 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025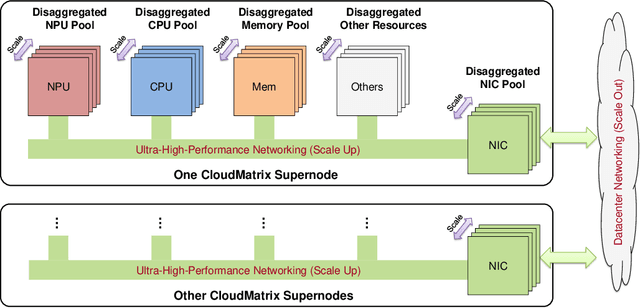
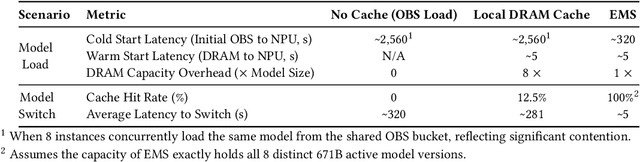
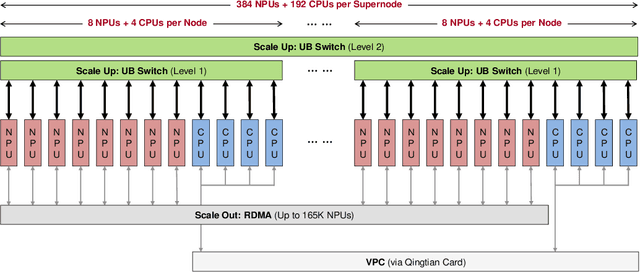
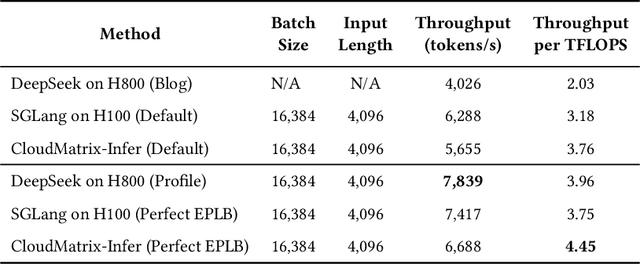
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
PanoOcc: Unified Occupancy Representation for Camera-based 3D Panoptic Segmentation
Jun 16, 2023



Comprehensive modeling of the surrounding 3D world is key to the success of autonomous driving. However, existing perception tasks like object detection, road structure segmentation, depth & elevation estimation, and open-set object localization each only focus on a small facet of the holistic 3D scene understanding task. This divide-and-conquer strategy simplifies the algorithm development procedure at the cost of losing an end-to-end unified solution to the problem. In this work, we address this limitation by studying camera-based 3D panoptic segmentation, aiming to achieve a unified occupancy representation for camera-only 3D scene understanding. To achieve this, we introduce a novel method called PanoOcc, which utilizes voxel queries to aggregate spatiotemporal information from multi-frame and multi-view images in a coarse-to-fine scheme, integrating feature learning and scene representation into a unified occupancy representation. We have conducted extensive ablation studies to verify the effectiveness and efficiency of the proposed method. Our approach achieves new state-of-the-art results for camera-based semantic segmentation and panoptic segmentation on the nuScenes dataset. Furthermore, our method can be easily extended to dense occupancy prediction and has shown promising performance on the Occ3D benchmark. The code will be released at https://github.com/Robertwyq/PanoOcc.
detrex: Benchmarking Detection Transformers
Jun 13, 2023



The DEtection TRansformer (DETR) algorithm has received considerable attention in the research community and is gradually emerging as a mainstream approach for object detection and other perception tasks. However, the current field lacks a unified and comprehensive benchmark specifically tailored for DETR-based models. To address this issue, we develop a unified, highly modular, and lightweight codebase called detrex, which supports a majority of the mainstream DETR-based instance recognition algorithms, covering various fundamental tasks, including object detection, segmentation, and pose estimation. We conduct extensive experiments under detrex and perform a comprehensive benchmark for DETR-based models. Moreover, we enhance the performance of detection transformers through the refinement of training hyper-parameters, providing strong baselines for supported algorithms.We hope that detrex could offer research communities a standardized and unified platform to evaluate and compare different DETR-based models while fostering a deeper understanding and driving advancements in DETR-based instance recognition. Our code is available at https://github.com/IDEA-Research/detrex. The project is currently being actively developed. We encourage the community to use detrex codebase for further development and contributions.
DA-BEV: Depth Aware BEV Transformer for 3D Object Detection
Feb 25, 2023



In this paper, we present DA-BEV, an implicit depth learning method for Transformer-based camera-only 3D object detection in bird's eye view (BEV). First, a Depth-Aware Spatial Cross-Attention (DA-SCA) module is proposed to take depth into consideration when querying image features to construct BEV features. Then, to make the BEV feature more depth-aware, we introduce an auxiliary learning task, called Depth-wise Contrastive Learning (DCL), by sampling positive and negative BEV features along each ray that connects an object and a camera. DA-SCA and DCL jointly improve the BEV representation and make it more depth-aware. We show that DA-BEV obtains significant improvement (+2.8 NDS) on nuScenes val under the same setting when compared with the baseline method BEVFormer. DA-BEV also achieves strong results of 60.0 NDS and 51.5mAP on nuScenes test with pre-trained VoVNet-99 as backbone. We will release our code.
Audit to Forget: A Unified Method to Revoke Patients' Private Data in Intelligent Healthcare
Feb 20, 2023Revoking personal private data is one of the basic human rights, which has already been sheltered by several privacy-preserving laws in many countries. However, with the development of data science, machine learning and deep learning techniques, this right is usually neglected or violated as more and more patients' data are being collected and used for model training, especially in intelligent healthcare, thus making intelligent healthcare a sector where technology must meet the law, regulations, and privacy principles to ensure that the innovation is for the common good. In order to secure patients' right to be forgotten, we proposed a novel solution by using auditing to guide the forgetting process, where auditing means determining whether a dataset has been used to train the model and forgetting requires the information of a query dataset to be forgotten from the target model. We unified these two tasks by introducing a new approach called knowledge purification. To implement our solution, we developed AFS, a unified open-source software, which is able to evaluate and revoke patients' private data from pre-trained deep learning models. We demonstrated the generality of AFS by applying it to four tasks on different datasets with various data sizes and architectures of deep learning networks. The software is publicly available at \url{https://github.com/JoshuaChou2018/AFS}.
Semi-Supervised Domain Generalizable Person Re-Identification
Sep 09, 2021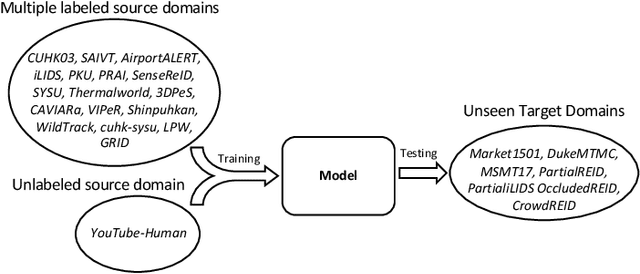
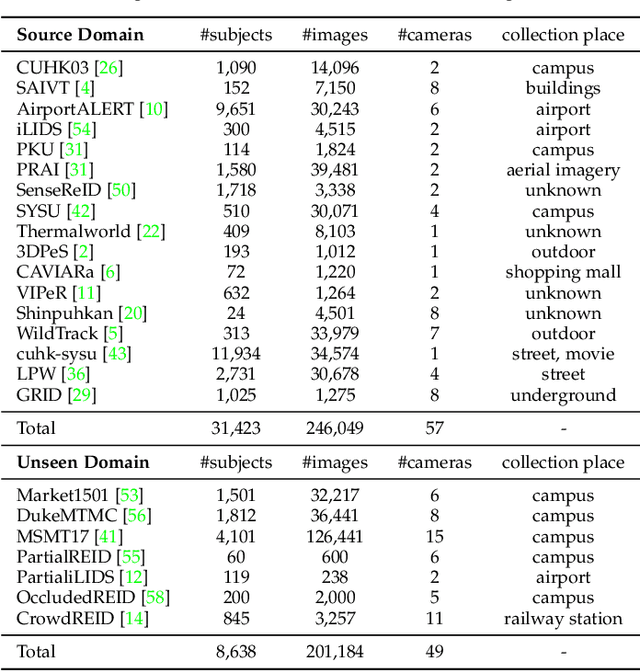

Existing person re-identification (re-id) methods are stuck when deployed to a new unseen scenario despite the success in cross-camera person matching. Recent efforts have been substantially devoted to domain adaptive person re-id where extensive unlabeled data in the new scenario are utilized in a transductive learning manner. However, for each scenario, it is required to first collect enough data and then train such a domain adaptive re-id model, thus restricting their practical application. Instead, we aim to explore multiple labeled datasets to learn generalized domain-invariant representations for person re-id, which is expected universally effective for each new-coming re-id scenario. To pursue practicability in real-world systems, we collect all the person re-id datasets (20 datasets) in this field and select the three most frequently used datasets (i.e., Market1501, DukeMTMC, and MSMT17) as unseen target domains. In addition, we develop DataHunter that collects over 300K+ weak annotated images named YouTube-Human from YouTube street-view videos, which joins 17 remaining full labeled datasets to form multiple source domains. On such a large and challenging benchmark called FastHuman (~440K+ labeled images), we further propose a simple yet effective Semi-Supervised Knowledge Distillation (SSKD) framework. SSKD effectively exploits the weakly annotated data by assigning soft pseudo labels to YouTube-Human to improve models' generalization ability. Experiments on several protocols verify the effectiveness of the proposed SSKD framework on domain generalizable person re-id, which is even comparable to supervised learning on the target domains. Lastly, but most importantly, we hope the proposed benchmark FastHuman could bring the next development of domain generalizable person re-id algorithms.
Learning Instance-level Spatial-Temporal Patterns for Person Re-identification
Jul 31, 2021
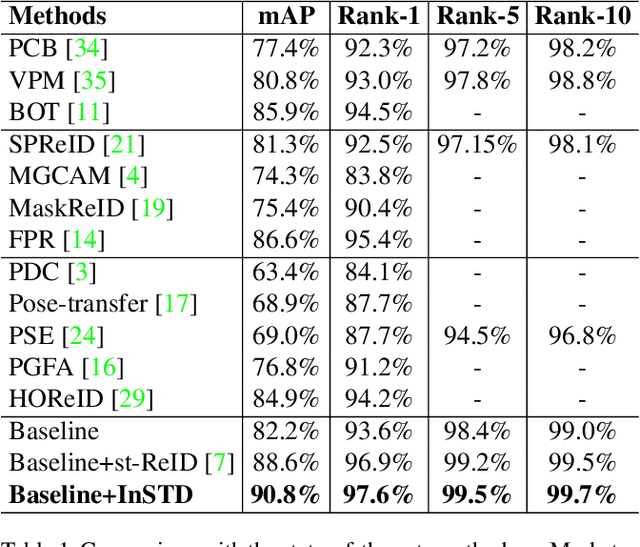


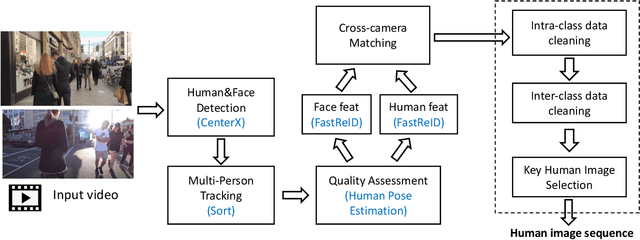
Person re-identification (Re-ID) aims to match pedestrians under dis-joint cameras. Most Re-ID methods formulate it as visual representation learning and image search, and its accuracy is consequently affected greatly by the search space. Spatial-temporal information has been proven to be efficient to filter irrelevant negative samples and significantly improve Re-ID accuracy. However, existing spatial-temporal person Re-ID methods are still rough and do not exploit spatial-temporal information sufficiently. In this paper, we propose a novel Instance-level and Spatial-Temporal Disentangled Re-ID method (InSTD), to improve Re-ID accuracy. In our proposed framework, personalized information such as moving direction is explicitly considered to further narrow down the search space. Besides, the spatial-temporal transferring probability is disentangled from joint distribution to marginal distribution, so that outliers can also be well modeled. Abundant experimental analyses are presented, which demonstrates the superiority and provides more insights into our method. The proposed method achieves mAP of 90.8% on Market-1501 and 89.1% on DukeMTMC-reID, improving from the baseline 82.2% and 72.7%, respectively. Besides, in order to provide a better benchmark for person re-identification, we release a cleaned data list of DukeMTMC-reID with this paper: https://github.com/RenMin1991/cleaned-DukeMTMC-reID/
Black Re-ID: A Head-shoulder Descriptor for the Challenging Problem of Person Re-Identification
Aug 19, 2020

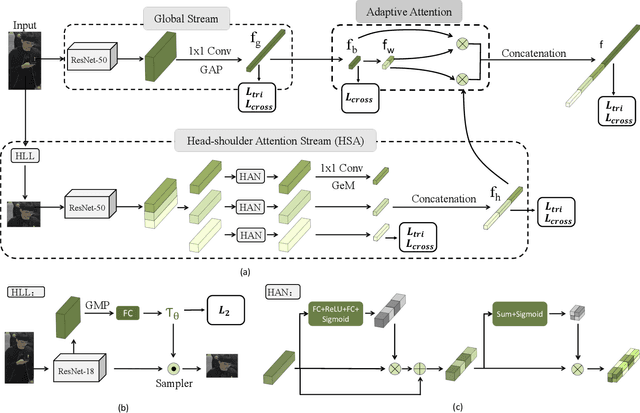
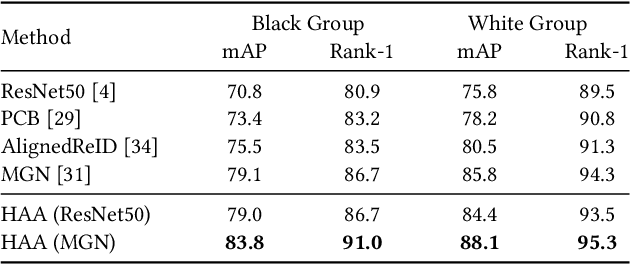
Person re-identification (Re-ID) aims at retrieving an input person image from a set of images captured by multiple cameras. Although recent Re-ID methods have made great success, most of them extract features in terms of the attributes of clothing (e.g., color, texture). However, it is common for people to wear black clothes or be captured by surveillance systems in low light illumination, in which cases the attributes of the clothing are severely missing. We call this problem the Black Re-ID problem. To solve this problem, rather than relying on the clothing information, we propose to exploit head-shoulder features to assist person Re-ID. The head-shoulder adaptive attention network (HAA) is proposed to learn the head-shoulder feature and an innovative ensemble method is designed to enhance the generalization of our model. Given the input person image, the ensemble method would focus on the head-shoulder feature by assigning a larger weight if the individual insides the image is in black clothing. Due to the lack of a suitable benchmark dataset for studying the Black Re-ID problem, we also contribute the first Black-reID dataset, which contains 1274 identities in training set. Extensive evaluations on the Black-reID, Market1501 and DukeMTMC-reID datasets show that our model achieves the best result compared with the state-of-the-art Re-ID methods on both Black and conventional Re-ID problems. Furthermore, our method is also proved to be effective in dealing with person Re-ID in similar clothing. Our code and dataset are avaliable on https://github.com/xbq1994/.
FastReID: A Pytorch Toolbox for General Instance Re-identification
Jun 29, 2020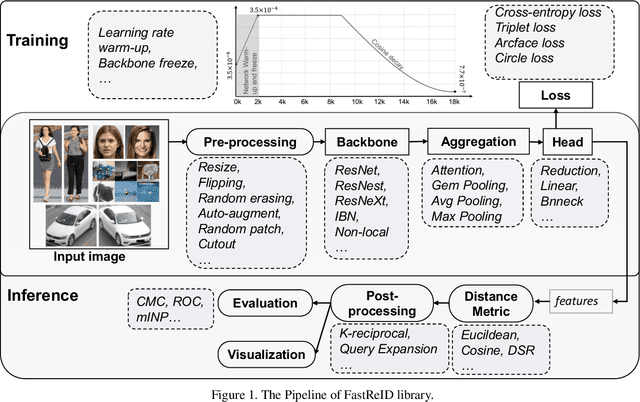
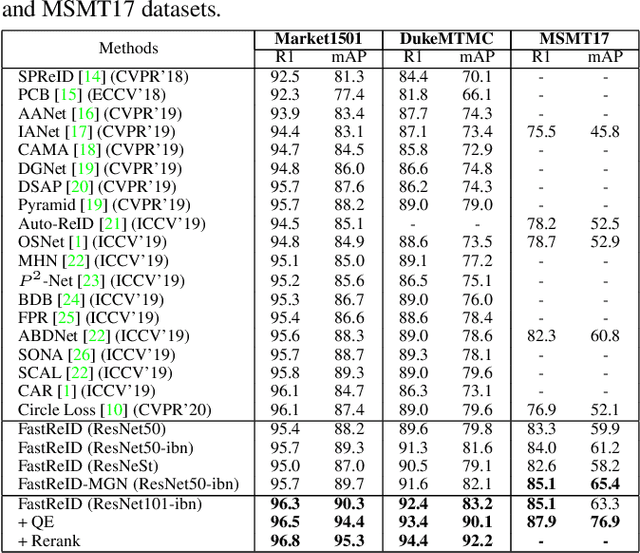

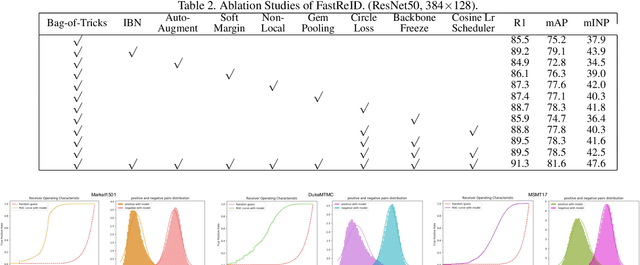
General Instance Re-identification is a very important task in the computer vision, which can be widely used in many practical applications, such as person/vehicle re-identification, face recognition, wildlife protection, commodity tracing, and snapshop, etc.. To meet the increasing application demand for general instance re-identification, we present FastReID as a widely used software system in JD AI Research. In FastReID, highly modular and extensible design makes it easy for the researcher to achieve new research ideas. Friendly manageable system configuration and engineering deployment functions allow practitioners to quickly deploy models into productions. We have implemented some state-of-the-art projects, including person re-id, partial re-id, cross-domain re-id and vehicle re-id, and plan to release these pre-trained models on multiple benchmark datasets. FastReID is by far the most general and high-performance toolbox that supports single and multiple GPU servers, you can reproduce our project results very easily and are very welcome to use it, the code and models are available at https://github.com/JDAI-CV/fast-reid.
A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification
Jun 19, 2019
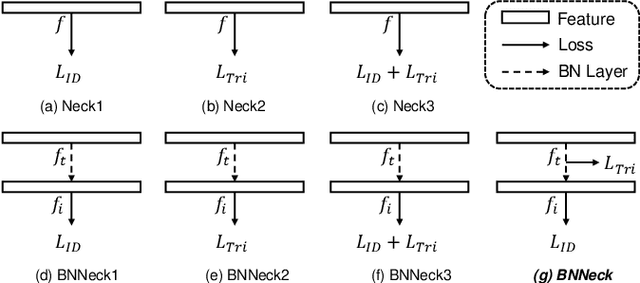

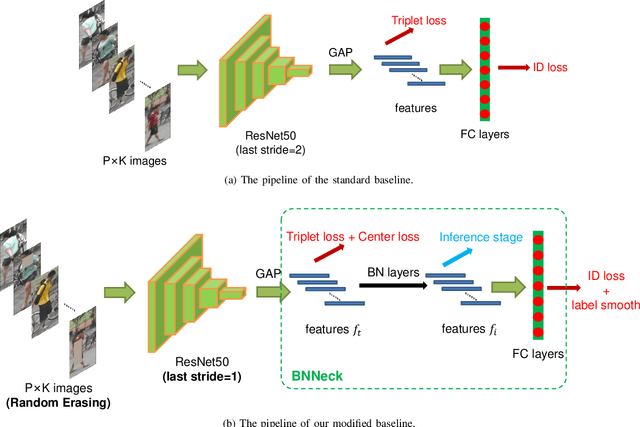
This study explores a simple but strong baseline for person re-identification (ReID). Person ReID with deep neural networks has progressed and achieved high performance in recent years. However, many state-of-the-art methods design complex network structures and concatenate multi-branch features. In the literature, some effective training tricks briefly appear in several papers or source codes. The present study collects and evaluates these effective training tricks in person ReID. By combining these tricks, the model achieves 94.5% rank-1 and 85.9% mean average precision on Market1501 with only using the global features of ResNet50. The performance surpasses all existing global- and part-based baselines in person ReID. We propose a novel neck structure named as batch normalization neck (BNNeck). BNNeck adds a batch normalization layer after global pooling layer to separate metric and classification losses into two different feature spaces because we observe they are inconsistent in one embedding space. Extended experiments show that BNNeck can boost the baseline, and our baseline can improve the performance of existing state-of-the-art methods. Our codes and models are available at: https://github.com/michuanhaohao/reid-strong-baseline.