 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multi-View BEV Object Detection with Mixed Pinhole and Fisheye Cameras
Mar 29, 2026Modern autonomous driving systems increasingly rely on mixed camera configurations with pinhole and fisheye cameras for full view perception. However, Bird's-Eye View (BEV) 3D object detection models are predominantly designed for pinhole cameras, leading to performance degradation under fisheye distortion. To bridge this gap, we introduce a multi-view BEV detection benchmark with mixed cameras by converting KITTI-360 into nuScenes format. Our study encompasses three adaptations: rectification for zero-shot evaluation and fine-tuning of nuScenes-trained models, distortion-aware view transformation modules (VTMs) via the MEI camera model, and polar coordinate representations to better align with radial distortion. We systematically evaluate three representative BEV architectures, BEVFormer, BEVDet and PETR, across these strategies. We demonstrate that projection-free architectures are inherently more robust and effective against fisheye distortion than other VTMs. This work establishes the first real-data 3D detection benchmark with fisheye and pinhole images and provides systematic adaptation and practical guidelines for designing robust and cost-effective 3D perception systems. The code is available at https://github.com/CesarLiu/FishBEVOD.git.
Provable Subspace Identification of Nonlinear Multi-view CCA
Feb 27, 2026We investigate the identifiability of nonlinear Canonical Correlation Analysis (CCA) in a multi-view setup, where each view is generated by an unknown nonlinear map applied to a linear mixture of shared latents and view-private noise. Rather than attempting exact unmixing, a problem proven to be ill-posed, we instead reframe multi-view CCA as a basis-invariant subspace identification problem. We prove that, under suitable latent priors and spectral separation conditions, multi-view CCA recovers the pairwise correlated signal subspaces up to view-wise orthogonal ambiguity. For $N \geq 3$ views, the objective provably isolates the jointly correlated subspaces shared across all views while eliminating view-private variations. We further establish finite-sample consistency guarantees by translating the concentration of empirical cross-covariances into explicit subspace error bounds via spectral perturbation theory. Experiments on synthetic and rendered image datasets validate our theoretical findings and confirm the necessity of the assumed conditions.
Ensuring Semantics in Weights of Implicit Neural Representations through the Implicit Function Theorem
Jan 30, 2026Weight Space Learning (WSL), which frames neural network weights as a data modality, is an emerging field with potential for tasks like meta-learning or transfer learning. Particularly, Implicit Neural Representations (INRs) provide a convenient testbed, where each set of weights determines the corresponding individual data sample as a mapping from coordinates to contextual values. So far, a precise theoretical explanation for the mechanism of encoding semantics of data into network weights is still missing. In this work, we deploy the Implicit Function Theorem (IFT) to establish a rigorous mapping between the data space and its latent weight representation space. We analyze a framework that maps instance-specific embeddings to INR weights via a shared hypernetwork, achieving performance competitive with existing baselines on downstream classification tasks across 2D and 3D datasets. These findings offer a theoretical lens for future investigations into network weights.
ScholarGym: Benchmarking Deep Research Workflows on Academic Literature Retrieval
Jan 29, 2026Tool-augmented large language models have advanced from single-turn question answering to deep research workflows that iteratively plan queries, invoke external tools, and synthesize information to address complex information needs. Evaluating such workflows presents a fundamental challenge: reliance on live APIs introduces non-determinism, as tool invocations may yield different results across runs due to temporal drift, rate limiting, and evolving backend states. This variance undermines reproducibility and invalidates cross-system comparisons. We present ScholarGym, a simulation environment for reproducible evaluation of deep research workflows on academic literature. The environment decouples workflow components into query planning, tool invocation, and relevance assessment, enabling fine-grained analysis of each stage under controlled conditions. Built on a static corpus of 570K papers with deterministic retrieval, ScholarGym provides 2,536 queries with expert-annotated ground truth. Experiments across diverse backbone models reveal how reasoning capabilities, planning strategies, and selection mechanisms interact over iterative refinement.
Cross-Level Sensor Fusion with Object Lists via Transformer for 3D Object Detection
Dec 14, 2025In automotive sensor fusion systems, smart sensors and Vehicle-to-Everything (V2X) modules are commonly utilized. Sensor data from these systems are typically available only as processed object lists rather than raw sensor data from traditional sensors. Instead of processing other raw data separately and then fusing them at the object level, we propose an end-to-end cross-level fusion concept with Transformer, which integrates highly abstract object list information with raw camera images for 3D object detection. Object lists are fed into a Transformer as denoising queries and propagated together with learnable queries through the latter feature aggregation process. Additionally, a deformable Gaussian mask, derived from the positional and size dimensional priors from the object lists, is explicitly integrated into the Transformer decoder. This directs attention toward the target area of interest and accelerates model training convergence. Furthermore, as there is no public dataset containing object lists as a standalone modality, we propose an approach to generate pseudo object lists from ground-truth bounding boxes by simulating state noise and false positives and negatives. As the first work to conduct cross-level fusion, our approach shows substantial performance improvements over the vision-based baseline on the nuScenes dataset. It demonstrates its generalization capability over diverse noise levels of simulated object lists and real detectors.
* 6 pages, 3 figures, accepted at IV2025
Provable Affine Identifiability of Nonlinear CCA under Latent Distributional Priors
Oct 06, 2025In this work, we establish conditions under which nonlinear CCA recovers the ground-truth latent factors up to an orthogonal transform after whitening. Building on the classical result that linear mappings maximize canonical correlations under Gaussian priors, we prove affine identifiability for a broad class of latent distributions in the population setting. Central to our proof is a reparameterization result that transports the analysis from observation space to source space, where identifiability becomes tractable. We further show that whitening is essential for ensuring boundedness and well-conditioning, thereby underpinning identifiability. Beyond the population setting, we prove that ridge-regularized empirical CCA converges to its population counterpart, transferring these guarantees to the finite-sample regime. Experiments on a controlled synthetic dataset and a rendered image dataset validate our theory and demonstrate the necessity of its assumptions through systematic ablations.
Mechanistic Independence: A Principle for Identifiable Disentangled Representations
Sep 26, 2025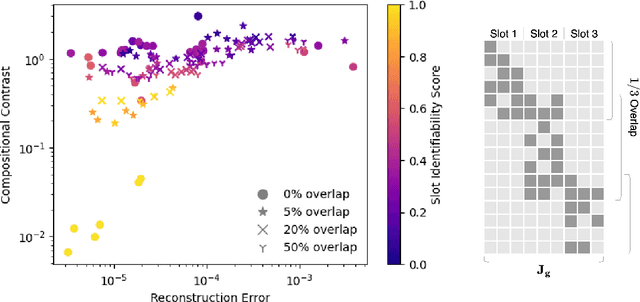
Disentangled representations seek to recover latent factors of variation underlying observed data, yet their identifiability is still not fully understood. We introduce a unified framework in which disentanglement is achieved through mechanistic independence, which characterizes latent factors by how they act on observed variables rather than by their latent distribution. This perspective is invariant to changes of the latent density, even when such changes induce statistical dependencies among factors. Within this framework, we propose several related independence criteria -- ranging from support-based and sparsity-based to higher-order conditions -- and show that each yields identifiability of latent subspaces, even under nonlinear, non-invertible mixing. We further establish a hierarchy among these criteria and provide a graph-theoretic characterization of latent subspaces as connected components. Together, these results clarify the conditions under which disentangled representations can be identified without relying on statistical assumptions.
Resource-Efficient Adaptation of Large Language Models for Text Embeddings via Prompt Engineering and Contrastive Fine-tuning
Jul 30, 2025



Large Language Models (LLMs) have become a cornerstone in Natural Language Processing (NLP), achieving impressive performance in text generation. Their token-level representations capture rich, human-aligned semantics. However, pooling these vectors into a text embedding discards crucial information. Nevertheless, many non-generative downstream tasks, such as clustering, classification, or retrieval, still depend on accurate and controllable sentence- or document-level embeddings. We explore several adaptation strategies for pre-trained, decoder-only LLMs: (i) various aggregation techniques for token embeddings, (ii) task-specific prompt engineering, and (iii) text-level augmentation via contrastive fine-tuning. Combining these components yields state-of-the-art performance on the English clustering track of the Massive Text Embedding Benchmark (MTEB). An analysis of the attention map further shows that fine-tuning shifts focus from prompt tokens to semantically relevant words, indicating more effective compression of meaning into the final hidden state. Our experiments demonstrate that LLMs can be effectively adapted as text embedding models through a combination of prompt engineering and resource-efficient contrastive fine-tuning on synthetically generated positive pairs.
AgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need
Jun 18, 2025Large language model based multi-agent systems have demonstrated significant potential in social simulation and complex task resolution domains. However, current frameworks face critical challenges in system architecture design, cross-domain generalizability, and performance guarantees, particularly as task complexity and number of agents increases. We introduces AgentGroupChat-V2, a novel framework addressing these challenges through three core innovations: (1) a divide-and-conquer fully parallel architecture that decomposes user queries into hierarchical task forest structures enabling dependency management and distributed concurrent processing. (2) an adaptive collaboration engine that dynamically selects heterogeneous LLM combinations and interaction modes based on task characteristics. (3) agent organization optimization strategies combining divide-and-conquer approaches for efficient problem decomposition. Extensive experiments demonstrate AgentGroupChat-V2's superior performance across diverse domains, achieving 91.50% accuracy on GSM8K (exceeding the best baseline by 5.6 percentage points), 30.4% accuracy on competition-level AIME (nearly doubling other methods), and 79.20% pass@1 on HumanEval. Performance advantages become increasingly pronounced with higher task difficulty, particularly on Level 5 MATH problems where improvements exceed 11 percentage points compared to state-of-the-art baselines. These results confirm that AgentGroupChat-V2 provides a comprehensive solution for building efficient, general-purpose LLM multi-agent systems with significant advantages in complex reasoning scenarios. Code is available at https://github.com/MikeGu721/AgentGroupChat-V2.
Application and Optimization of Large Models Based on Prompt Tuning for Fact-Check-Worthiness Estimation
Apr 25, 2025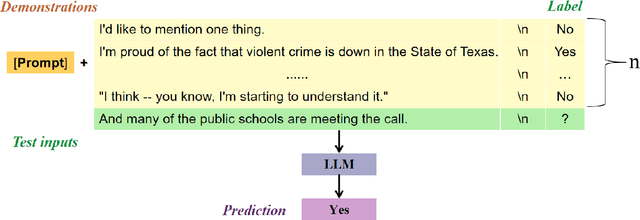
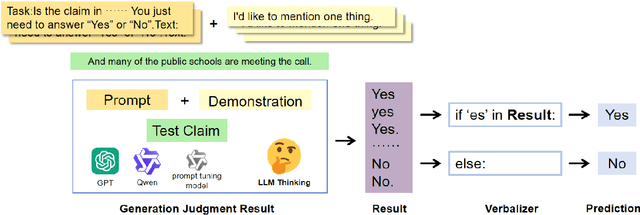
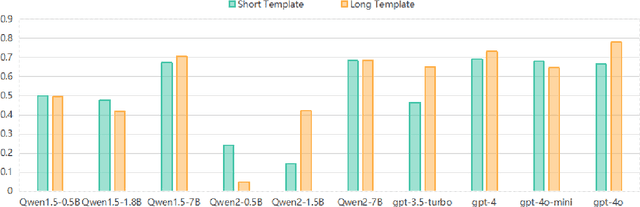
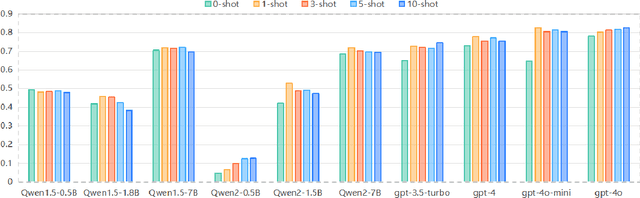
In response to the growing problem of misinformation in the context of globalization and informatization, this paper proposes a classification method for fact-check-worthiness estimation based on prompt tuning. We construct a model for fact-check-worthiness estimation at the methodological level using prompt tuning. By applying designed prompt templates to large language models, we establish in-context learning and leverage prompt tuning technology to improve the accuracy of determining whether claims have fact-check-worthiness, particularly when dealing with limited or unlabeled data. Through extensive experiments on public datasets, we demonstrate that the proposed method surpasses or matches multiple baseline methods in the classification task of fact-check-worthiness estimation assessment, including classical pre-trained models such as BERT, as well as recent popular large models like GPT-3.5 and GPT-4. Experiments show that the prompt tuning-based method proposed in this study exhibits certain advantages in evaluation metrics such as F1 score and accuracy, thereby effectively validating its effectiveness and advancement in the task of fact-check-worthiness estimation.