 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo MLLMs Really Understand Space? A Mathematical Reasoning Evaluation
Feb 12, 2026Multimodal large language models (MLLMs) have achieved strong performance on perception-oriented tasks, yet their ability to perform mathematical spatial reasoning, defined as the capacity to parse and manipulate two- and three-dimensional relations, remains unclear. Humans easily solve textbook-style spatial reasoning problems with over 95\% accuracy, but we find that most leading MLLMs fail to reach even 60\% on the same tasks. This striking gap highlights spatial reasoning as a fundamental weakness of current models. To investigate this gap, we present MathSpatial, a unified framework for evaluating and improving spatial reasoning in MLLMs. MathSpatial includes three complementary components: (i) MathSpatial-Bench, a benchmark of 2K problems across three categories and eleven subtypes, designed to isolate reasoning difficulty from perceptual noise; (ii) MathSpatial-Corpus, a training dataset of 8K additional problems with verified solutions; and (iii) MathSpatial-SRT, which models reasoning as structured traces composed of three atomic operations--Correlate, Constrain, and Infer. Experiments show that fine-tuning Qwen2.5-VL-7B on MathSpatial achieves competitive accuracy while reducing tokens by 25\%. MathSpatial provides the first large-scale resource that disentangles perception from reasoning, enabling precise measurement and comprehensive understanding of mathematical spatial reasoning in MLLMs.
Learning Fair Domain Adaptation with Virtual Label Distribution
Jan 26, 2026Unsupervised Domain Adaptation (UDA) aims to mitigate performance degradation when training and testing data are sampled from different distributions. While significant progress has been made in enhancing overall accuracy, most existing methods overlook performance disparities across categories-an issue we refer to as category fairness. Our empirical analysis reveals that UDA classifiers tend to favor certain easy categories while neglecting difficult ones. To address this, we propose Virtual Label-distribution-aware Learning (VILL), a simple yet effective framework designed to improve worst-case performance while preserving high overall accuracy. The core of VILL is an adaptive re-weighting strategy that amplifies the influence of hard-to-classify categories. Furthermore, we introduce a KL-divergence-based re-balancing strategy, which explicitly adjusts decision boundaries to enhance category fairness. Experiments on commonly used datasets demonstrate that VILL can be seamlessly integrated as a plug-and-play module into existing UDA methods, significantly improving category fairness.
Reassessing the Role of Supervised Fine-Tuning: An Empirical Study in VLM Reasoning
Dec 14, 2025Recent advances in vision-language models (VLMs) reasoning have been largely attributed to the rise of reinforcement Learning (RL), which has shifted the community's focus away from the supervised fine-tuning (SFT) paradigm. Many studies suggest that introducing the SFT stage not only fails to improve reasoning ability but may also negatively impact model training. In this study, we revisit this RL-centric belief through a systematic and controlled comparison of SFT and RL on VLM Reasoning. Using identical data sources, we find that the relative effectiveness of SFT and RL is conditional and strongly influenced by model capacity, data scale, and data distribution. Contrary to common assumptions, our findings show that SFT plays a crucial role across several scenarios: (1) Effectiveness for weaker models. SFT more reliably elicits reasoning capabilities in smaller or weaker VLMs. (2) Data efficiency. SFT with only 2K achieves comparable or better reasoning performance to RL with 20K. (3) Cross-modal transferability. SFT demonstrates stronger generalization across modalities. Moreover, we identify a pervasive issue of deceptive rewards, where higher rewards fail to correlate with better reasoning accuracy in RL. These results challenge the prevailing "RL over SFT" narrative. They highlight that the role of SFT may have been underestimated and support a more balanced post-training pipeline in which SFT and RL function as complementary components.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025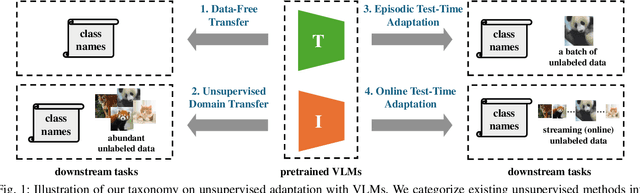
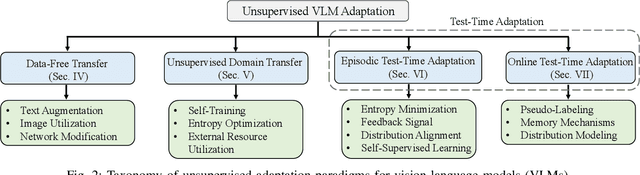
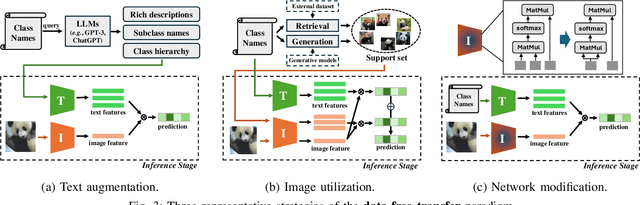
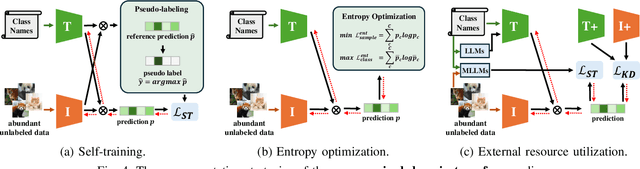
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
R-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning
Apr 15, 2025Vision-language models (VLMs), such as CLIP, have gained significant popularity as foundation models, with numerous fine-tuning methods developed to enhance performance on downstream tasks. However, due to their inherent vulnerability and the common practice of selecting from a limited set of open-source models, VLMs suffer from a higher risk of adversarial attacks than traditional vision models. Existing defense techniques typically rely on adversarial fine-tuning during training, which requires labeled data and lacks of flexibility for downstream tasks. To address these limitations, we propose robust test-time prompt tuning (R-TPT), which mitigates the impact of adversarial attacks during the inference stage. We first reformulate the classic marginal entropy objective by eliminating the term that introduces conflicts under adversarial conditions, retaining only the pointwise entropy minimization. Furthermore, we introduce a plug-and-play reliability-based weighted ensembling strategy, which aggregates useful information from reliable augmented views to strengthen the defense. R-TPT enhances defense against adversarial attacks without requiring labeled training data while offering high flexibility for inference tasks. Extensive experiments on widely used benchmarks with various attacks demonstrate the effectiveness of R-TPT. The code is available in https://github.com/TomSheng21/R-TPT.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024



So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
Prototypical Distillation and Debiased Tuning for Black-box Unsupervised Domain Adaptation
Dec 30, 2024



Unsupervised domain adaptation aims to transfer knowledge from a related, label-rich source domain to an unlabeled target domain, thereby circumventing the high costs associated with manual annotation. Recently, there has been growing interest in source-free domain adaptation, a paradigm in which only a pre-trained model, rather than the labeled source data, is provided to the target domain. Given the potential risk of source data leakage via model inversion attacks, this paper introduces a novel setting called black-box domain adaptation, where the source model is accessible only through an API that provides the predicted label along with the corresponding confidence value for each query. We develop a two-step framework named $\textbf{Pro}$totypical $\textbf{D}$istillation and $\textbf{D}$ebiased tun$\textbf{ing}$ ($\textbf{ProDDing}$). In the first step, ProDDing leverages both the raw predictions from the source model and prototypes derived from the target domain as teachers to distill a customized target model. In the second step, ProDDing keeps fine-tuning the distilled model by penalizing logits that are biased toward certain classes. Empirical results across multiple benchmarks demonstrate that ProDDing outperforms existing black-box domain adaptation methods. Moreover, in the case of hard-label black-box domain adaptation, where only predicted labels are available, ProDDing achieves significant improvements over these methods. Code will be available at \url{https://github.com/tim-learn/ProDDing/}.
STAMP: Outlier-Aware Test-Time Adaptation with Stable Memory Replay
Jul 22, 2024



Test-time adaptation (TTA) aims to address the distribution shift between the training and test data with only unlabeled data at test time. Existing TTA methods often focus on improving recognition performance specifically for test data associated with classes in the training set. However, during the open-world inference process, there are inevitably test data instances from unknown classes, commonly referred to as outliers. This paper pays attention to the problem that conducts both sample recognition and outlier rejection during inference while outliers exist. To address this problem, we propose a new approach called STAble Memory rePlay (STAMP), which performs optimization over a stable memory bank instead of the risky mini-batch. In particular, the memory bank is dynamically updated by selecting low-entropy and label-consistent samples in a class-balanced manner. In addition, we develop a self-weighted entropy minimization strategy that assigns higher weight to low-entropy samples. Extensive results demonstrate that STAMP outperforms existing TTA methods in terms of both recognition and outlier detection performance. The code is released at https://github.com/yuyongcan/STAMP.
Learning Spatiotemporal Inconsistency via Thumbnail Layout for Face Deepfake Detection
Mar 20, 2024



The deepfake threats to society and cybersecurity have provoked significant public apprehension, driving intensified efforts within the realm of deepfake video detection. Current video-level methods are mostly based on {3D CNNs} resulting in high computational demands, although have achieved good performance. This paper introduces an elegantly simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. This transformation process involves sequentially masking frames at the same positions within each frame. These frames are then resized into sub-frames and reorganized into the predetermined layout, forming thumbnails. TALL is model-agnostic and has remarkable simplicity, necessitating only minimal code modifications. Furthermore, we introduce a graph reasoning block (GRB) and semantic consistency (SC) loss to strengthen TALL, culminating in TALL++. GRB enhances interactions between different semantic regions to capture semantic-level inconsistency clues. The semantic consistency loss imposes consistency constraints on semantic features to improve model generalization ability. Extensive experiments on intra-dataset, cross-dataset, diffusion-generated image detection, and deepfake generation method recognition show that TALL++ achieves results surpassing or comparable to the state-of-the-art methods, demonstrating the effectiveness of our approaches for various deepfake detection problems. The code is available at https://github.com/rainy-xu/TALL4Deepfake.
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation
Feb 06, 2024



Contrastive Language-Image Pretraining (CLIP) has gained popularity for its remarkable zero-shot capacity. Recent research has focused on developing efficient fine-tuning methods, such as prompt learning and adapter, to enhance CLIP's performance in downstream tasks. However, these methods still require additional training time and computational resources, which is undesirable for devices with limited resources. In this paper, we revisit a classical algorithm, Gaussian Discriminant Analysis (GDA), and apply it to the downstream classification of CLIP. Typically, GDA assumes that features of each class follow Gaussian distributions with identical covariance. By leveraging Bayes' formula, the classifier can be expressed in terms of the class means and covariance, which can be estimated from the data without the need for training. To integrate knowledge from both visual and textual modalities, we ensemble it with the original zero-shot classifier within CLIP. Extensive results on 17 datasets validate that our method surpasses or achieves comparable results with state-of-the-art methods on few-shot classification, imbalanced learning, and out-of-distribution generalization. In addition, we extend our method to base-to-new generalization and unsupervised learning, once again demonstrating its superiority over competing approaches. Our code is publicly available at \url{https://github.com/mrflogs/ICLR24}.