 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReassessing the Role of Supervised Fine-Tuning: An Empirical Study in VLM Reasoning
Dec 14, 2025Recent advances in vision-language models (VLMs) reasoning have been largely attributed to the rise of reinforcement Learning (RL), which has shifted the community's focus away from the supervised fine-tuning (SFT) paradigm. Many studies suggest that introducing the SFT stage not only fails to improve reasoning ability but may also negatively impact model training. In this study, we revisit this RL-centric belief through a systematic and controlled comparison of SFT and RL on VLM Reasoning. Using identical data sources, we find that the relative effectiveness of SFT and RL is conditional and strongly influenced by model capacity, data scale, and data distribution. Contrary to common assumptions, our findings show that SFT plays a crucial role across several scenarios: (1) Effectiveness for weaker models. SFT more reliably elicits reasoning capabilities in smaller or weaker VLMs. (2) Data efficiency. SFT with only 2K achieves comparable or better reasoning performance to RL with 20K. (3) Cross-modal transferability. SFT demonstrates stronger generalization across modalities. Moreover, we identify a pervasive issue of deceptive rewards, where higher rewards fail to correlate with better reasoning accuracy in RL. These results challenge the prevailing "RL over SFT" narrative. They highlight that the role of SFT may have been underestimated and support a more balanced post-training pipeline in which SFT and RL function as complementary components.
Learning Feature Recovery Transformer for Occluded Person Re-identification
Jan 05, 2023
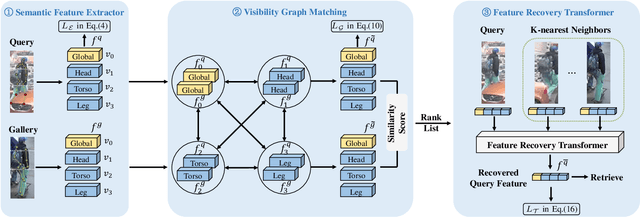


One major issue that challenges person re-identification (Re-ID) is the ubiquitous occlusion over the captured persons. There are two main challenges for the occluded person Re-ID problem, i.e., the interference of noise during feature matching and the loss of pedestrian information brought by the occlusions. In this paper, we propose a new approach called Feature Recovery Transformer (FRT) to address the two challenges simultaneously, which mainly consists of visibility graph matching and feature recovery transformer. To reduce the interference of the noise during feature matching, we mainly focus on visible regions that appear in both images and develop a visibility graph to calculate the similarity. In terms of the second challenge, based on the developed graph similarity, for each query image, we propose a recovery transformer that exploits the feature sets of its $k$-nearest neighbors in the gallery to recover the complete features. Extensive experiments across different person Re-ID datasets, including occluded, partial and holistic datasets, demonstrate the effectiveness of FRT. Specifically, FRT significantly outperforms state-of-the-art results by at least 6.2\% Rank-1 accuracy and 7.2\% mAP scores on the challenging Occluded-Duke dataset. The code is available at https://github.com/xbq1994/Feature-Recovery-Transformer.
Gait Recognition in the Wild with Dense 3D Representations and A Benchmark
Apr 06, 2022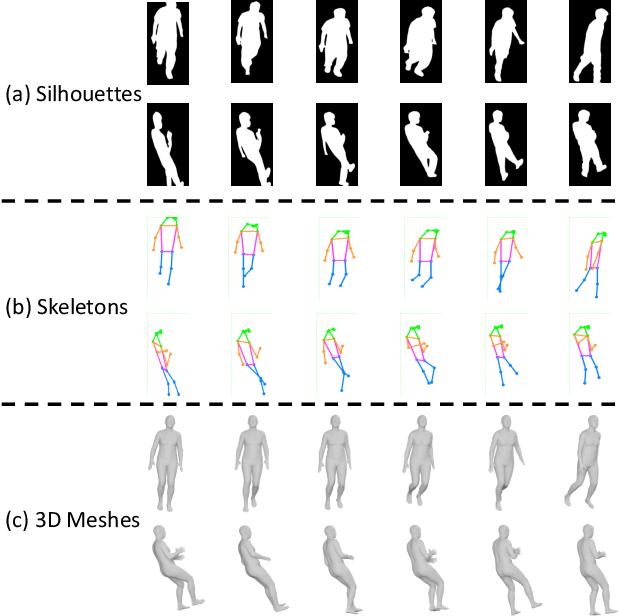
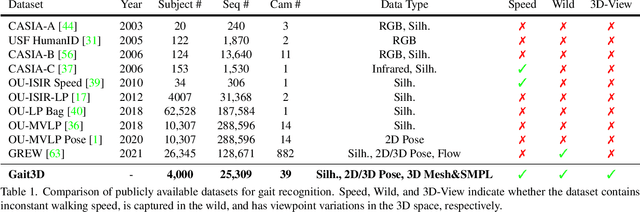
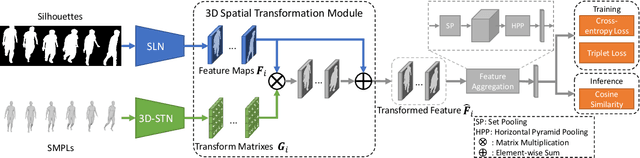
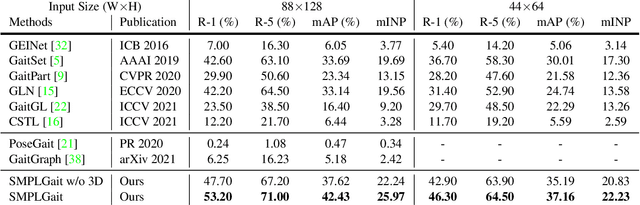
Existing studies for gait recognition are dominated by 2D representations like the silhouette or skeleton of the human body in constrained scenes. However, humans live and walk in the unconstrained 3D space, so projecting the 3D human body onto the 2D plane will discard a lot of crucial information like the viewpoint, shape, and dynamics for gait recognition. Therefore, this paper aims to explore dense 3D representations for gait recognition in the wild, which is a practical yet neglected problem. In particular, we propose a novel framework to explore the 3D Skinned Multi-Person Linear (SMPL) model of the human body for gait recognition, named SMPLGait. Our framework has two elaborately-designed branches of which one extracts appearance features from silhouettes, the other learns knowledge of 3D viewpoints and shapes from the 3D SMPL model. In addition, due to the lack of suitable datasets, we build the first large-scale 3D representation-based gait recognition dataset, named Gait3D. It contains 4,000 subjects and over 25,000 sequences extracted from 39 cameras in an unconstrained indoor scene. More importantly, it provides 3D SMPL models recovered from video frames which can provide dense 3D information of body shape, viewpoint, and dynamics. Based on Gait3D, we comprehensively compare our method with existing gait recognition approaches, which reflects the superior performance of our framework and the potential of 3D representations for gait recognition in the wild. The code and dataset are available at https://gait3d.github.io.
META: Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Dec 16, 2021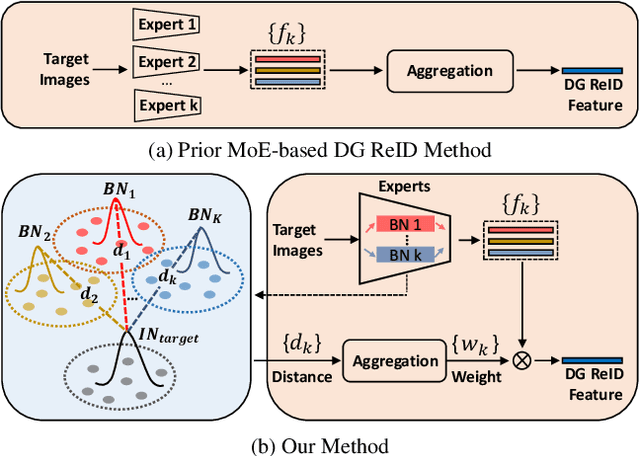
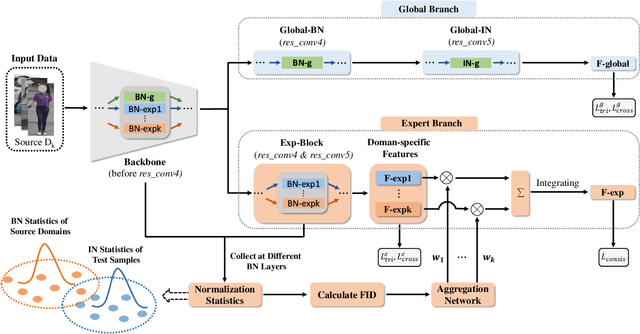
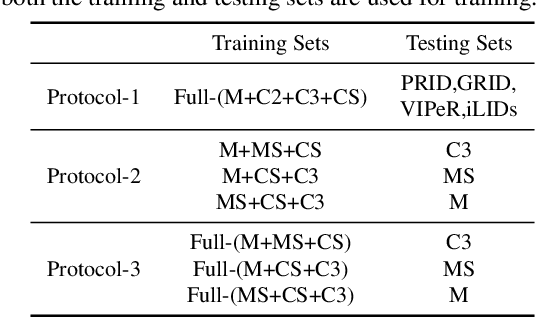
Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimicking Embedding via oThers' Aggregation (META) for DG ReID. To avoid the large model size, experts in META do not add a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation network to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, we can expect META to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG ReID methods by a large margin.
Semi-Supervised Domain Generalizable Person Re-Identification
Sep 09, 2021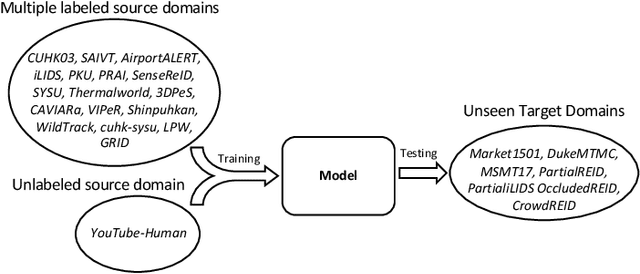
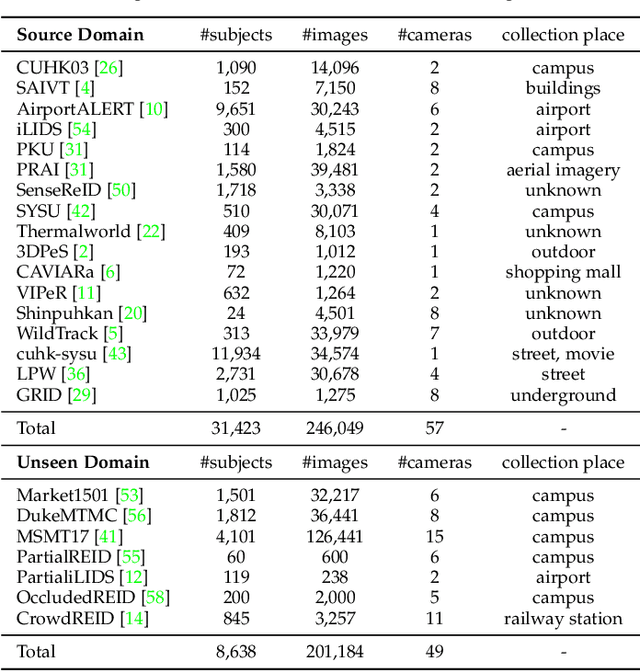
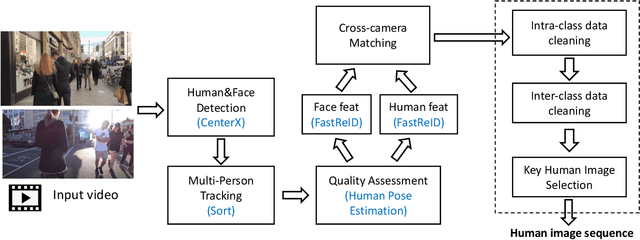

Existing person re-identification (re-id) methods are stuck when deployed to a new unseen scenario despite the success in cross-camera person matching. Recent efforts have been substantially devoted to domain adaptive person re-id where extensive unlabeled data in the new scenario are utilized in a transductive learning manner. However, for each scenario, it is required to first collect enough data and then train such a domain adaptive re-id model, thus restricting their practical application. Instead, we aim to explore multiple labeled datasets to learn generalized domain-invariant representations for person re-id, which is expected universally effective for each new-coming re-id scenario. To pursue practicability in real-world systems, we collect all the person re-id datasets (20 datasets) in this field and select the three most frequently used datasets (i.e., Market1501, DukeMTMC, and MSMT17) as unseen target domains. In addition, we develop DataHunter that collects over 300K+ weak annotated images named YouTube-Human from YouTube street-view videos, which joins 17 remaining full labeled datasets to form multiple source domains. On such a large and challenging benchmark called FastHuman (~440K+ labeled images), we further propose a simple yet effective Semi-Supervised Knowledge Distillation (SSKD) framework. SSKD effectively exploits the weakly annotated data by assigning soft pseudo labels to YouTube-Human to improve models' generalization ability. Experiments on several protocols verify the effectiveness of the proposed SSKD framework on domain generalizable person re-id, which is even comparable to supervised learning on the target domains. Lastly, but most importantly, we hope the proposed benchmark FastHuman could bring the next development of domain generalizable person re-id algorithms.
Learning Instance-level Spatial-Temporal Patterns for Person Re-identification
Jul 31, 2021
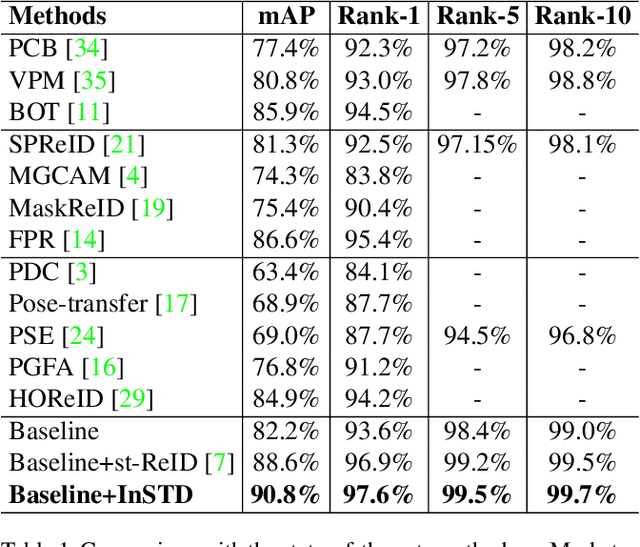


Person re-identification (Re-ID) aims to match pedestrians under dis-joint cameras. Most Re-ID methods formulate it as visual representation learning and image search, and its accuracy is consequently affected greatly by the search space. Spatial-temporal information has been proven to be efficient to filter irrelevant negative samples and significantly improve Re-ID accuracy. However, existing spatial-temporal person Re-ID methods are still rough and do not exploit spatial-temporal information sufficiently. In this paper, we propose a novel Instance-level and Spatial-Temporal Disentangled Re-ID method (InSTD), to improve Re-ID accuracy. In our proposed framework, personalized information such as moving direction is explicitly considered to further narrow down the search space. Besides, the spatial-temporal transferring probability is disentangled from joint distribution to marginal distribution, so that outliers can also be well modeled. Abundant experimental analyses are presented, which demonstrates the superiority and provides more insights into our method. The proposed method achieves mAP of 90.8% on Market-1501 and 89.1% on DukeMTMC-reID, improving from the baseline 82.2% and 72.7%, respectively. Besides, in order to provide a better benchmark for person re-identification, we release a cleaned data list of DukeMTMC-reID with this paper: https://github.com/RenMin1991/cleaned-DukeMTMC-reID/
Group-aware Label Transfer for Domain Adaptive Person Re-identification
Mar 23, 2021

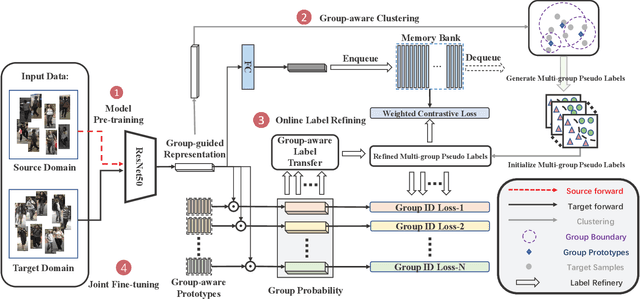

Unsupervised Domain Adaptive (UDA) person re-identification (ReID) aims at adapting the model trained on a labeled source-domain dataset to a target-domain dataset without any further annotations. Most successful UDA-ReID approaches combine clustering-based pseudo-label prediction with representation learning and perform the two steps in an alternating fashion. However, offline interaction between these two steps may allow noisy pseudo labels to substantially hinder the capability of the model. In this paper, we propose a Group-aware Label Transfer (GLT) algorithm, which enables the online interaction and mutual promotion of pseudo-label prediction and representation learning. Specifically, a label transfer algorithm simultaneously uses pseudo labels to train the data while refining the pseudo labels as an online clustering algorithm. It treats the online label refinery problem as an optimal transport problem, which explores the minimum cost for assigning M samples to N pseudo labels. More importantly, we introduce a group-aware strategy to assign implicit attribute group IDs to samples. The combination of the online label refining algorithm and the group-aware strategy can better correct the noisy pseudo label in an online fashion and narrow down the search space of the target identity. The effectiveness of the proposed GLT is demonstrated by the experimental results (Rank-1 accuracy) for Market1501$\to$DukeMTMC (82.0\%) and DukeMTMC$\to$Market1501 (92.2\%), remarkably closing the gap between unsupervised and supervised performance on person re-identification.
Black Re-ID: A Head-shoulder Descriptor for the Challenging Problem of Person Re-Identification
Aug 19, 2020

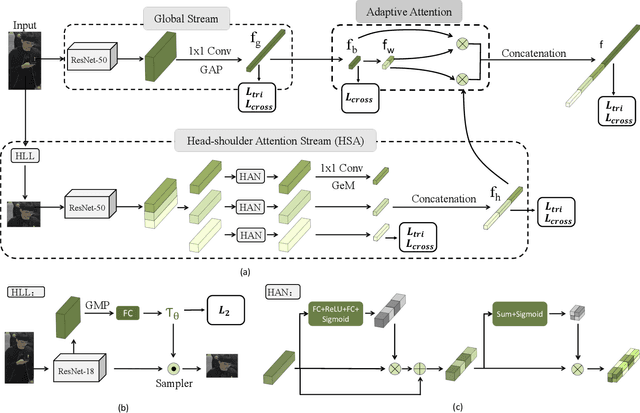
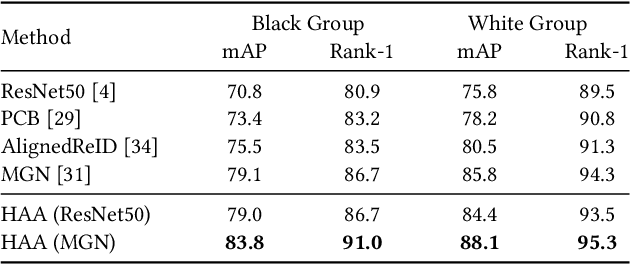
Person re-identification (Re-ID) aims at retrieving an input person image from a set of images captured by multiple cameras. Although recent Re-ID methods have made great success, most of them extract features in terms of the attributes of clothing (e.g., color, texture). However, it is common for people to wear black clothes or be captured by surveillance systems in low light illumination, in which cases the attributes of the clothing are severely missing. We call this problem the Black Re-ID problem. To solve this problem, rather than relying on the clothing information, we propose to exploit head-shoulder features to assist person Re-ID. The head-shoulder adaptive attention network (HAA) is proposed to learn the head-shoulder feature and an innovative ensemble method is designed to enhance the generalization of our model. Given the input person image, the ensemble method would focus on the head-shoulder feature by assigning a larger weight if the individual insides the image is in black clothing. Due to the lack of a suitable benchmark dataset for studying the Black Re-ID problem, we also contribute the first Black-reID dataset, which contains 1274 identities in training set. Extensive evaluations on the Black-reID, Market1501 and DukeMTMC-reID datasets show that our model achieves the best result compared with the state-of-the-art Re-ID methods on both Black and conventional Re-ID problems. Furthermore, our method is also proved to be effective in dealing with person Re-ID in similar clothing. Our code and dataset are avaliable on https://github.com/xbq1994/.
FastReID: A Pytorch Toolbox for General Instance Re-identification
Jun 29, 2020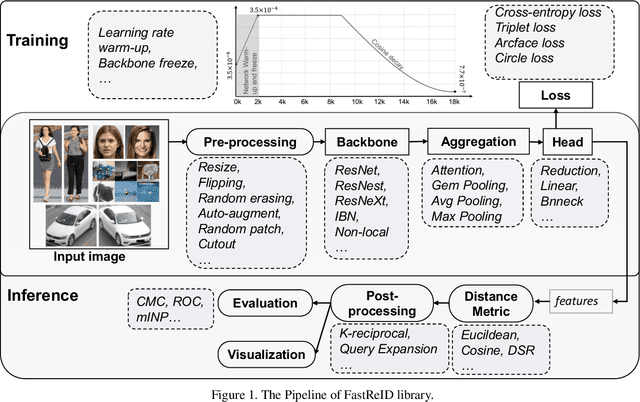
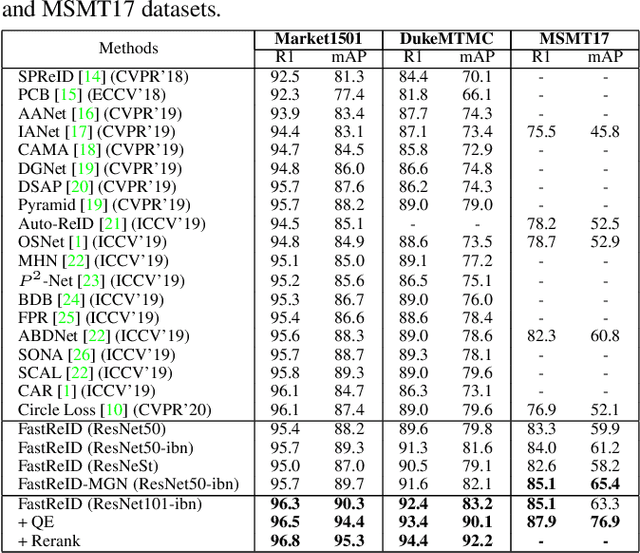

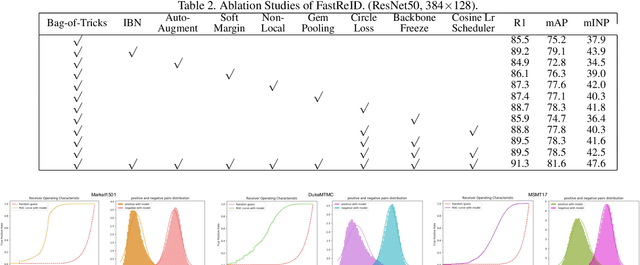
General Instance Re-identification is a very important task in the computer vision, which can be widely used in many practical applications, such as person/vehicle re-identification, face recognition, wildlife protection, commodity tracing, and snapshop, etc.. To meet the increasing application demand for general instance re-identification, we present FastReID as a widely used software system in JD AI Research. In FastReID, highly modular and extensible design makes it easy for the researcher to achieve new research ideas. Friendly manageable system configuration and engineering deployment functions allow practitioners to quickly deploy models into productions. We have implemented some state-of-the-art projects, including person re-id, partial re-id, cross-domain re-id and vehicle re-id, and plan to release these pre-trained models on multiple benchmark datasets. FastReID is by far the most general and high-performance toolbox that supports single and multiple GPU servers, you can reproduce our project results very easily and are very welcome to use it, the code and models are available at https://github.com/JDAI-CV/fast-reid.
Foreground-aware Pyramid Reconstruction for Alignment-free Occluded Person Re-identification
Apr 11, 2019
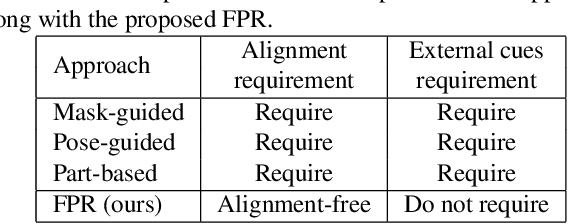


Re-identifying a person across multiple disjoint camera views is important for intelligent video surveillance, smart retailing and many other applications. However, existing person re-identification (ReID) methods are challenged by the ubiquitous occlusion over persons and suffer from performance degradation. This paper proposes a novel occlusion-robust and alignment-free model for occluded person ReID and extends its application to realistic and crowded scenarios. The proposed model first leverages the full convolution network (FCN) and pyramid pooling to extract spatial pyramid features. Then an alignment-free matching approach, namely Foreground-aware Pyramid Reconstruction (FPR), is developed to accurately compute matching scores between occluded persons, despite their different scales and sizes. FPR uses the error from robust reconstruction over spatial pyramid features to measure similarities between two persons. More importantly, we design an occlusion-sensitive foreground probability generator that focuses more on clean human body parts to refine the similarity computation with less contamination from occlusion. The FPR is easily embedded into any end-to-end person ReID models. The effectiveness of the proposed method is clearly demonstrated by the experimental results (Rank-1 accuracy) on three occluded person datasets: Partial REID (78.30\%), Partial iLIDS (68.08\%) and Occluded REID (81.00\%); and three benchmark person datasets: Market1501 (95.42\%), DukeMTMC (88.64\%) and CUHK03 (76.08\%)