 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Risk Classification to Action Plan Remediation: A Guardrail Feedback Driven Framework for LLM Agents
Jun 04, 2026LLM-based guardrails typically safeguard agents by evaluating proposed actions or inputs before execution, producing safety signals such as binary allow/deny decisions, risk categories, and/or explanatory rationales about potential policy violations. However, agent risks often arise when otherwise benign tasks are contaminated by untrusted external content, unsafe instructions, or risky tool use. Existing guardrails often flag the entire task uniformly as unsafe, thereby blocking the threat but sacrificing the benign part. Moreover, existing work largely evaluates guardrails in isolation, leaving unclear whether their interventions lead to safer downstream agent behavior. To address this, we introduce TRIAD (Tripartite Response for Iterative Agent Guardrailing), a guardrail-integrated agent framework that leverages guardrail-generated verbal feedback as a guiding signal to keep the agent aligned with benign objectives at each planning step. We finetune a language model on a self-curated training dataset to output one of three decisions: proceed, refuse, or update, together with structured natural-language feedback. Rather than merely allowing or blocking execution, update guides the agent to revise its plan, avoid harmful components, and preserve the benign task where possible. TRIAD injects this feedback into the agent's context, enabling subsequent plan revision and forming a closed loop between guardrail feedback and agent planning. Extensive experiments on ASB and AgentHarm show that TRIAD reduces the average attack success rate to 10.42%, while achieving the best safety-utility trade-off among guardrail-integrated baselines. Our code is available at: https://github.com/YUHAOSUNABC/TRIAD.
Let's Roll a BiFTA: Bi-refinement for Fine-grained Text-visual Alignment in Vision-Language Models
Jan 28, 2026Recent research has shown that aligning fine-grained text descriptions with localized image patches can significantly improve the zero-shot performance of pre-trained vision-language models (e.g., CLIP). However, we find that both fine-grained text descriptions and localized image patches often contain redundant information, making text-visual alignment less effective. In this paper, we tackle this issue from two perspectives: \emph{View Refinement} and \emph{Description refinement}, termed as \textit{\textbf{Bi}-refinement for \textbf{F}ine-grained \textbf{T}ext-visual \textbf{A}lignment} (BiFTA). \emph{View refinement} removes redundant image patches with high \emph{Intersection over Union} (IoU) ratios, resulting in more distinctive visual samples. \emph{Description refinement} removes redundant text descriptions with high pairwise cosine similarity, ensuring greater diversity in the remaining descriptions. BiFTA achieves superior zero-shot performance on 6 benchmark datasets for both ViT-based and ResNet-based CLIP, justifying the necessity to remove redundant information in visual-text alignment.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
PrivTune: Efficient and Privacy-Preserving Fine-Tuning of Large Language Models via Device-Cloud Collaboration
Dec 09, 2025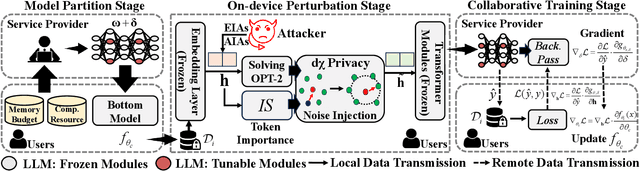
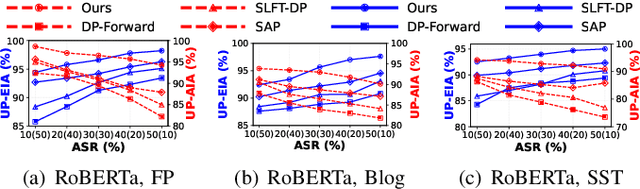


With the rise of large language models, service providers offer language models as a service, enabling users to fine-tune customized models via uploaded private datasets. However, this raises concerns about sensitive data leakage. Prior methods, relying on differential privacy within device-cloud collaboration frameworks, struggle to balance privacy and utility, exposing users to inference attacks or degrading fine-tuning performance. To address this, we propose PrivTune, an efficient and privacy-preserving fine-tuning framework via Split Learning (SL). The key idea of PrivTune is to inject crafted noise into token representations from the SL bottom model, making each token resemble the $n$-hop indirect neighbors. PrivTune formulates this as an optimization problem to compute the optimal noise vector, aligning with defense-utility goals. On this basis, it then adjusts the parameters (i.e., mean) of the $d_χ$-Privacy noise distribution to align with the optimization direction and scales the noise according to token importance to minimize distortion. Experiments on five datasets (covering both classification and generation tasks) against three embedding inversion and three attribute inference attacks show that, using RoBERTa on the Stanford Sentiment Treebank dataset, PrivTune reduces the attack success rate to 10% with only a 3.33% drop in utility performance, outperforming state-of-the-art baselines.
MulVuln: Enhancing Pre-trained LMs with Shared and Language-Specific Knowledge for Multilingual Vulnerability Detection
Oct 05, 2025Software vulnerabilities (SVs) pose a critical threat to safety-critical systems, driving the adoption of AI-based approaches such as machine learning and deep learning for software vulnerability detection. Despite promising results, most existing methods are limited to a single programming language. This is problematic given the multilingual nature of modern software, which is often complex and written in multiple languages. Current approaches often face challenges in capturing both shared and language-specific knowledge of source code, which can limit their performance on diverse programming languages and real-world codebases. To address this gap, we propose MULVULN, a novel multilingual vulnerability detection approach that learns from source code across multiple languages. MULVULN captures both the shared knowledge that generalizes across languages and the language-specific knowledge that reflects unique coding conventions. By integrating these aspects, it achieves more robust and effective detection of vulnerabilities in real-world multilingual software systems. The rigorous and extensive experiments on the real-world and diverse REEF dataset, consisting of 4,466 CVEs with 30,987 patches across seven programming languages, demonstrate the superiority of MULVULN over thirteen effective and state-of-the-art baselines. Notably, MULVULN achieves substantially higher F1-score, with improvements ranging from 1.45% to 23.59% compared to the baseline methods.
Robust Anomaly Detection in O-RAN: Leveraging LLMs against Data Manipulation Attacks
Aug 11, 2025The introduction of 5G and the Open Radio Access Network (O-RAN) architecture has enabled more flexible and intelligent network deployments. However, the increased complexity and openness of these architectures also introduce novel security challenges, such as data manipulation attacks on the semi-standardised Shared Data Layer (SDL) within the O-RAN platform through malicious xApps. In particular, malicious xApps can exploit this vulnerability by introducing subtle Unicode-wise alterations (hypoglyphs) into the data that are being used by traditional machine learning (ML)-based anomaly detection methods. These Unicode-wise manipulations can potentially bypass detection and cause failures in anomaly detection systems based on traditional ML, such as AutoEncoders, which are unable to process hypoglyphed data without crashing. We investigate the use of Large Language Models (LLMs) for anomaly detection within the O-RAN architecture to address this challenge. We demonstrate that LLM-based xApps maintain robust operational performance and are capable of processing manipulated messages without crashing. While initial detection accuracy requires further improvements, our results highlight the robustness of LLMs to adversarial attacks such as hypoglyphs in input data. There is potential to use their adaptability through prompt engineering to further improve the accuracy, although this requires further research. Additionally, we show that LLMs achieve low detection latency (under 0.07 seconds), making them suitable for Near-Real-Time (Near-RT) RIC deployments.
Self-Adaptive and Robust Federated Spectrum Sensing without Benign Majority for Cellular Networks
Jul 16, 2025Advancements in wireless and mobile technologies, including 5G advanced and the envisioned 6G, are driving exponential growth in wireless devices. However, this rapid expansion exacerbates spectrum scarcity, posing a critical challenge. Dynamic spectrum allocation (DSA)--which relies on sensing and dynamically sharing spectrum--has emerged as an essential solution to address this issue. While machine learning (ML) models hold significant potential for improving spectrum sensing, their adoption in centralized ML-based DSA systems is limited by privacy concerns, bandwidth constraints, and regulatory challenges. To overcome these limitations, distributed ML-based approaches such as Federated Learning (FL) offer promising alternatives. This work addresses two key challenges in FL-based spectrum sensing (FLSS). First, the scarcity of labeled data for training FL models in practical spectrum sensing scenarios is tackled with a semi-supervised FL approach, combined with energy detection, enabling model training on unlabeled datasets. Second, we examine the security vulnerabilities of FLSS, focusing on the impact of data poisoning attacks. Our analysis highlights the shortcomings of existing majority-based defenses in countering such attacks. To address these vulnerabilities, we propose a novel defense mechanism inspired by vaccination, which effectively mitigates data poisoning attacks without relying on majority-based assumptions. Extensive experiments on both synthetic and real-world datasets validate our solutions, demonstrating that FLSS can achieve near-perfect accuracy on unlabeled datasets and maintain Byzantine robustness against both targeted and untargeted data poisoning attacks, even when a significant proportion of participants are malicious.
THEMIS: Towards Practical Intellectual Property Protection for Post-Deployment On-Device Deep Learning Models
Mar 31, 2025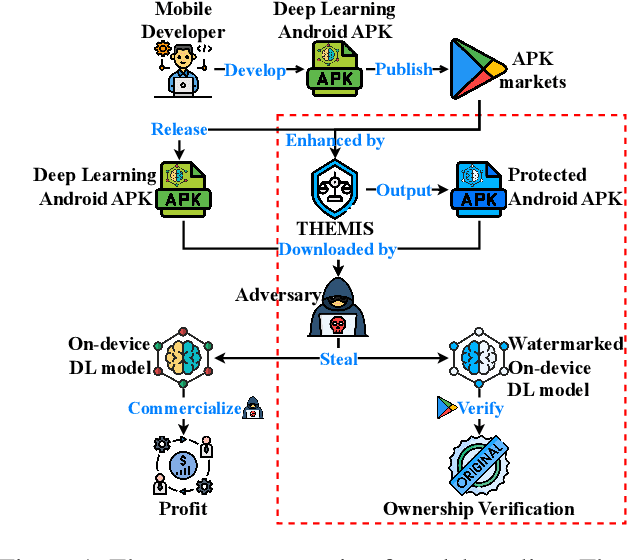

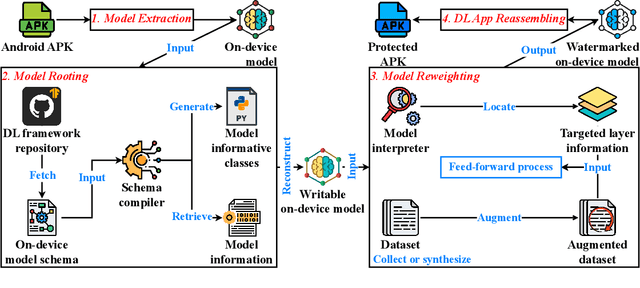
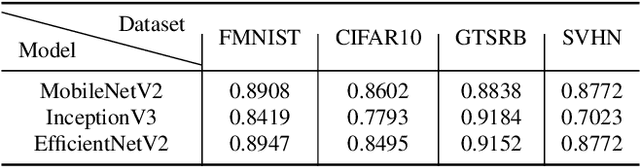
On-device deep learning (DL) has rapidly gained adoption in mobile apps, offering the benefits of offline model inference and user privacy preservation over cloud-based approaches. However, it inevitably stores models on user devices, introducing new vulnerabilities, particularly model-stealing attacks and intellectual property infringement. While system-level protections like Trusted Execution Environments (TEEs) provide a robust solution, practical challenges remain in achieving scalable on-device DL model protection, including complexities in supporting third-party models and limited adoption in current mobile solutions. Advancements in TEE-enabled hardware, such as NVIDIA's GPU-based TEEs, may address these obstacles in the future. Currently, watermarking serves as a common defense against model theft but also faces challenges here as many mobile app developers lack corresponding machine learning expertise and the inherent read-only and inference-only nature of on-device DL models prevents third parties like app stores from implementing existing watermarking techniques in post-deployment models. To protect the intellectual property of on-device DL models, in this paper, we propose THEMIS, an automatic tool that lifts the read-only restriction of on-device DL models by reconstructing their writable counterparts and leverages the untrainable nature of on-device DL models to solve watermark parameters and protect the model owner's intellectual property. Extensive experimental results across various datasets and model structures show the superiority of THEMIS in terms of different metrics. Further, an empirical investigation of 403 real-world DL mobile apps from Google Play is performed with a success rate of 81.14%, showing the practicality of THEMIS.
FedMobile: Enabling Knowledge Contribution-aware Multi-modal Federated Learning with Incomplete Modalities
Feb 20, 2025The Web of Things (WoT) enhances interoperability across web-based and ubiquitous computing platforms while complementing existing IoT standards. The multimodal Federated Learning (FL) paradigm has been introduced to enhance WoT by enabling the fusion of multi-source mobile sensing data while preserving privacy. However, a key challenge in mobile sensing systems using multimodal FL is modality incompleteness, where some modalities may be unavailable or only partially captured, potentially degrading the system's performance and reliability. Current multimodal FL frameworks typically train multiple unimodal FL subsystems or apply interpolation techniques on the node side to approximate missing modalities. However, these approaches overlook the shared latent feature space among incomplete modalities across different nodes and fail to discriminate against low-quality nodes. To address this gap, we present FedMobile, a new knowledge contribution-aware multimodal FL framework designed for robust learning despite missing modalities. FedMobile prioritizes local-to-global knowledge transfer, leveraging cross-node multimodal feature information to reconstruct missing features. It also enhances system performance and resilience to modality heterogeneity through rigorous node contribution assessments and knowledge contribution-aware aggregation rules. Empirical evaluations on five widely recognized multimodal benchmark datasets demonstrate that FedMobile maintains robust learning even when up to 90% of modality information is missing or when data from two modalities are randomly missing, outperforming state-of-the-art baselines.
GRID: Protecting Training Graph from Link Stealing Attacks on GNN Models
Jan 19, 2025



Graph neural networks (GNNs) have exhibited superior performance in various classification tasks on graph-structured data. However, they encounter the potential vulnerability from the link stealing attacks, which can infer the presence of a link between two nodes via measuring the similarity of its incident nodes' prediction vectors produced by a GNN model. Such attacks pose severe security and privacy threats to the training graph used in GNN models. In this work, we propose a novel solution, called Graph Link Disguise (GRID), to defend against link stealing attacks with the formal guarantee of GNN model utility for retaining prediction accuracy. The key idea of GRID is to add carefully crafted noises to the nodes' prediction vectors for disguising adjacent nodes as n-hop indirect neighboring nodes. We take into account the graph topology and select only a subset of nodes (called core nodes) covering all links for adding noises, which can avert the noises offset and have the further advantages of reducing both the distortion loss and the computation cost. Our crafted noises can ensure 1) the noisy prediction vectors of any two adjacent nodes have their similarity level like that of two non-adjacent nodes and 2) the model prediction is unchanged to ensure zero utility loss. Extensive experiments on five datasets are conducted to show the effectiveness of our proposed GRID solution against different representative link-stealing attacks under transductive settings and inductive settings respectively, as well as two influence-based attacks. Meanwhile, it achieves a much better privacy-utility trade-off than existing methods when extended to GNNs.