 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need
Jun 18, 2025Large language model based multi-agent systems have demonstrated significant potential in social simulation and complex task resolution domains. However, current frameworks face critical challenges in system architecture design, cross-domain generalizability, and performance guarantees, particularly as task complexity and number of agents increases. We introduces AgentGroupChat-V2, a novel framework addressing these challenges through three core innovations: (1) a divide-and-conquer fully parallel architecture that decomposes user queries into hierarchical task forest structures enabling dependency management and distributed concurrent processing. (2) an adaptive collaboration engine that dynamically selects heterogeneous LLM combinations and interaction modes based on task characteristics. (3) agent organization optimization strategies combining divide-and-conquer approaches for efficient problem decomposition. Extensive experiments demonstrate AgentGroupChat-V2's superior performance across diverse domains, achieving 91.50% accuracy on GSM8K (exceeding the best baseline by 5.6 percentage points), 30.4% accuracy on competition-level AIME (nearly doubling other methods), and 79.20% pass@1 on HumanEval. Performance advantages become increasingly pronounced with higher task difficulty, particularly on Level 5 MATH problems where improvements exceed 11 percentage points compared to state-of-the-art baselines. These results confirm that AgentGroupChat-V2 provides a comprehensive solution for building efficient, general-purpose LLM multi-agent systems with significant advantages in complex reasoning scenarios. Code is available at https://github.com/MikeGu721/AgentGroupChat-V2.
ToReMi: Topic-Aware Data Reweighting for Dynamic Pre-Training Data Selection
Apr 01, 2025

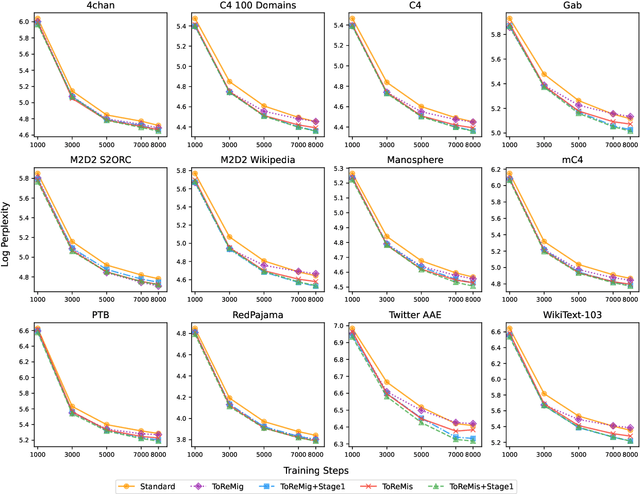

Pre-training large language models (LLMs) necessitates enormous diverse textual corpora, making effective data selection a key challenge for balancing computational resources and model performance. Current methodologies primarily emphasize data quality metrics and mixing proportions, yet they fail to adequately capture the underlying semantic connections between training samples and quality disparities within individual domains. We introduce ToReMi (Topic-based Reweighting for Model improvement), a novel two-stage framework that dynamically adjusts training sample weights according to their topical associations and observed learning patterns. Our comprehensive experiments reveal that ToReMi variants consistently achieve superior performance over conventional pre-training approaches, demonstrating accelerated perplexity reduction across multiple domains and enhanced capabilities on downstream evaluation tasks. Code is available at https://github.com/zxx000728/ToReMi.
DetectBench: Can Large Language Model Detect and Piece Together Implicit Evidence?
Jun 18, 2024



Detecting evidence within the context is a key step in the process of reasoning task. Evaluating and enhancing the capabilities of LLMs in evidence detection will strengthen context-based reasoning performance. This paper proposes a benchmark called DetectBench for verifying the ability to detect and piece together implicit evidence within a long context. DetectBench contains 3,928 multiple-choice questions, with an average of 994 tokens per question. Each question contains an average of 4.55 pieces of implicit evidence, and solving the problem typically requires 7.62 logical jumps to find the correct answer. To enhance the performance of LLMs in evidence detection, this paper proposes Detective Reasoning Prompt and Finetune. Experiments demonstrate that the existing LLMs' abilities to detect evidence in long contexts are far inferior to humans. However, the Detective Reasoning Prompt effectively enhances the capability of powerful LLMs in evidence detection, while the Finetuning method shows significant effects in enhancing the performance of weaker LLMs. Moreover, when the abilities of LLMs in evidence detection are improved, their final reasoning performance is also enhanced accordingly.
Agent Group Chat: An Interactive Group Chat Simulacra For Better Eliciting Collective Emergent Behavior
Mar 20, 2024To investigate the role of language in human collective behaviors, we developed the Agent Group Chat simulation to simulate linguistic interactions among multi-agent in different settings. Agents are asked to free chat in this simulation for their own purposes based on their character setting, aiming to see agents exhibit emergent behaviours that are both unforeseen and significant. Four narrative scenarios, Inheritance Disputes, Law Court Debates, Philosophical Discourses, Movie Casting Contention, are integrated into Agent Group Chat to evaluate its support for diverse storylines. By configuring specific environmental settings within Agent Group Chat, we are able to assess whether agents exhibit behaviors that align with human expectations. We evaluate the disorder within the environment by computing the n-gram Shannon entropy of all the content speak by characters. Our findings reveal that under the premise of agents possessing substantial alignment with human expectations, facilitating more extensive information exchange within the simulation ensures greater orderliness amidst diversity, which leads to the emergence of more unexpected and meaningful emergent behaviors. The code is open source in https://github.com/MikeGu721/AgentGroup, and online platform will be open soon.
Beyond the Obvious: Evaluating the Reasoning Ability In Real-life Scenarios of Language Models on Life Scapes Reasoning Benchmark~(LSR-Benchmark)
Jul 11, 2023



This paper introduces the Life Scapes Reasoning Benchmark (LSR-Benchmark), a novel dataset targeting real-life scenario reasoning, aiming to close the gap in artificial neural networks' ability to reason in everyday contexts. In contrast to domain knowledge reasoning datasets, LSR-Benchmark comprises free-text formatted questions with rich information on real-life scenarios, human behaviors, and character roles. The dataset consists of 2,162 questions collected from open-source online sources and is manually annotated to improve its quality. Experiments are conducted using state-of-the-art language models, such as gpt3.5-turbo and instruction fine-tuned llama models, to test the performance in LSR-Benchmark. The results reveal that humans outperform these models significantly, indicating a persisting challenge for machine learning models in comprehending daily human life.
Xiezhi: An Ever-Updating Benchmark for Holistic Domain Knowledge Evaluation
Jun 15, 2023



New Natural Langauge Process~(NLP) benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present Xiezhi, the most comprehensive evaluation suite designed to assess holistic domain knowledge. Xiezhi comprises multiple-choice questions across 516 diverse disciplines ranging from 13 different subjects with 249,587 questions and accompanied by Xiezhi-Specialty and Xiezhi-Interdiscipline, both with 15k questions. We conduct evaluation of the 47 cutting-edge LLMs on Xiezhi. Results indicate that LLMs exceed average performance of humans in science, engineering, agronomy, medicine, and art, but fall short in economics, jurisprudence, pedagogy, literature, history, and management. We anticipate Xiezhi will help analyze important strengths and shortcomings of LLMs, and the benchmark is released in~\url{https://github.com/MikeGu721/XiezhiBenchmark}.
Domain Mastery Benchmark: An Ever-Updating Benchmark for Evaluating Holistic Domain Knowledge of Large Language Model--A Preliminary Release
Apr 23, 2023
Domain knowledge refers to the in-depth understanding, expertise, and familiarity with a specific subject, industry, field, or area of special interest. The existing benchmarks are all lack of an overall design for domain knowledge evaluation. Holding the belief that the real ability of domain language understanding can only be fairly evaluated by an comprehensive and in-depth benchmark, we introduces the Domma, a Domain Mastery Benchmark. DomMa targets at testing Large Language Models (LLMs) on their domain knowledge understanding, it features extensive domain coverage, large data volume, and a continually updated data set based on Chinese 112 first-level subject classifications. DomMa consist of 100,000 questions in both Chinese and English sourced from graduate entrance examinations and undergraduate exams in Chinese college. We have also propose designs to make benchmark and evaluation process more suitable to LLMs.