 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Encoding and Decoding at Scale
Apr 14, 2025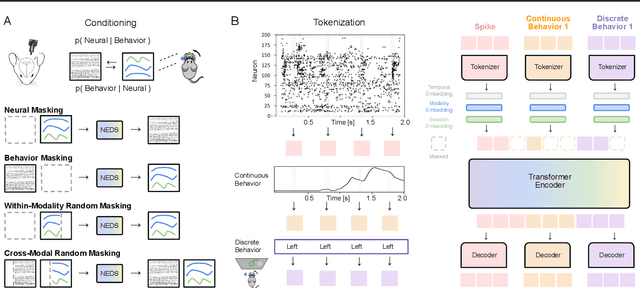

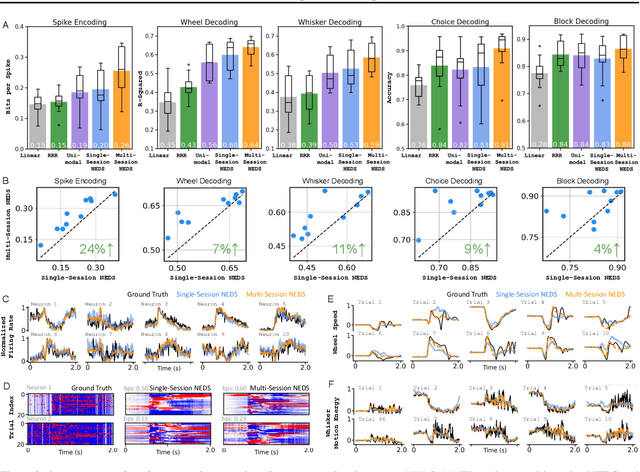
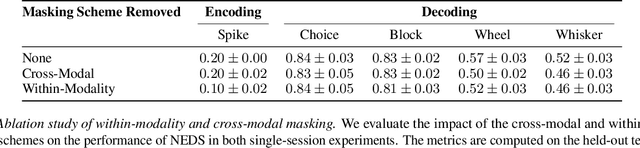
Recent work has demonstrated that large-scale, multi-animal models are powerful tools for characterizing the relationship between neural activity and behavior. Current large-scale approaches, however, focus exclusively on either predicting neural activity from behavior (encoding) or predicting behavior from neural activity (decoding), limiting their ability to capture the bidirectional relationship between neural activity and behavior. To bridge this gap, we introduce a multimodal, multi-task model that enables simultaneous Neural Encoding and Decoding at Scale (NEDS). Central to our approach is a novel multi-task-masking strategy, which alternates between neural, behavioral, within-modality, and cross-modality masking. We pretrain our method on the International Brain Laboratory (IBL) repeated site dataset, which includes recordings from 83 animals performing the same visual decision-making task. In comparison to other large-scale models, we demonstrate that NEDS achieves state-of-the-art performance for both encoding and decoding when pretrained on multi-animal data and then fine-tuned on new animals. Surprisingly, NEDS's learned embeddings exhibit emergent properties: even without explicit training, they are highly predictive of the brain regions in each recording. Altogether, our approach is a step towards a foundation model of the brain that enables seamless translation between neural activity and behavior.
A study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms
Jul 23, 2024



Action segmentation of behavioral videos is the process of labeling each frame as belonging to one or more discrete classes, and is a crucial component of many studies that investigate animal behavior. A wide range of algorithms exist to automatically parse discrete animal behavior, encompassing supervised, unsupervised, and semi-supervised learning paradigms. These algorithms -- which include tree-based models, deep neural networks, and graphical models -- differ widely in their structure and assumptions on the data. Using four datasets spanning multiple species -- fly, mouse, and human -- we systematically study how the outputs of these various algorithms align with manually annotated behaviors of interest. Along the way, we introduce a semi-supervised action segmentation model that bridges the gap between supervised deep neural networks and unsupervised graphical models. We find that fully supervised temporal convolutional networks with the addition of temporal information in the observations perform the best on our supervised metrics across all datasets.