 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Safety-utility Trade-off in LLM Alignment via Adaptive Safe Context Learning
Feb 14, 2026While reasoning models have achieved remarkable success in complex reasoning tasks, their increasing power necessitates stringent safety measures. For safety alignment, the core challenge lies in the inherent trade-off between safety and utility. However, prevailing alignment strategies typically construct CoT training data with explicit safety rules via context distillation. This approach inadvertently limits reasoning capabilities by creating a rigid association between rule memorization and refusal. To mitigate the safety-utility trade-off, we propose the Adaptive Safe Context Learning (ASCL) framework to improve the reasoning given proper context. ASCL formulates safety alignment as a multi-turn tool-use process, empowering the model to autonomously decide when to consult safety rules and how to generate the ongoing reasoning. Furthermore, to counteract the preference for rule consultation during RL, we introduce Inverse Frequency Policy Optimization (IFPO) to rebalance advantage estimates. By decoupling rule retrieval and subsequent reasoning, our method achieves higher overall performance compared to baselines.
Do MLLMs Really Understand Space? A Mathematical Reasoning Evaluation
Feb 12, 2026Multimodal large language models (MLLMs) have achieved strong performance on perception-oriented tasks, yet their ability to perform mathematical spatial reasoning, defined as the capacity to parse and manipulate two- and three-dimensional relations, remains unclear. Humans easily solve textbook-style spatial reasoning problems with over 95\% accuracy, but we find that most leading MLLMs fail to reach even 60\% on the same tasks. This striking gap highlights spatial reasoning as a fundamental weakness of current models. To investigate this gap, we present MathSpatial, a unified framework for evaluating and improving spatial reasoning in MLLMs. MathSpatial includes three complementary components: (i) MathSpatial-Bench, a benchmark of 2K problems across three categories and eleven subtypes, designed to isolate reasoning difficulty from perceptual noise; (ii) MathSpatial-Corpus, a training dataset of 8K additional problems with verified solutions; and (iii) MathSpatial-SRT, which models reasoning as structured traces composed of three atomic operations--Correlate, Constrain, and Infer. Experiments show that fine-tuning Qwen2.5-VL-7B on MathSpatial achieves competitive accuracy while reducing tokens by 25\%. MathSpatial provides the first large-scale resource that disentangles perception from reasoning, enabling precise measurement and comprehensive understanding of mathematical spatial reasoning in MLLMs.
One Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
Reassessing the Role of Supervised Fine-Tuning: An Empirical Study in VLM Reasoning
Dec 14, 2025Recent advances in vision-language models (VLMs) reasoning have been largely attributed to the rise of reinforcement Learning (RL), which has shifted the community's focus away from the supervised fine-tuning (SFT) paradigm. Many studies suggest that introducing the SFT stage not only fails to improve reasoning ability but may also negatively impact model training. In this study, we revisit this RL-centric belief through a systematic and controlled comparison of SFT and RL on VLM Reasoning. Using identical data sources, we find that the relative effectiveness of SFT and RL is conditional and strongly influenced by model capacity, data scale, and data distribution. Contrary to common assumptions, our findings show that SFT plays a crucial role across several scenarios: (1) Effectiveness for weaker models. SFT more reliably elicits reasoning capabilities in smaller or weaker VLMs. (2) Data efficiency. SFT with only 2K achieves comparable or better reasoning performance to RL with 20K. (3) Cross-modal transferability. SFT demonstrates stronger generalization across modalities. Moreover, we identify a pervasive issue of deceptive rewards, where higher rewards fail to correlate with better reasoning accuracy in RL. These results challenge the prevailing "RL over SFT" narrative. They highlight that the role of SFT may have been underestimated and support a more balanced post-training pipeline in which SFT and RL function as complementary components.
A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models
Sep 04, 2025The development of Long-CoT reasoning has advanced LLM performance across various tasks, including language understanding, complex problem solving, and code generation. This paradigm enables models to generate intermediate reasoning steps, thereby improving both accuracy and interpretability. However, despite these advancements, a comprehensive understanding of how CoT-based reasoning affects the trustworthiness of language models remains underdeveloped. In this paper, we survey recent work on reasoning models and CoT techniques, focusing on five core dimensions of trustworthy reasoning: truthfulness, safety, robustness, fairness, and privacy. For each aspect, we provide a clear and structured overview of recent studies in chronological order, along with detailed analyses of their methodologies, findings, and limitations. Future research directions are also appended at the end for reference and discussion. Overall, while reasoning techniques hold promise for enhancing model trustworthiness through hallucination mitigation, harmful content detection, and robustness improvement, cutting-edge reasoning models themselves often suffer from comparable or even greater vulnerabilities in safety, robustness, and privacy. By synthesizing these insights, we hope this work serves as a valuable and timely resource for the AI safety community to stay informed on the latest progress in reasoning trustworthiness. A full list of related papers can be found at \href{https://github.com/ybwang119/Awesome-reasoning-safety}{https://github.com/ybwang119/Awesome-reasoning-safety}.
Test-Time Immunization: A Universal Defense Framework Against Jailbreaks for (Multimodal) Large Language Models
May 28, 2025While (multimodal) large language models (LLMs) have attracted widespread attention due to their exceptional capabilities, they remain vulnerable to jailbreak attacks. Various defense methods are proposed to defend against jailbreak attacks, however, they are often tailored to specific types of jailbreak attacks, limiting their effectiveness against diverse adversarial strategies. For instance, rephrasing-based defenses are effective against text adversarial jailbreaks but fail to counteract image-based attacks. To overcome these limitations, we propose a universal defense framework, termed Test-time IMmunization (TIM), which can adaptively defend against various jailbreak attacks in a self-evolving way. Specifically, TIM initially trains a gist token for efficient detection, which it subsequently applies to detect jailbreak activities during inference. When jailbreak attempts are identified, TIM implements safety fine-tuning using the detected jailbreak instructions paired with refusal answers. Furthermore, to mitigate potential performance degradation in the detector caused by parameter updates during safety fine-tuning, we decouple the fine-tuning process from the detection module. Extensive experiments on both LLMs and multimodal LLMs demonstrate the efficacy of TIM.
STAMP: Outlier-Aware Test-Time Adaptation with Stable Memory Replay
Jul 22, 2024



Test-time adaptation (TTA) aims to address the distribution shift between the training and test data with only unlabeled data at test time. Existing TTA methods often focus on improving recognition performance specifically for test data associated with classes in the training set. However, during the open-world inference process, there are inevitably test data instances from unknown classes, commonly referred to as outliers. This paper pays attention to the problem that conducts both sample recognition and outlier rejection during inference while outliers exist. To address this problem, we propose a new approach called STAble Memory rePlay (STAMP), which performs optimization over a stable memory bank instead of the risky mini-batch. In particular, the memory bank is dynamically updated by selecting low-entropy and label-consistent samples in a class-balanced manner. In addition, we develop a self-weighted entropy minimization strategy that assigns higher weight to low-entropy samples. Extensive results demonstrate that STAMP outperforms existing TTA methods in terms of both recognition and outlier detection performance. The code is released at https://github.com/yuyongcan/STAMP.
Benchmarking Test-Time Adaptation against Distribution Shifts in Image Classification
Jul 06, 2023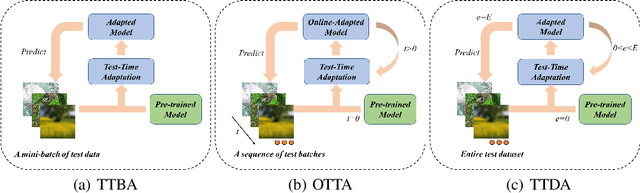


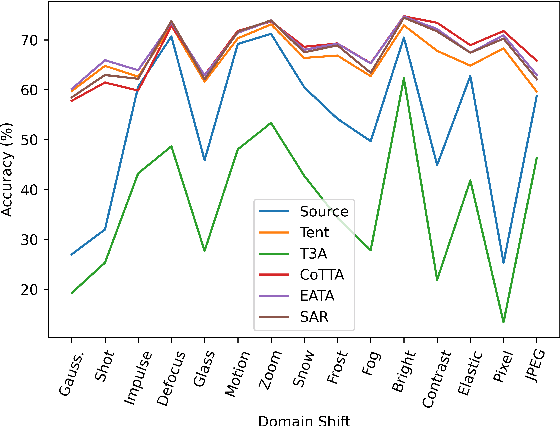
Test-time adaptation (TTA) is a technique aimed at enhancing the generalization performance of models by leveraging unlabeled samples solely during prediction. Given the need for robustness in neural network systems when faced with distribution shifts, numerous TTA methods have recently been proposed. However, evaluating these methods is often done under different settings, such as varying distribution shifts, backbones, and designing scenarios, leading to a lack of consistent and fair benchmarks to validate their effectiveness. To address this issue, we present a benchmark that systematically evaluates 13 prominent TTA methods and their variants on five widely used image classification datasets: CIFAR-10-C, CIFAR-100-C, ImageNet-C, DomainNet, and Office-Home. These methods encompass a wide range of adaptation scenarios (e.g. online adaptation v.s. offline adaptation, instance adaptation v.s. batch adaptation v.s. domain adaptation). Furthermore, we explore the compatibility of different TTA methods with diverse network backbones. To implement this benchmark, we have developed a unified framework in PyTorch, which allows for consistent evaluation and comparison of the TTA methods across the different datasets and network architectures. By establishing this benchmark, we aim to provide researchers and practitioners with a reliable means of assessing and comparing the effectiveness of TTA methods in improving model robustness and generalization performance. Our code is available at https://github.com/yuyongcan/Benchmark-TTA.