 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRel-MOSS: Towards Imbalanced Relational Deep Learning on Relational Databases
Mar 09, 2026In recent advances, to enable a fully data-driven learning paradigm on relational databases (RDB), relational deep learning (RDL) is proposed to structure the RDB as a heterogeneous entity graph and adopt the graph neural network (GNN) as the predictive model. However, existing RDL methods neglect the imbalance problem of relational data in RDBs and risk under-representing the minority entities, leading to an unusable model in practice. In this work, we investigate, for the first time, class imbalance problem in RDB entity classification and design the relation-centric minority synthetic over-sampling GNN (Rel-MOSS), in order to fill a critical void in the current literature. Specifically, to mitigate the issue of minority-related information being submerged by majority counterparts, we design the relation-wise gating controller to modulate neighborhood messages from each individual relation type. Based on the relational-gated representations, we further propose the relation-guided minority synthesizer for over-sampling, which integrates the entity relational signatures to maintain relational consistency. Extensive experiments on 12 entity classification datasets provide compelling evidence for the superiority of Rel-MOSS, yielding an average improvement of up to 2.46% and 4.00% in terms of Balanced Accuracy and G-Mean, compared with SOTA RDL methods and classic methods for handling class imbalance.
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Mar 02, 2026Automated paper reproduction -- generating executable code from academic papers -- is bottlenecked not by information retrieval but by the tacit knowledge that papers inevitably leave implicit. We formalize this challenge as the progressive recovery of three types of tacit knowledge -- relational, somatic, and collective -- and propose \method, a graph-based agent framework with a dedicated mechanism for each: node-level relation-aware aggregation recovers relational knowledge by analyzing implementation-unit-level reuse and adaptation relationships between the target paper and its citation neighbors; execution-feedback refinement recovers somatic knowledge through iterative debugging driven by runtime signals; and graph-level knowledge induction distills collective knowledge from clusters of papers sharing similar implementations. On an extended ReproduceBench spanning 3 domains, 10 tasks, and 40 recent papers, \method{} achieves an average performance gap of 10.04\% against official implementations, improving over the strongest baseline by 24.68\%. The code will be publicly released upon acceptance; the repository link will be provided in the final version.
SimGR: Escaping the Pitfalls of Generative Decoding in LLM-based Recommendation
Feb 08, 2026A core objective in recommender systems is to accurately model the distribution of user preferences over items to enable personalized recommendations. Recently, driven by the strong generative capabilities of large language models (LLMs), LLM-based generative recommendation has become increasingly popular. However, we observe that existing methods inevitably introduce systematic bias when estimating item-level preference distributions. Specifically, autoregressive generation suffers from incomplete coverage due to beam search pruning, while parallel generation distorts probabilities by assuming token independence. We attribute this issue to a fundamental modeling mismatch: these methods approximate item-level distributions via token-level generation, which inherently induces approximation errors. Through both theoretical analysis and empirical validation, we demonstrate that token-level generation cannot faithfully substitute item-level generation, leading to biased item distributions. To address this, we propose \textbf{Sim}ply \textbf{G}enerative \textbf{R}ecommendation (\textbf{SimGR}), a framework that directly models item-level preference distributions in a shared latent space and ranks items by similarity, thereby aligning the modeling objective with recommendation and mitigating distributional distortion. Extensive experiments across multiple datasets and LLM backbones show that SimGR consistently outperforms existing generative recommenders. Our code is available at https://anonymous.4open.science/r/SimGR-C408/
Learn to Preserve Personality: Federated Foundation Models in Recommendations
Jun 13, 2025A core learning challenge for existed Foundation Models (FM) is striking the tradeoff between generalization with personalization, which is a dilemma that has been highlighted by various parameter-efficient adaptation techniques. Federated foundation models (FFM) provide a structural means to decouple shared knowledge from individual specific adaptations via decentralized processes. Recommendation systems offer a perfect testbed for FFMs, given their reliance on rich implicit feedback reflecting unique user characteristics. This position paper discusses a novel learning paradigm where FFMs not only harness their generalization capabilities but are specifically designed to preserve the integrity of user personality, illustrated thoroughly within the recommendation contexts. We envision future personal agents, powered by personalized adaptive FMs, guiding user decisions on content. Such an architecture promises a user centric, decentralized system where individuals maintain control over their personalized agents.
Exploring Criteria of Loss Reweighting to Enhance LLM Unlearning
May 17, 2025Loss reweighting has shown significant benefits for machine unlearning with large language models (LLMs). However, their exact functionalities are left unclear and the optimal strategy remains an open question, thus impeding the understanding and improvement of existing methodologies. In this paper, we identify two distinct goals of loss reweighting, namely, Saturation and Importance -- the former indicates that those insufficiently optimized data should be emphasized, while the latter stresses some critical data that are most influential for loss minimization. To study their usefulness, we design specific reweighting strategies for each goal and evaluate their respective effects on unlearning. We conduct extensive empirical analyses on well-established benchmarks, and summarize some important observations as follows: (i) Saturation enhances efficacy more than importance-based reweighting, and their combination can yield additional improvements. (ii) Saturation typically allocates lower weights to data with lower likelihoods, whereas importance-based reweighting does the opposite. (iii) The efficacy of unlearning is also largely influenced by the smoothness and granularity of the weight distributions. Based on these findings, we propose SatImp, a simple reweighting method that combines the advantages of both saturation and importance. Empirical results on extensive datasets validate the efficacy of our method, potentially bridging existing research gaps and indicating directions for future research. Our code is available at https://github.com/Puning97/SatImp-for-LLM-Unlearning.
WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents
Apr 22, 2025Can we build accurate world models out of large language models (LLMs)? How can world models benefit LLM agents? The gap between the prior knowledge of LLMs and the specified environment's dynamics usually bottlenecks LLMs' performance as world models. To bridge the gap, we propose a training-free "world alignment" that learns an environment's symbolic knowledge complementary to LLMs. The symbolic knowledge covers action rules, knowledge graphs, and scene graphs, which are extracted by LLMs from exploration trajectories and encoded into executable codes to regulate LLM agents' policies. We further propose an RL-free, model-based agent "WALL-E 2.0" through the model-predictive control (MPC) framework. Unlike classical MPC requiring costly optimization on the fly, we adopt an LLM agent as an efficient look-ahead optimizer of future steps' actions by interacting with the neurosymbolic world model. While the LLM agent's strong heuristics make it an efficient planner in MPC, the quality of its planned actions is also secured by the accurate predictions of the aligned world model. They together considerably improve learning efficiency in a new environment. On open-world challenges in Mars (Minecraft like) and ALFWorld (embodied indoor environments), WALL-E 2.0 significantly outperforms existing methods, e.g., surpassing baselines in Mars by 16.1%-51.6% of success rate and by at least 61.7% in score. In ALFWorld, it achieves a new record 98% success rate after only 4 iterations.
FedMerge: Federated Personalization via Model Merging
Apr 09, 2025One global model in federated learning (FL) might not be sufficient to serve many clients with non-IID tasks and distributions. While there has been advances in FL to train multiple global models for better personalization, they only provide limited choices to clients so local finetuning is still indispensable. In this paper, we propose a novel ``FedMerge'' approach that can create a personalized model per client by simply merging multiple global models with automatically optimized and customized weights. In FedMerge, a few global models can serve many non-IID clients, even without further local finetuning. We formulate this problem as a joint optimization of global models and the merging weights for each client. Unlike existing FL approaches where the server broadcasts one or multiple global models to all clients, the server only needs to send a customized, merged model to each client. Moreover, instead of periodically interrupting the local training and re-initializing it to a global model, the merged model aligns better with each client's task and data distribution, smoothening the local-global gap between consecutive rounds caused by client drift. We evaluate FedMerge on three different non-IID settings applied to different domains with diverse tasks and data types, in which FedMerge consistently outperforms existing FL approaches, including clustering-based and mixture-of-experts (MoE) based methods.
Biologically Plausible Brain Graph Transformer
Feb 13, 2025State-of-the-art brain graph analysis methods fail to fully encode the small-world architecture of brain graphs (accompanied by the presence of hubs and functional modules), and therefore lack biological plausibility to some extent. This limitation hinders their ability to accurately represent the brain's structural and functional properties, thereby restricting the effectiveness of machine learning models in tasks such as brain disorder detection. In this work, we propose a novel Biologically Plausible Brain Graph Transformer (BioBGT) that encodes the small-world architecture inherent in brain graphs. Specifically, we present a network entanglement-based node importance encoding technique that captures the structural importance of nodes in global information propagation during brain graph communication, highlighting the biological properties of the brain structure. Furthermore, we introduce a functional module-aware self-attention to preserve the functional segregation and integration characteristics of brain graphs in the learned representations. Experimental results on three benchmark datasets demonstrate that BioBGT outperforms state-of-the-art models, enhancing biologically plausible brain graph representations for various brain graph analytical tasks
Federated Foundation Models on Heterogeneous Time Series
Dec 12, 2024Training a general-purpose time series foundation models with robust generalization capabilities across diverse applications from scratch is still an open challenge. Efforts are primarily focused on fusing cross-domain time series datasets to extract shared subsequences as tokens for training models on Transformer architecture. However, due to significant statistical heterogeneity across domains, this cross-domain fusing approach doesn't work effectively as the same as fusing texts and images. To tackle this challenge, this paper proposes a novel federated learning approach to address the heterogeneity in time series foundation models training, namely FFTS. Specifically, each data-holding organization is treated as an independent client in a collaborative learning framework with federated settings, and then many client-specific local models will be trained to preserve the unique characteristics per dataset. Moreover, a new regularization mechanism will be applied to both client-side and server-side, thus to align the shared knowledge across heterogeneous datasets from different domains. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed federated learning approach. The newly learned time series foundation models achieve superior generalization capabilities on cross-domain time series analysis tasks, including forecasting, imputation, and anomaly detection.
Mind the Gap Between Prototypes and Images in Cross-domain Finetuning
Oct 16, 2024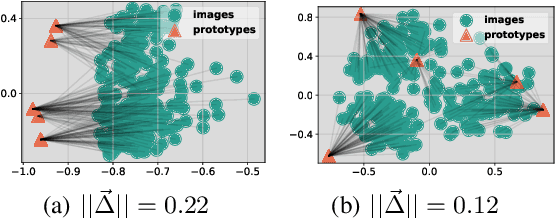
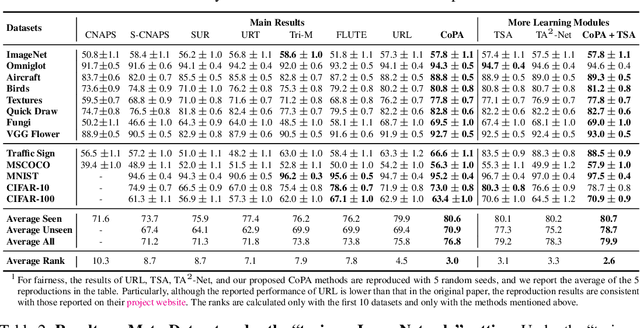
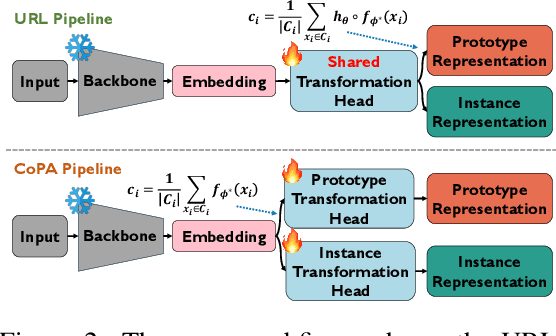
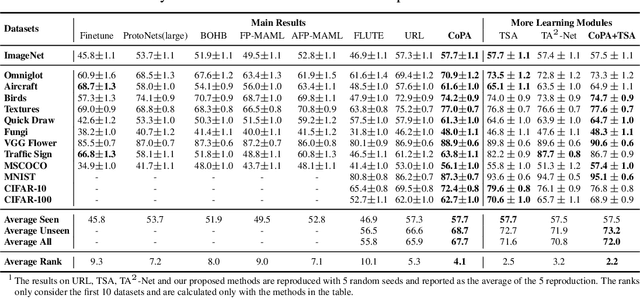
In cross-domain few-shot classification (CFC), recent works mainly focus on adapting a simple transformation head on top of a frozen pre-trained backbone with few labeled data to project embeddings into a task-specific metric space where classification can be performed by measuring similarities between image instance and prototype representations. Technically, an assumption implicitly adopted in such a framework is that the prototype and image instance embeddings share the same representation transformation. However, in this paper, we find that there naturally exists a gap, which resembles the modality gap, between the prototype and image instance embeddings extracted from the frozen pre-trained backbone, and simply applying the same transformation during the adaptation phase constrains exploring the optimal representations and shrinks the gap between prototype and image representations. To solve this problem, we propose a simple yet effective method, contrastive prototype-image adaptation (CoPA), to adapt different transformations respectively for prototypes and images similarly to CLIP by treating prototypes as text prompts. Extensive experiments on Meta-Dataset demonstrate that CoPA achieves the state-of-the-art performance more efficiently. Meanwhile, further analyses also indicate that CoPA can learn better representation clusters, enlarge the gap, and achieve minimal validation loss at the enlarged gap.