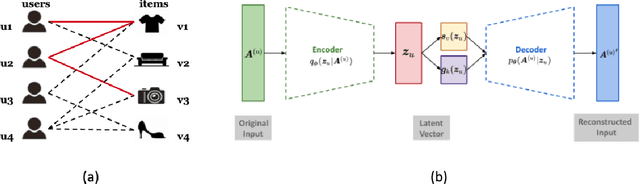
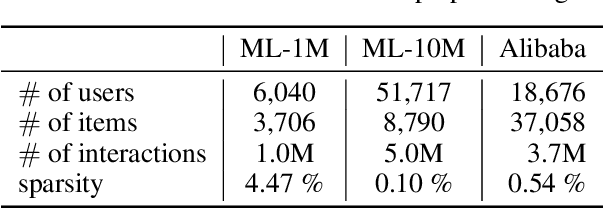
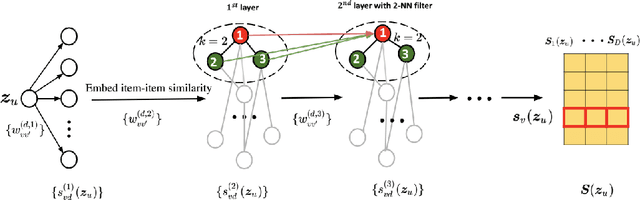

Variational auto-encoder (VAE) is an efficient non-linear latent factor model that has been widely applied in recommender systems (RS). However, a drawback of VAE for RS is their inability of exploration. A good RS is expected to recommend items that are known to enjoy and items that are novel to try. In this work, we introduce an exploitation-exploration motivated VAE (XploVAE) to collaborative filtering. To facilitate personalized recommendations, we construct user-specific subgraphs, which contain the first-order proximity capturing observed user-item interactions for exploitation and the higher-order proximity for exploration. We further develop a hierarchical latent space model to learn the population distribution of the user subgraphs, and learn the personalized item embedding. Empirical experiments prove the effectiveness of our proposed method on various real-world data sets.