 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrameTwin: Curve-Anchored Gaussian Alignment from Sparse Views for Adaptive Wireframe 3D Printing
May 10, 2026We present FrameTwin, a curve-anchored Gaussian alignment framework that uses sparse-view images to close the control loop for adaptive wireframe 3D printing. Our key idea is to capture the deformation of thin wireframe structures from sparse-view images using Gaussian kernels anchored to parametric curves, yielding a compact and geometry-aware encoding that explicitly captures strut topology. Driven by a differentiable rendering pipeline, FrameTwin estimates a neural deformation field that aligns the partially printed target model with the deformed structure observed during fabrication, where the optimized curve-Gaussian representation serves as a digital twin of the evolving wireframe. Unlike general Gaussian-splatting approaches, our formulation constrains kernel placement along parametric curves, substantially reducing the ambiguity inherent in sparse-view observations of thin structures. The resultant deformation-field alignment enforces global consistency across all struts. By using the estimated deformation field to blend the distorted printed geometry with the remaining unprinted geometry, FrameTwin enables adaptive updates to future printing trajectories. We demonstrate that FrameTwin can robustly capture and compensate for deformation in wireframe models fabricated using a robotized 3D printing system.
MeGU: Machine-Guided Unlearning with Target Feature Disentanglement
Feb 19, 2026The growing concern over training data privacy has elevated the "Right to be Forgotten" into a critical requirement, thereby raising the demand for effective Machine Unlearning. However, existing unlearning approaches commonly suffer from a fundamental trade-off: aggressively erasing the influence of target data often degrades model utility on retained data, while conservative strategies leave residual target information intact. In this work, the intrinsic representation properties learned during model pretraining are analyzed. It is demonstrated that semantic class concepts are entangled at the feature-pattern level, sharing associated features while preserving concept-specific discriminative components. This entanglement fundamentally limits the effectiveness of existing unlearning paradigms. Motivated by this insight, we propose Machine-Guided Unlearning (MeGU), a novel framework that guides unlearning through concept-aware re-alignment. Specifically, Multi-modal Large Language Models (MLLMs) are leveraged to explicitly determine re-alignment directions for target samples by assigning semantically meaningful perturbing labels. To improve efficiency, inter-class conceptual similarities estimated by the MLLM are encoded into a lightweight transition matrix. Furthermore, MeGU introduces a positive-negative feature noise pair to explicitly disentangle target concept influence. During finetuning, the negative noise suppresses target-specific feature patterns, while the positive noise reinforces remaining associated features and aligns them with perturbing concepts. This coordinated design enables selective disruption of target-specific representations while preserving shared semantic structures. As a result, MeGU enables controlled and selective forgetting, effectively mitigating both under-unlearning and over-unlearning.
i-PhysGaussian: Implicit Physical Simulation for 3D Gaussian Splatting
Feb 19, 2026Physical simulation predicts future states of objects based on material properties and external loads, enabling blueprints for both Industry and Engineering to conduct risk management. Current 3D reconstruction-based simulators typically rely on explicit, step-wise updates, which are sensitive to step time and suffer from rapid accuracy degradation under complicated scenarios, such as high-stiffness materials or quasi-static movement. To address this, we introduce i-PhysGaussian, a framework that couples 3D Gaussian Splatting (3DGS) with an implicit Material Point Method (MPM) integrator. Unlike explicit methods, our solution obtains an end-of-step state by minimizing a momentum-balance residual through implicit Newton-type optimization with a GMRES solver. This formulation significantly reduces time-step sensitivity and ensures physical consistency. Our results demonstrate that i-PhysGaussian maintains stability at up to 20x larger time steps than explicit baselines, preserving structural coherence and smooth motion even in complex dynamic transitions.
BrokenBind: Universal Modality Exploration beyond Dataset Boundaries
Feb 06, 2026Multi-modal learning combines various modalities to provide a comprehensive understanding of real-world problems. A common strategy is to directly bind different modalities together in a specific joint embedding space. However, the capability of existing methods is restricted within the modalities presented in the given dataset, thus they are biased when generalizing to unpresented modalities in downstream tasks. As a result, due to such inflexibility, the viability of previous methods is seriously hindered by the cost of acquiring multi-modal datasets. In this paper, we introduce BrokenBind, which focuses on binding modalities that are presented from different datasets. To achieve this, BrokenBind simultaneously leverages multiple datasets containing the modalities of interest and one shared modality. Though the two datasets do not correspond to each other due to distribution mismatch, we can capture their relationship to generate pseudo embeddings to fill in the missing modalities of interest, enabling flexible and generalized multi-modal learning. Under our framework, any two modalities can be bound together, free from the dataset limitation, to achieve universal modality exploration. Further, to reveal the capability of our method, we study intensified scenarios where more than two datasets are needed for modality binding and show the effectiveness of BrokenBind in low-data regimes. Through extensive evaluation, we carefully justify the superiority of BrokenBind compared to well-known multi-modal baseline methods.
Is Gradient Ascent Really Necessary? Memorize to Forget for Machine Unlearning
Feb 06, 2026For ethical and safe AI, machine unlearning rises as a critical topic aiming to protect sensitive, private, and copyrighted knowledge from misuse. To achieve this goal, it is common to conduct gradient ascent (GA) to reverse the training on undesired data. However, such a reversal is prone to catastrophic collapse, which leads to serious performance degradation in general tasks. As a solution, we propose model extrapolation as an alternative to GA, which reaches the counterpart direction in the hypothesis space from one model given another reference model. Therefore, we leverage the original model as the reference, further train it to memorize undesired data while keeping prediction consistency on the rest retained data, to obtain a memorization model. Counterfactual as it might sound, a forget model can be obtained via extrapolation from the memorization model to the reference model. Hence, we avoid directly acquiring the forget model using GA, but proceed with gradient descent for the memorization model, which successfully stabilizes the machine unlearning process. Our model extrapolation is simple and efficient to implement, and it can also effectively converge throughout training to achieve improved unlearning performance.
Bifrost: Steering Strategic Trajectories to Bridge Contextual Gaps for Self-Improving Agents
Feb 05, 2026Autonomous agents excel in self-improvement through reflection and iterative refinement, which reuse successful task trajectories as in-context examples to assist subsequent reasoning. However, shifting across tasks often introduces a context mismatch. Hence, existing approaches either discard the trajectories or manipulate them using heuristics, leading to a non-negligible fine-tuning cost or unguaranteed performance. To bridge this gap, we reveal a context-trajectory correlation, where shifts of context are highly parallel with shifts of trajectory. Based on this finding, we propose BrIdge contextual gap FoR imprOvised trajectory STeering (Bifrost), a training-free method that leverages context differences to precisely guide the adaptation of previously solved trajectories towards the target task, mitigating the misalignment caused by context shifts. Our trajectory adaptation is conducted at the representation level using agent hidden states, ensuring trajectory transformation accurately aligns with the target context in a shared space. Across diverse benchmarks, Bifrost consistently outperforms existing trajectory reuse and finetuned self-improvement methods, demonstrating that agents can effectively leverage past experiences despite substantial context shifts.
Trustworthy Machine Learning under Distribution Shifts
Dec 29, 2025Machine Learning (ML) has been a foundational topic in artificial intelligence (AI), providing both theoretical groundwork and practical tools for its exciting advancements. From ResNet for visual recognition to Transformer for vision-language alignment, the AI models have achieved superior capability to humans. Furthermore, the scaling law has enabled AI to initially develop general intelligence, as demonstrated by Large Language Models (LLMs). To this stage, AI has had an enormous influence on society and yet still keeps shaping the future for humanity. However, distribution shift remains a persistent ``Achilles' heel'', fundamentally limiting the reliability and general usefulness of ML systems. Moreover, generalization under distribution shift would also cause trust issues for AIs. Motivated by these challenges, my research focuses on \textit{Trustworthy Machine Learning under Distribution Shifts}, with the goal of expanding AI's robustness, versatility, as well as its responsibility and reliability. We carefully study the three common distribution shifts into: (1) Perturbation Shift, (2) Domain Shift, and (3) Modality Shift. For all scenarios, we also rigorously investigate trustworthiness via three aspects: (1) Robustness, (2) Explainability, and (3) Adaptability. Based on these dimensions, we propose effective solutions and fundamental insights, meanwhile aiming to enhance the critical ML problems, such as efficiency, adaptability, and safety.
Exploring Criteria of Loss Reweighting to Enhance LLM Unlearning
May 17, 2025Loss reweighting has shown significant benefits for machine unlearning with large language models (LLMs). However, their exact functionalities are left unclear and the optimal strategy remains an open question, thus impeding the understanding and improvement of existing methodologies. In this paper, we identify two distinct goals of loss reweighting, namely, Saturation and Importance -- the former indicates that those insufficiently optimized data should be emphasized, while the latter stresses some critical data that are most influential for loss minimization. To study their usefulness, we design specific reweighting strategies for each goal and evaluate their respective effects on unlearning. We conduct extensive empirical analyses on well-established benchmarks, and summarize some important observations as follows: (i) Saturation enhances efficacy more than importance-based reweighting, and their combination can yield additional improvements. (ii) Saturation typically allocates lower weights to data with lower likelihoods, whereas importance-based reweighting does the opposite. (iii) The efficacy of unlearning is also largely influenced by the smoothness and granularity of the weight distributions. Based on these findings, we propose SatImp, a simple reweighting method that combines the advantages of both saturation and importance. Empirical results on extensive datasets validate the efficacy of our method, potentially bridging existing research gaps and indicating directions for future research. Our code is available at https://github.com/Puning97/SatImp-for-LLM-Unlearning.
Towards Modality Generalization: A Benchmark and Prospective Analysis
Dec 24, 2024



Multi-modal learning has achieved remarkable success by integrating information from various modalities, achieving superior performance in tasks like recognition and retrieval compared to uni-modal approaches. However, real-world scenarios often present novel modalities that are unseen during training due to resource and privacy constraints, a challenge current methods struggle to address. This paper introduces Modality Generalization (MG), which focuses on enabling models to generalize to unseen modalities. We define two cases: weak MG, where both seen and unseen modalities can be mapped into a joint embedding space via existing perceptors, and strong MG, where no such mappings exist. To facilitate progress, we propose a comprehensive benchmark featuring multi-modal algorithms and adapt existing methods that focus on generalization. Extensive experiments highlight the complexity of MG, exposing the limitations of existing methods and identifying key directions for future research. Our work provides a foundation for advancing robust and adaptable multi-modal models, enabling them to handle unseen modalities in realistic scenarios.
Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning
Dec 05, 2023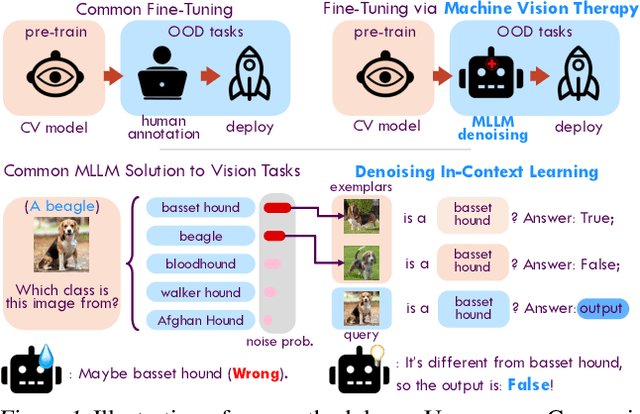
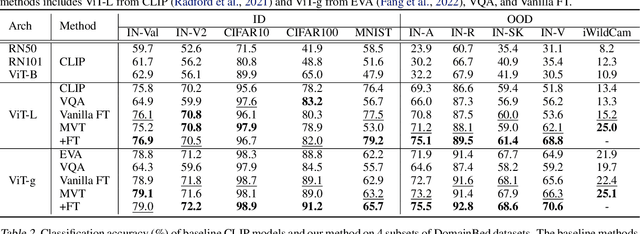
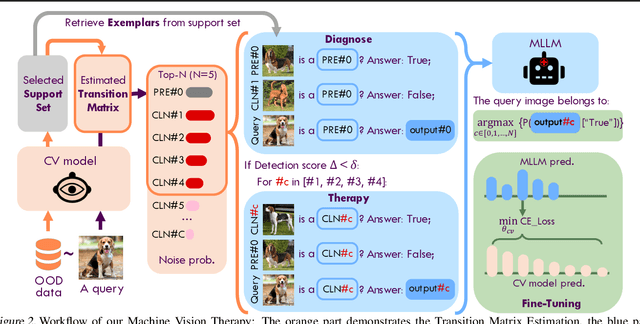
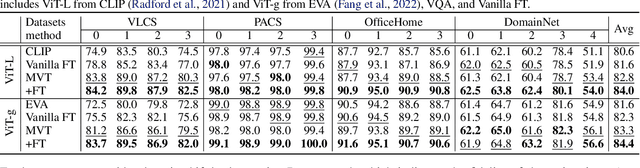
Although vision models such as Contrastive Language-Image Pre-Training (CLIP) show impressive generalization performance, their zero-shot robustness is still limited under Out-of-Distribution (OOD) scenarios without fine-tuning. Instead of undesirably providing human supervision as commonly done, it is possible to take advantage of Multi-modal Large Language Models (MLLMs) that hold powerful visual understanding abilities. However, MLLMs are shown to struggle with vision problems due to the incompatibility of tasks, thus hindering their utilization. In this paper, we propose to effectively leverage MLLMs to conduct Machine Vision Therapy which aims to rectify the noisy predictions from vision models. By fine-tuning with the denoised labels, the learning model performance can be boosted in an unsupervised manner. To solve the incompatibility issue, we propose a novel Denoising In-Context Learning (DICL) strategy to align vision tasks with MLLMs. Concretely, by estimating a transition matrix that captures the probability of one class being confused with another, an instruction containing a correct exemplar and an erroneous one from the most probable noisy class can be constructed. Such an instruction can help any MLLMs with ICL ability to detect and rectify incorrect predictions of vision models. Through extensive experiments on ImageNet, WILDS, DomainBed, and other OOD datasets, we carefully validate the quantitative and qualitative effectiveness of our method. Our code is available at https://github.com/tmllab/Machine_Vision_Therapy.