 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Criteria of Loss Reweighting to Enhance LLM Unlearning
May 17, 2025Loss reweighting has shown significant benefits for machine unlearning with large language models (LLMs). However, their exact functionalities are left unclear and the optimal strategy remains an open question, thus impeding the understanding and improvement of existing methodologies. In this paper, we identify two distinct goals of loss reweighting, namely, Saturation and Importance -- the former indicates that those insufficiently optimized data should be emphasized, while the latter stresses some critical data that are most influential for loss minimization. To study their usefulness, we design specific reweighting strategies for each goal and evaluate their respective effects on unlearning. We conduct extensive empirical analyses on well-established benchmarks, and summarize some important observations as follows: (i) Saturation enhances efficacy more than importance-based reweighting, and their combination can yield additional improvements. (ii) Saturation typically allocates lower weights to data with lower likelihoods, whereas importance-based reweighting does the opposite. (iii) The efficacy of unlearning is also largely influenced by the smoothness and granularity of the weight distributions. Based on these findings, we propose SatImp, a simple reweighting method that combines the advantages of both saturation and importance. Empirical results on extensive datasets validate the efficacy of our method, potentially bridging existing research gaps and indicating directions for future research. Our code is available at https://github.com/Puning97/SatImp-for-LLM-Unlearning.
Deep Learning Technology for Face Forgery Detection: A Survey
Sep 24, 2024



Currently, the rapid development of computer vision and deep learning has enabled the creation or manipulation of high-fidelity facial images and videos via deep generative approaches. This technology, also known as deepfake, has achieved dramatic progress and become increasingly popular in social media. However, the technology can generate threats to personal privacy and national security by spreading misinformation. To diminish the risks of deepfake, it is desirable to develop powerful forgery detection methods to distinguish fake faces from real faces. This paper presents a comprehensive survey of recent deep learning-based approaches for facial forgery detection. We attempt to provide the reader with a deeper understanding of the current advances as well as the major challenges for deepfake detection based on deep learning. We present an overview of deepfake techniques and analyse the characteristics of various deepfake datasets. We then provide a systematic review of different categories of deepfake detection and state-of-the-art deepfake detection methods. The drawbacks of existing detection methods are analyzed, and future research directions are discussed to address the challenges in improving both the performance and generalization of deepfake detection.
Unlearning with Control: Assessing Real-world Utility for Large Language Model Unlearning
Jun 13, 2024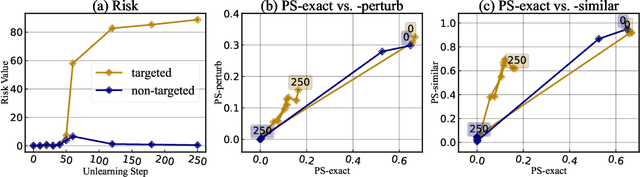

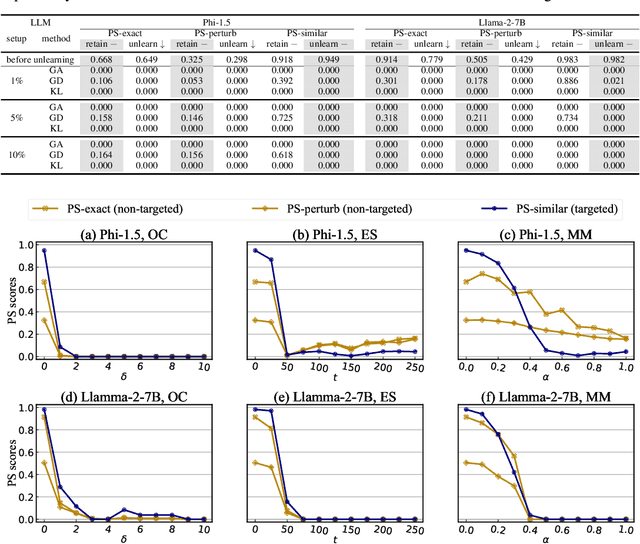
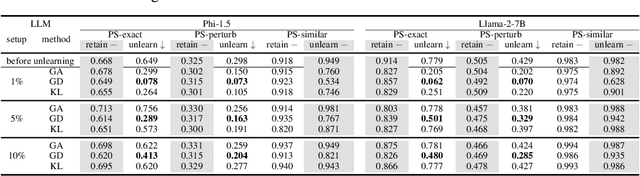
The compelling goal of eradicating undesirable data behaviors, while preserving usual model functioning, underscores the significance of machine unlearning within the domain of large language models (LLMs). Recent research has begun to approach LLM unlearning via gradient ascent (GA) -- increasing the prediction risk for those training strings targeted to be unlearned, thereby erasing their parameterized responses. Despite their simplicity and efficiency, we suggest that GA-based methods face the propensity towards excessive unlearning, resulting in various undesirable model behaviors, such as catastrophic forgetting, that diminish their practical utility. In this paper, we suggest a set of metrics that can capture multiple facets of real-world utility and propose several controlling methods that can regulate the extent of excessive unlearning. Accordingly, we suggest a general framework to better reflect the practical efficacy of various unlearning methods -- we begin by controlling the unlearning procedures/unlearned models such that no excessive unlearning occurs and follow by the evaluation for unlearning efficacy. Our experimental analysis on established benchmarks revealed that GA-based methods are far from perfect in practice, as strong unlearning is at the high cost of hindering the model utility. We conclude that there is still a long way towards practical and effective LLM unlearning, and more efforts are required in this field.
AUTO: Adaptive Outlier Optimization for Online Test-Time OOD Detection
Mar 22, 2023



Out-of-distribution (OOD) detection is a crucial aspect of deploying machine learning models in open-world applications. Empirical evidence suggests that training with auxiliary outliers substantially improves OOD detection. However, such outliers typically exhibit a distribution gap compared to the test OOD data and do not cover all possible test OOD scenarios. Additionally, incorporating these outliers introduces additional training burdens. In this paper, we introduce a novel paradigm called test-time OOD detection, which utilizes unlabeled online data directly at test time to improve OOD detection performance. While this paradigm is efficient, it also presents challenges such as catastrophic forgetting. To address these challenges, we propose adaptive outlier optimization (AUTO), which consists of an in-out-aware filter, an ID memory bank, and a semantically-consistent objective. AUTO adaptively mines pseudo-ID and pseudo-OOD samples from test data, utilizing them to optimize networks in real time during inference. Extensive results on CIFAR-10, CIFAR-100, and ImageNet benchmarks demonstrate that AUTO significantly enhances OOD detection performance.