 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms
Jul 23, 2024



Action segmentation of behavioral videos is the process of labeling each frame as belonging to one or more discrete classes, and is a crucial component of many studies that investigate animal behavior. A wide range of algorithms exist to automatically parse discrete animal behavior, encompassing supervised, unsupervised, and semi-supervised learning paradigms. These algorithms -- which include tree-based models, deep neural networks, and graphical models -- differ widely in their structure and assumptions on the data. Using four datasets spanning multiple species -- fly, mouse, and human -- we systematically study how the outputs of these various algorithms align with manually annotated behaviors of interest. Along the way, we introduce a semi-supervised action segmentation model that bridges the gap between supervised deep neural networks and unsupervised graphical models. We find that fully supervised temporal convolutional networks with the addition of temporal information in the observations perform the best on our supervised metrics across all datasets.
SemiMultiPose: A Semi-supervised Multi-animal Pose Estimation Framework
Apr 14, 2022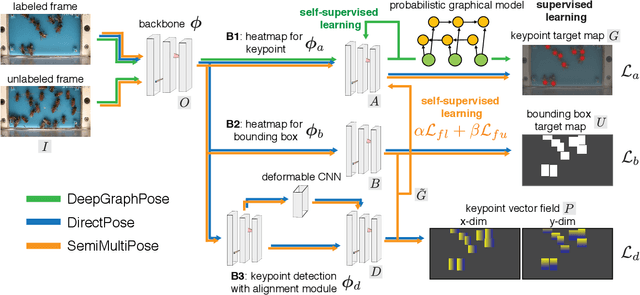


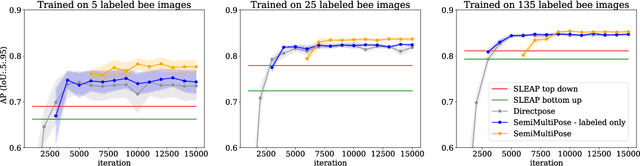
Multi-animal pose estimation is essential for studying animals' social behaviors in neuroscience and neuroethology. Advanced approaches have been proposed to support multi-animal estimation and achieve state-of-the-art performance. However, these models rarely exploit unlabeled data during training even though real world applications have exponentially more unlabeled frames than labeled frames. Manually adding dense annotations for a large number of images or videos is costly and labor-intensive, especially for multiple instances. Given these deficiencies, we propose a novel semi-supervised architecture for multi-animal pose estimation, leveraging the abundant structures pervasive in unlabeled frames in behavior videos to enhance training, which is critical for sparsely-labeled problems. The resulting algorithm will provide superior multi-animal pose estimation results on three animal experiments compared to the state-of-the-art baseline and exhibits more predictive power in sparsely-labeled data regimes.