 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorVLM: Unified Finetuning-Free Behavioral Understanding with Vision-Language Reasoning
Mar 12, 2026Understanding freely moving animal behavior is central to neuroscience, where pose estimation and behavioral understanding form the foundation for linking neural activity to natural actions. Yet both tasks still depend heavily on human annotation or unstable unsupervised pipelines, limiting scalability and reproducibility. We present BehaviorVLM, a unified vision-language framework for pose estimation and behavioral understanding that requires no task-specific finetuning and minimal human labeling by guiding pretrained Vision-Language Models (VLMs) through detailed, explicit, and verifiable reasoning steps. For pose estimation, we leverage quantum-dot-grounded behavioral data and propose a multi-stage pipeline that integrates temporal, spatial, and cross-view reasoning. This design greatly reduces human annotation effort, exposes low-confidence labels through geometric checks such as reprojection error, and produces labels that can later be filtered, corrected, or used to fine-tune downstream pose models. For behavioral understanding, we propose a pipeline that integrates deep embedded clustering for over-segmented behavior discovery, VLM-based per-clip video captioning, and LLM-based reasoning to merge and semantically label behavioral segments. The behavioral pipeline can operate directly from visual information and does not require keypoints to segment behavior. Together, these components enable scalable, interpretable, and label-light analysis of multi-animal behavior.
A Hitchhiker's Guide to Poisson Gradient Estimation
Feb 03, 2026Poisson-distributed latent variable models are widely used in computational neuroscience, but differentiating through discrete stochastic samples remains challenging. Two approaches address this: Exponential Arrival Time (EAT) simulation and Gumbel-SoftMax (GSM) relaxation. We provide the first systematic comparison of these methods, along with practical guidance for practitioners. Our main technical contribution is a modification to the EAT method that theoretically guarantees an unbiased first moment (exactly matching the firing rate), and reduces second-moment bias. We evaluate these methods on their distributional fidelity, gradient quality, and performance on two tasks: (1) variational autoencoders with Poisson latents, and (2) partially observable generalized linear models, where latent neural connectivity must be inferred from observed spike trains. Across all metrics, our modified EAT method exhibits better overall performance (often comparable to exact gradients), and substantially higher robustness to hyperparameter choices. Together, our results clarify the trade-offs between these methods and offer concrete recommendations for practitioners working with Poisson latent variable models.
A Disentangled Low-Rank RNN Framework for Uncovering Neural Connectivity and Dynamics
Nov 17, 2025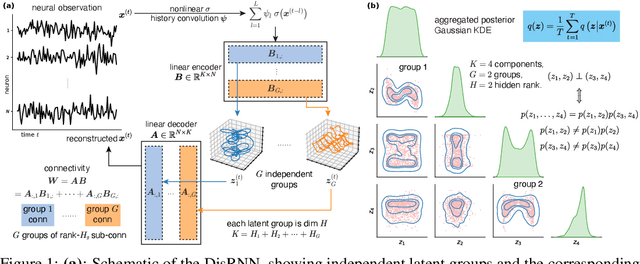
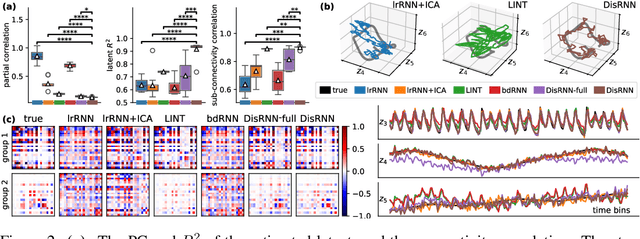
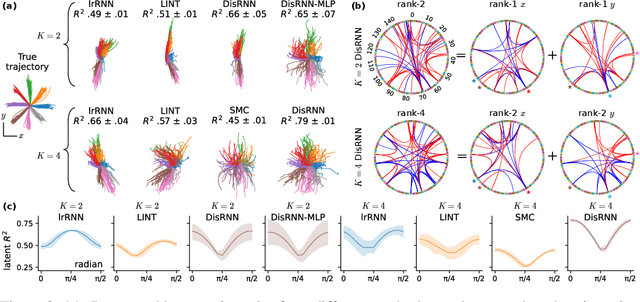
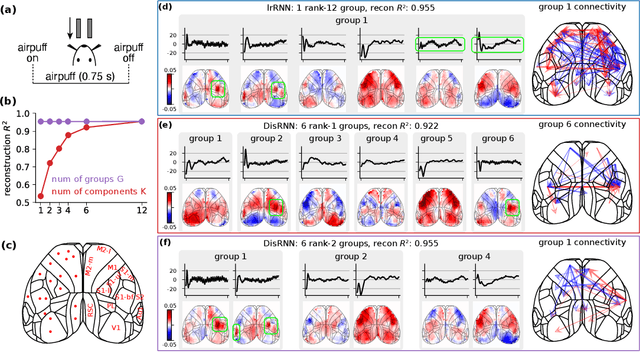
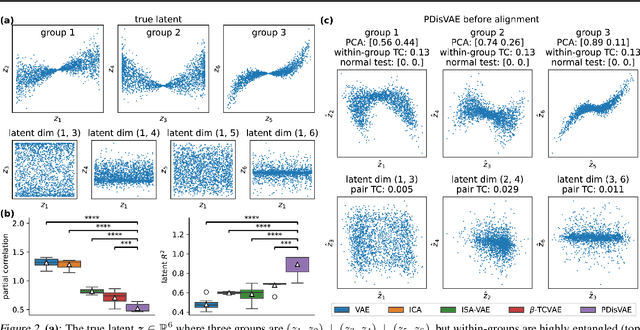
Low-rank recurrent neural networks (lrRNNs) are a class of models that uncover low-dimensional latent dynamics underlying neural population activity. Although their functional connectivity is low-rank, it lacks disentanglement interpretations, making it difficult to assign distinct computational roles to different latent dimensions. To address this, we propose the Disentangled Recurrent Neural Network (DisRNN), a generative lrRNN framework that assumes group-wise independence among latent dynamics while allowing flexible within-group entanglement. These independent latent groups allow latent dynamics to evolve separately, but are internally rich for complex computation. We reformulate the lrRNN under a variational autoencoder (VAE) framework, enabling us to introduce a partial correlation penalty that encourages disentanglement between groups of latent dimensions. Experiments on synthetic, monkey M1, and mouse voltage imaging data show that DisRNN consistently improves the disentanglement and interpretability of learned neural latent trajectories in low-dimensional space and low-rank connectivity over baseline lrRNNs that do not encourage partial disentanglement.
Uncovering Semantic Selectivity of Latent Groups in Higher Visual Cortex with Mutual Information-Guided Diffusion
Oct 02, 2025Understanding how neural populations in higher visual areas encode object-centered visual information remains a central challenge in computational neuroscience. Prior works have investigated representational alignment between artificial neural networks and the visual cortex. Nevertheless, these findings are indirect and offer limited insights to the structure of neural populations themselves. Similarly, decoding-based methods have quantified semantic features from neural populations but have not uncovered their underlying organizations. This leaves open a scientific question: "how feature-specific visual information is distributed across neural populations in higher visual areas, and whether it is organized into structured, semantically meaningful subspaces." To tackle this problem, we present MIG-Vis, a method that leverages the generative power of diffusion models to visualize and validate the visual-semantic attributes encoded in neural latent subspaces. Our method first uses a variational autoencoder to infer a group-wise disentangled neural latent subspace from neural populations. Subsequently, we propose a mutual information (MI)-guided diffusion synthesis procedure to visualize the specific visual-semantic features encoded by each latent group. We validate MIG-Vis on multi-session neural spiking datasets from the inferior temporal (IT) cortex of two macaques. The synthesized results demonstrate that our method identifies neural latent groups with clear semantic selectivity to diverse visual features, including object pose, inter-category transformations, and intra-class content. These findings provide direct, interpretable evidence of structured semantic representation in the higher visual cortex and advance our understanding of its encoding principles.
Learning Task-Agnostic Skill Bases to Uncover Motor Primitives in Animal Behaviors
Jun 18, 2025Animals flexibly recombine a finite set of core motor primitives to meet diverse task demands, but existing behavior-segmentation methods oversimplify this process by imposing discrete syllables under restrictive generative assumptions. To reflect the animal behavior generation procedure, we introduce skill-based imitation learning (SKIL) for behavior understanding, a reinforcement learning-based imitation framework that (1) infers interpretable skill sets, i.e., latent basis functions of behavior, by leveraging representation learning on transition probabilities, and (2) parameterizes policies as dynamic mixtures of these skills. We validate our approach on a simple grid world, a discrete labyrinth, and unconstrained videos of freely moving animals. Across tasks, it identifies reusable skill components, learns continuously evolving compositional policies, and generates realistic trajectories beyond the capabilities of traditional discrete models. By exploiting generative behavior modeling with compositional representations, our method offers a concise, principled account of how complex animal behaviors emerge from dynamic combinations of fundamental motor primitives.
EmoBipedNav: Emotion-aware Social Navigation for Bipedal Robots with Deep Reinforcement Learning
Mar 16, 2025This study presents an emotion-aware navigation framework -- EmoBipedNav -- using deep reinforcement learning (DRL) for bipedal robots walking in socially interactive environments. The inherent locomotion constraints of bipedal robots challenge their safe maneuvering capabilities in dynamic environments. When combined with the intricacies of social environments, including pedestrian interactions and social cues, such as emotions, these challenges become even more pronounced. To address these coupled problems, we propose a two-stage pipeline that considers both bipedal locomotion constraints and complex social environments. Specifically, social navigation scenarios are represented using sequential LiDAR grid maps (LGMs), from which we extract latent features, including collision regions, emotion-related discomfort zones, social interactions, and the spatio-temporal dynamics of evolving environments. The extracted features are directly mapped to the actions of reduced-order models (ROMs) through a DRL architecture. Furthermore, the proposed framework incorporates full-order dynamics and locomotion constraints during training, effectively accounting for tracking errors and restrictions of the locomotion controller while planning the trajectory with ROMs. Comprehensive experiments demonstrate that our approach exceeds both model-based planners and DRL-based baselines. The hardware videos and open-source code are available at https://gatech-lidar.github.io/emobipednav.github.io/.
A Revisit of Total Correlation in Disentangled Variational Auto-Encoder with Partial Disentanglement
Feb 04, 2025
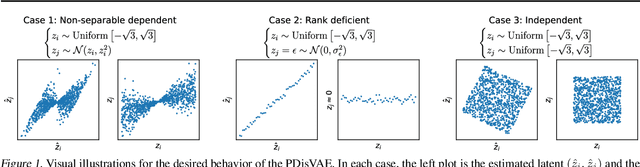

A fully disentangled variational auto-encoder (VAE) aims to identify disentangled latent components from observations. However, enforcing full independence between all latent components may be too strict for certain datasets. In some cases, multiple factors may be entangled together in a non-separable manner, or a single independent semantic meaning could be represented by multiple latent components within a higher-dimensional manifold. To address such scenarios with greater flexibility, we develop the Partially Disentangled VAE (PDisVAE), which generalizes the total correlation (TC) term in fully disentangled VAEs to a partial correlation (PC) term. This framework can handle group-wise independence and can naturally reduce to either the standard VAE or the fully disentangled VAE. Validation through three synthetic experiments demonstrates the correctness and practicality of PDisVAE. When applied to real-world datasets, PDisVAE discovers valuable information that is difficult to find using fully disentangled VAEs, implying its versatility and effectiveness.
Exploring Behavior-Relevant and Disentangled Neural Dynamics with Generative Diffusion Models
Oct 12, 2024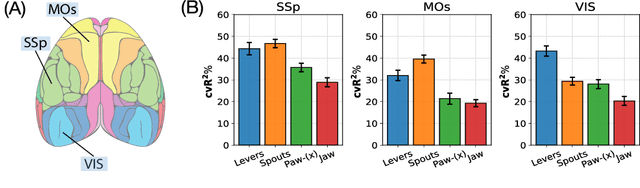

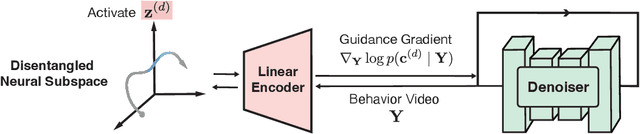
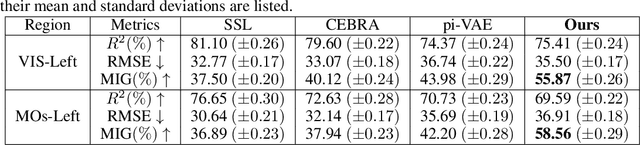
Understanding the neural basis of behavior is a fundamental goal in neuroscience. Current research in large-scale neuro-behavioral data analysis often relies on decoding models, which quantify behavioral information in neural data but lack details on behavior encoding. This raises an intriguing scientific question: ``how can we enable in-depth exploration of neural representations in behavioral tasks, revealing interpretable neural dynamics associated with behaviors''. However, addressing this issue is challenging due to the varied behavioral encoding across different brain regions and mixed selectivity at the population level. To tackle this limitation, our approach, named ``BeNeDiff'', first identifies a fine-grained and disentangled neural subspace using a behavior-informed latent variable model. It then employs state-of-the-art generative diffusion models to synthesize behavior videos that interpret the neural dynamics of each latent factor. We validate the method on multi-session datasets containing widefield calcium imaging recordings across the dorsal cortex. Through guiding the diffusion model to activate individual latent factors, we verify that the neural dynamics of latent factors in the disentangled neural subspace provide interpretable quantifications of the behaviors of interest. At the same time, the neural subspace in BeNeDiff demonstrates high disentanglement and neural reconstruction quality.
Markovian Gaussian Process: A Universal State-Space Representation for Stationary Temporal Gaussian Process
Jun 29, 2024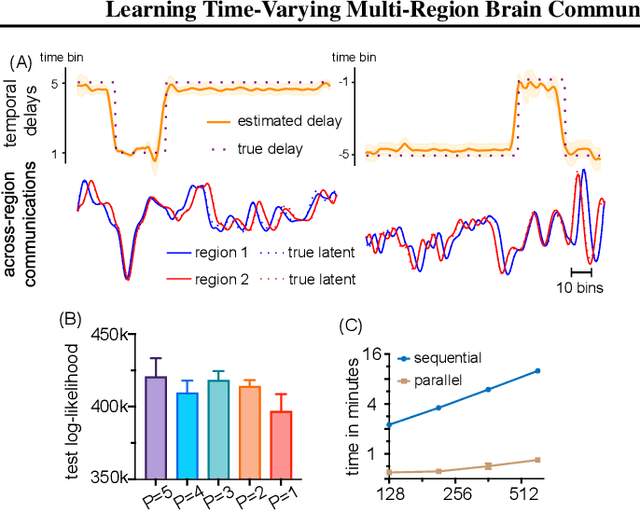

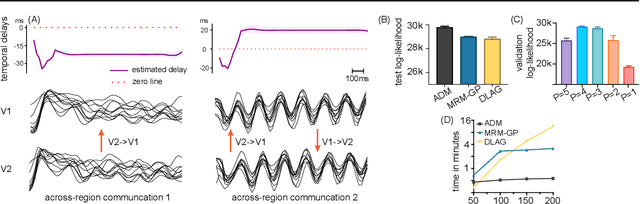
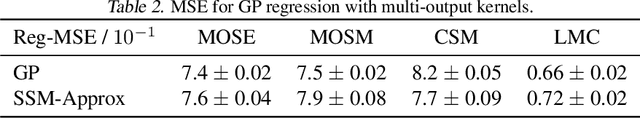
Gaussian Processes (GPs) and Linear Dynamical Systems (LDSs) are essential time series and dynamic system modeling tools. GPs can handle complex, nonlinear dynamics but are computationally demanding, while LDSs offer efficient computation but lack the expressive power of GPs. To combine their benefits, we introduce a universal method that allows an LDS to mirror stationary temporal GPs. This state-space representation, known as the Markovian Gaussian Process (Markovian GP), leverages the flexibility of kernel functions while maintaining efficient linear computation. Unlike existing GP-LDS conversion methods, which require separability for most multi-output kernels, our approach works universally for single- and multi-output stationary temporal kernels. We evaluate our method by computing covariance, performing regression tasks, and applying it to a neuroscience application, demonstrating that our method provides an accurate state-space representation for stationary temporal GPs.
NAP^2: A Benchmark for Naturalness and Privacy-Preserving Text Rewriting by Learning from Human
Jun 06, 2024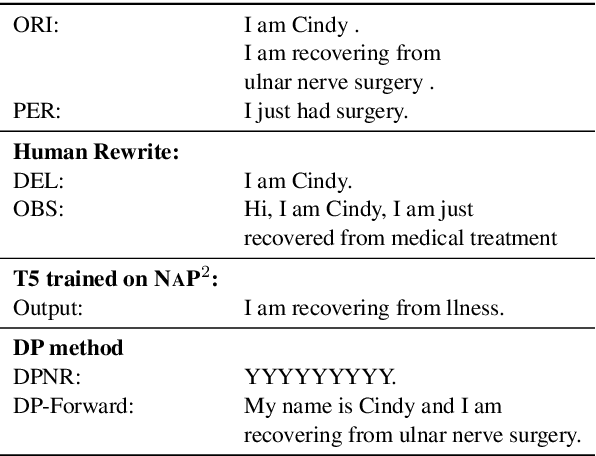
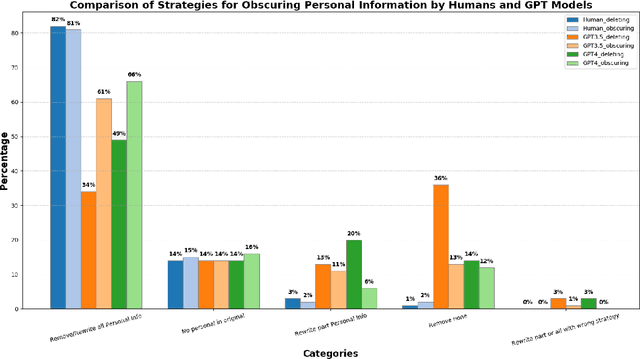
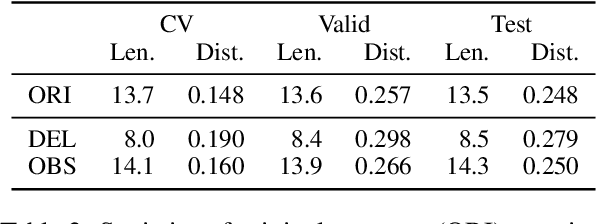
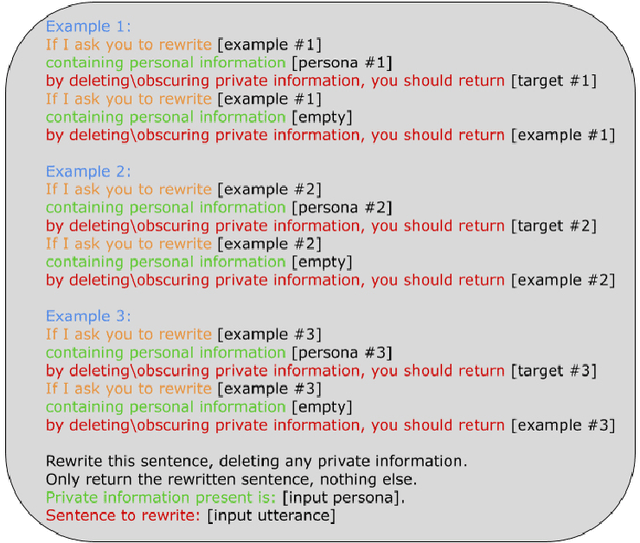
Increasing concerns about privacy leakage issues in academia and industry arise when employing NLP models from third-party providers to process sensitive texts. To protect privacy before sending sensitive data to those models, we suggest sanitizing sensitive text using two common strategies used by humans: i) deleting sensitive expressions, and ii) obscuring sensitive details by abstracting them. To explore the issues and develop a tool for text rewriting, we curate the first corpus, coined NAP^2, through both crowdsourcing and the use of large language models (LLMs). Compared to the prior works based on differential privacy, which lead to a sharp drop in information utility and unnatural texts, the human-inspired approaches result in more natural rewrites and offer an improved balance between privacy protection and data utility, as demonstrated by our extensive experiments.