 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-driven Open-Vocabulary Keypoint Detection for Animal Body and Face
Oct 10, 2023Current approaches for image-based keypoint detection on animal (including human) body and face are limited to specific keypoints and species. We address the limitation by proposing the Open-Vocabulary Keypoint Detection (OVKD) task. It aims to use text prompts to localize arbitrary keypoints of any species. To accomplish this objective, we propose Open-Vocabulary Keypoint Detection with Semantic-feature Matching (KDSM), which utilizes both vision and language models to harness the relationship between text and vision and thus achieve keypoint detection through associating text prompt with relevant keypoint features. Additionally, KDSM integrates domain distribution matrix matching and some special designs to reinforce the relationship between language and vision, thereby improving the model's generalizability and performance. Extensive experiments show that our proposed components bring significant performance improvements, and our overall method achieves impressive results in OVKD. Remarkably, our method outperforms the state-of-the-art few-shot keypoint detection methods using a zero-shot fashion. We will make the source code publicly accessible.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021


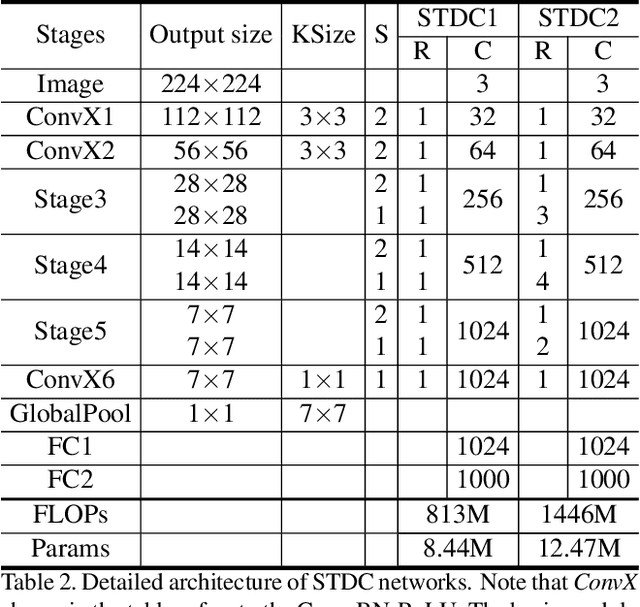
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
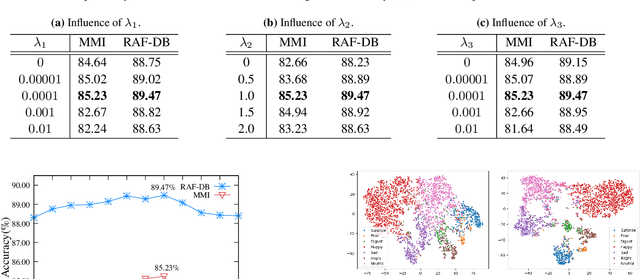
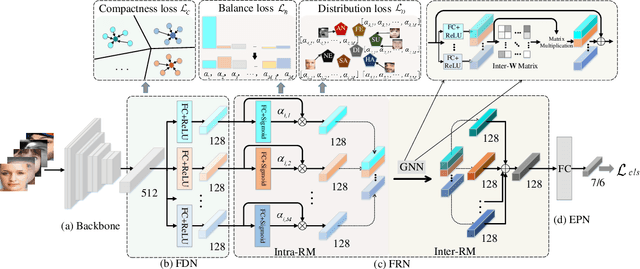
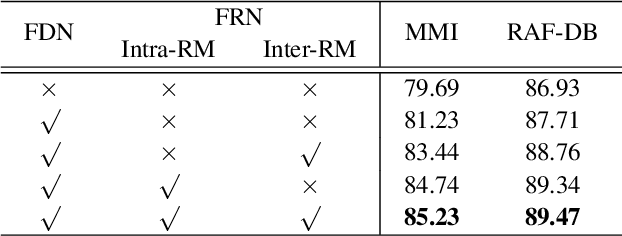
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Preparing Lessons: Improve Knowledge Distillation with Better Supervision
Nov 18, 2019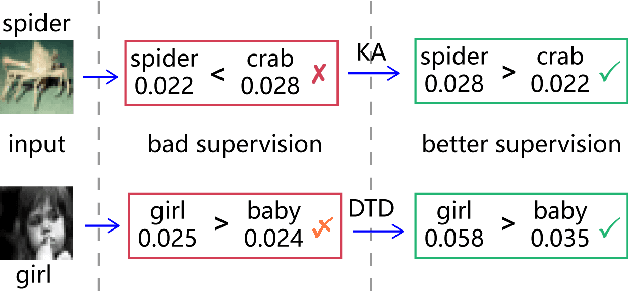


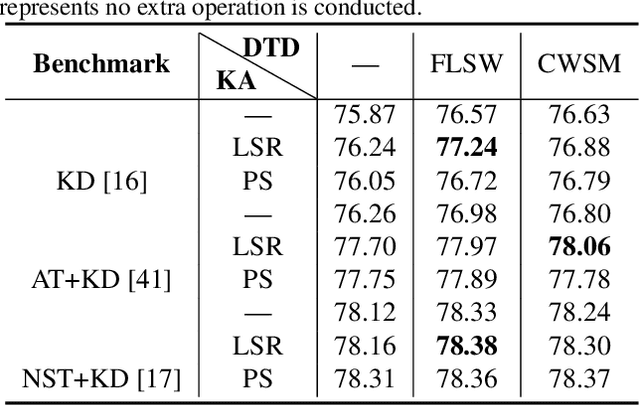
Knowledge distillation (KD) is widely used for training a compact model with the supervision of another large model, which could effectively improve the performance. Previous methods mainly focus on two aspects: 1) training the student to mimic representation space of the teacher; 2) training the model progressively or adding extra module like discriminator. Knowledge from teacher is useful, but it is still not exactly right compared with ground truth. Besides, overly uncertain supervision also influences the result. We introduce two novel approaches, Knowledge Adjustment (KA) and Dynamic Temperature Distillation (DTD), to penalize bad supervision and improve student model. Experiments on CIFAR-100, CINIC-10 and Tiny ImageNet show that our methods get encouraging performance compared with state-of-the-art methods. When combined with other KD-based methods, the performance will be further improved.
A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification
Jun 19, 2019
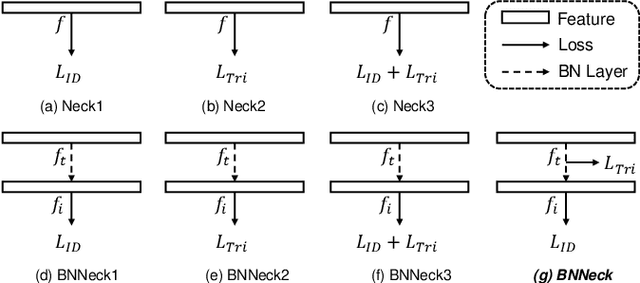

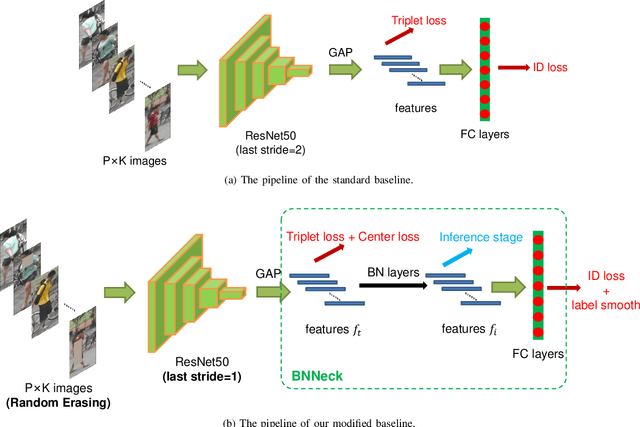
This study explores a simple but strong baseline for person re-identification (ReID). Person ReID with deep neural networks has progressed and achieved high performance in recent years. However, many state-of-the-art methods design complex network structures and concatenate multi-branch features. In the literature, some effective training tricks briefly appear in several papers or source codes. The present study collects and evaluates these effective training tricks in person ReID. By combining these tricks, the model achieves 94.5% rank-1 and 85.9% mean average precision on Market1501 with only using the global features of ResNet50. The performance surpasses all existing global- and part-based baselines in person ReID. We propose a novel neck structure named as batch normalization neck (BNNeck). BNNeck adds a batch normalization layer after global pooling layer to separate metric and classification losses into two different feature spaces because we observe they are inconsistent in one embedding space. Extended experiments show that BNNeck can boost the baseline, and our baseline can improve the performance of existing state-of-the-art methods. Our codes and models are available at: https://github.com/michuanhaohao/reid-strong-baseline.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019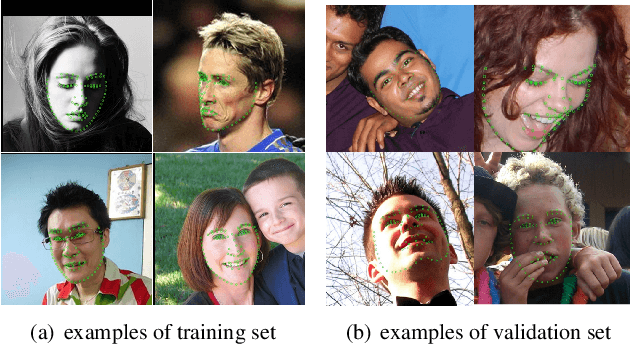
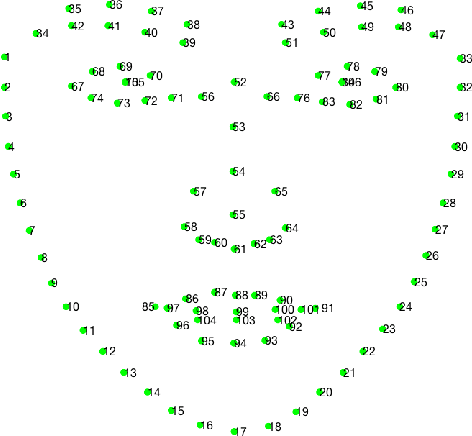

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.
Bag of Tricks and A Strong Baseline for Deep Person Re-identification
Mar 26, 2019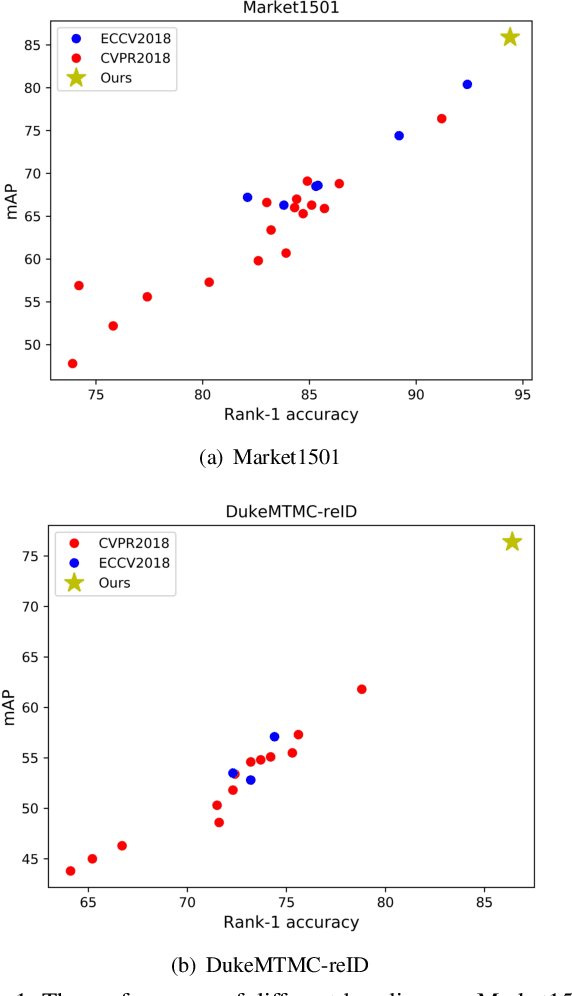
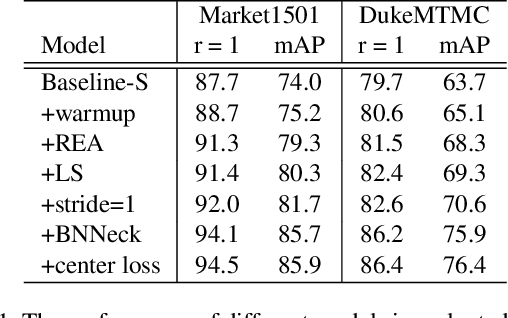
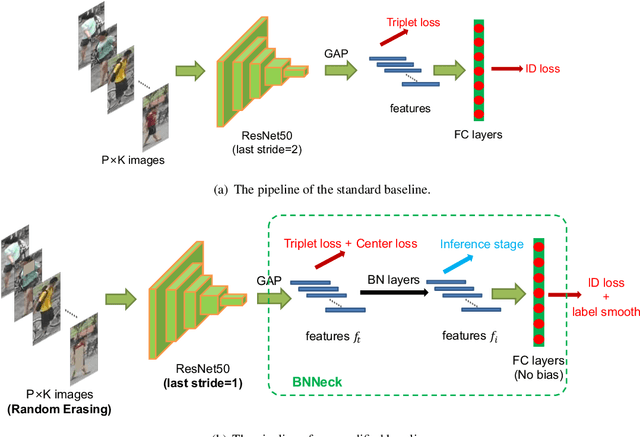
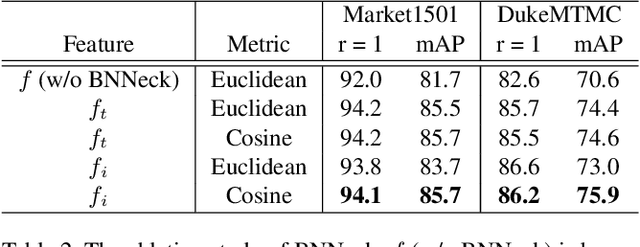
This paper explores a simple and efficient baseline for person re-identification (ReID). Person re-identification (ReID) with deep neural networks has made progress and achieved high performance in recent years. However, many state-of-the-arts methods design complex network structure and concatenate multi-branch features. In the literature, some effective training tricks are briefly appeared in several papers or source codes. This paper will collect and evaluate these effective training tricks in person ReID. By combining these tricks together, the model achieves 94.5% rank-1 and 85.9% mAP on Market1501 with only using global features. Our codes and models are available in Github.