 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Technology for Face Forgery Detection: A Survey
Sep 24, 2024



Currently, the rapid development of computer vision and deep learning has enabled the creation or manipulation of high-fidelity facial images and videos via deep generative approaches. This technology, also known as deepfake, has achieved dramatic progress and become increasingly popular in social media. However, the technology can generate threats to personal privacy and national security by spreading misinformation. To diminish the risks of deepfake, it is desirable to develop powerful forgery detection methods to distinguish fake faces from real faces. This paper presents a comprehensive survey of recent deep learning-based approaches for facial forgery detection. We attempt to provide the reader with a deeper understanding of the current advances as well as the major challenges for deepfake detection based on deep learning. We present an overview of deepfake techniques and analyse the characteristics of various deepfake datasets. We then provide a systematic review of different categories of deepfake detection and state-of-the-art deepfake detection methods. The drawbacks of existing detection methods are analyzed, and future research directions are discussed to address the challenges in improving both the performance and generalization of deepfake detection.
Learning Spatiotemporal Inconsistency via Thumbnail Layout for Face Deepfake Detection
Mar 20, 2024



The deepfake threats to society and cybersecurity have provoked significant public apprehension, driving intensified efforts within the realm of deepfake video detection. Current video-level methods are mostly based on {3D CNNs} resulting in high computational demands, although have achieved good performance. This paper introduces an elegantly simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. This transformation process involves sequentially masking frames at the same positions within each frame. These frames are then resized into sub-frames and reorganized into the predetermined layout, forming thumbnails. TALL is model-agnostic and has remarkable simplicity, necessitating only minimal code modifications. Furthermore, we introduce a graph reasoning block (GRB) and semantic consistency (SC) loss to strengthen TALL, culminating in TALL++. GRB enhances interactions between different semantic regions to capture semantic-level inconsistency clues. The semantic consistency loss imposes consistency constraints on semantic features to improve model generalization ability. Extensive experiments on intra-dataset, cross-dataset, diffusion-generated image detection, and deepfake generation method recognition show that TALL++ achieves results surpassing or comparable to the state-of-the-art methods, demonstrating the effectiveness of our approaches for various deepfake detection problems. The code is available at https://github.com/rainy-xu/TALL4Deepfake.
TALL: Thumbnail Layout for Deepfake Video Detection
Jul 14, 2023The growing threats of deepfakes to society and cybersecurity have raised enormous public concerns, and increasing efforts have been devoted to this critical topic of deepfake video detection. Existing video methods achieve good performance but are computationally intensive. This paper introduces a simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. Specifically, consecutive frames are masked in a fixed position in each frame to improve generalization, then resized to sub-images and rearranged into a pre-defined layout as the thumbnail. TALL is model-agnostic and extremely simple by only modifying a few lines of code. Inspired by the success of vision transformers, we incorporate TALL into Swin Transformer, forming an efficient and effective method TALL-Swin. Extensive experiments on intra-dataset and cross-dataset validate the validity and superiority of TALL and SOTA TALL-Swin. TALL-Swin achieves 90.79$\%$ AUC on the challenging cross-dataset task, FaceForensics++ $\to$ Celeb-DF. The code is available at https://github.com/rainy-xu/TALL4Deepfake.
mmWave RIS Phase Shift Feedback Based on Knowledge Base Autoencoder Framework
Apr 27, 2023In reconfigurable intelligent surface (RIS)-assisted wireless communication systems, adjusting the phase shift of RIS unit cells is crucial for improving communication performance. Due to massive RIS unit cells, the number of phase shift parameters fed back from the base station (BS) to the RIS is enormous, which occupies a large number of frequency resources. In this paper, we propose a feedback scheme for millimeter-wave RIS phase shift applying a knowledge base autoencoder framework, in which the learnable knowledge base is shared at the BS and the RIS. The encoder at the BS compresses the RIS phase shift matrix to multiple feature vectors. Then the knowledge base vectors index is obtained by calculating the similarity between feature vectors and knowledge base vectors and transmitted to the RIS. With utilizing the index at the RIS, the corresponding knowledge base vectors are extracted and used as the decoder's inputs to reconstruct the phase shift of the RIS. Simulation results show that the proposed scheme can significantly improve the accuracy of phase shift feedback and impressively reduce the amount of RIS phase shift feedback data. Moreover, the proposed scheme is easy to deploy in actual scenarios due to lower complexity and fewer parameters.
Development and Evaluation of Conformal Prediction Methods for QSAR
Apr 03, 2023


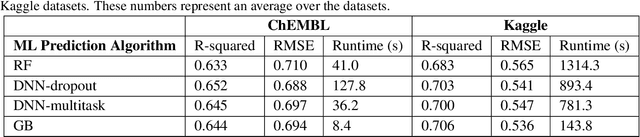
The quantitative structure-activity relationship (QSAR) regression model is a commonly used technique for predicting biological activities of compounds using their molecular descriptors. Predictions from QSAR models can help, for example, to optimize molecular structure; prioritize compounds for further experimental testing; and estimate their toxicity. In addition to the accurate estimation of the activity, it is highly desirable to obtain some estimate of the uncertainty associated with the prediction, e.g., calculate a prediction interval (PI) containing the true molecular activity with a pre-specified probability, say 70%, 90% or 95%. The challenge is that most machine learning (ML) algorithms that achieve superior predictive performance require some add-on methods for estimating uncertainty of their prediction. The development of these algorithms is an active area of research by statistical and ML communities but their implementation for QSAR modeling remains limited. Conformal prediction (CP) is a promising approach. It is agnostic to the prediction algorithm and can produce valid prediction intervals under some weak assumptions on the data distribution. We proposed computationally efficient CP algorithms tailored to the most advanced ML models, including Deep Neural Networks and Gradient Boosting Machines. The validity and efficiency of proposed conformal predictors are demonstrated on a diverse collection of QSAR datasets as well as simulation studies.
Unsupervised Learning Discriminative MIG Detectors in Nonhomogeneous Clutter
Apr 24, 2022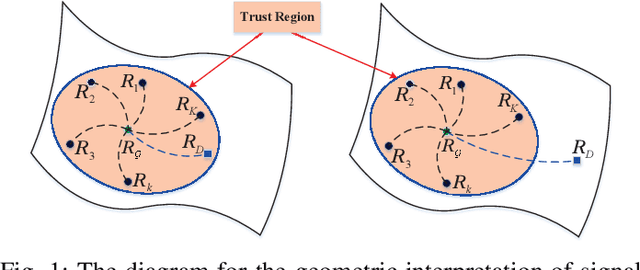
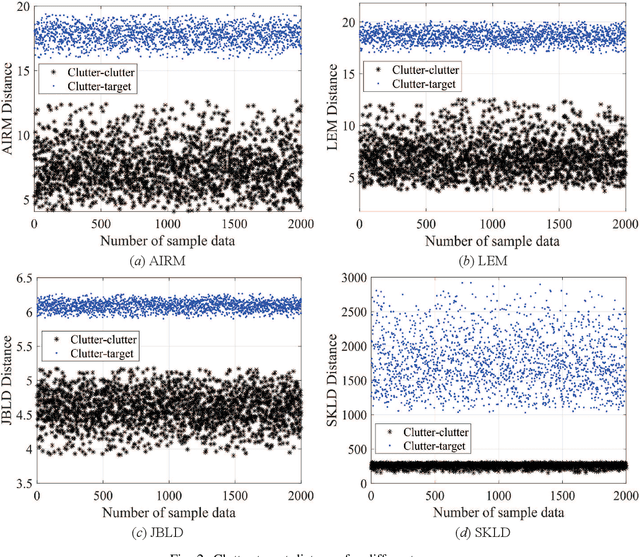
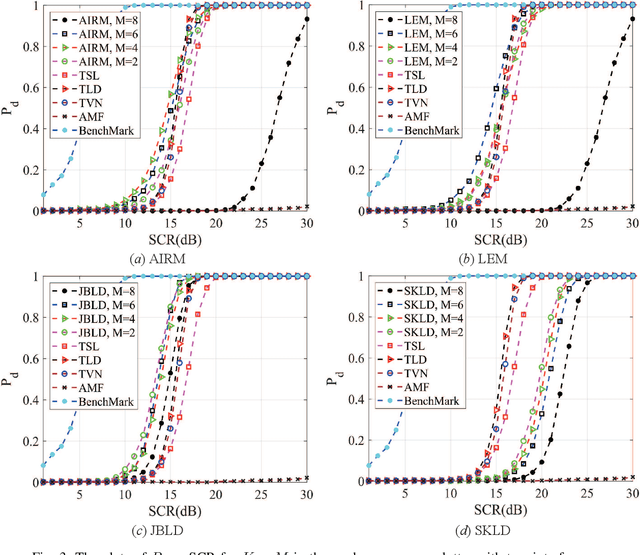
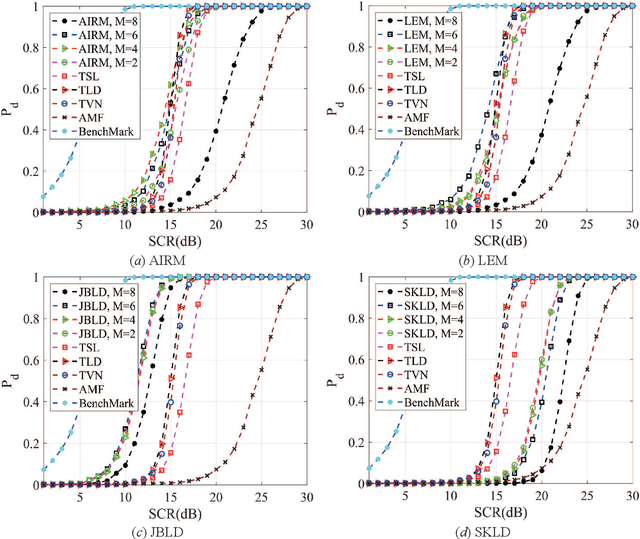
Principal component analysis (PCA) is a common used pattern analysis method that maps high-dimensional data into a lower-dimensional space maximizing the data variance, that results in the promotion of separability of data. Inspired by the principle of PCA, a novel type of learning discriminative matrix information geometry (MIG) detectors in the unsupervised scenario are developed, and applied to signal detection in nonhomogeneous environments. Hermitian positive-definite (HPD) matrices can be used to model the sample data, while the clutter covariance matrix is estimated by the geometric mean of a set of secondary HPD matrices. We define a projection that maps the HPD matrices in a high-dimensional manifold to a low-dimensional and more discriminative one to increase the degree of separation of HPD matrices by maximizing the data variance. Learning a mapping can be formulated as a two-step mini-max optimization problem in Riemannian manifolds, which can be solved by the Riemannian gradient descent algorithm. Three discriminative MIG detectors are illustrated with respect to different geometric measures, i.e., the Log-Euclidean metric, the Jensen--Bregman LogDet divergence and the symmetrized Kullback--Leibler divergence. Simulation results show that performance improvements of the novel MIG detectors can be achieved compared with the conventional detectors and their state-of-the-art counterparts within nonhomogeneous environments.