 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-Eval: A Benchmark for Evaluating Self-Evolving Agents Beyond Episodic Assessment
Apr 14, 2026Current LLM-based agents demonstrate strong performance in episodic task execution but remain constrained by static toolsets and episodic amnesia, failing to accumulate experience across task boundaries. This paper presents the first formal definition of the Self-Evolving Agent (SEA), formalizes the Evolutionary Flywheel as its minimal sufficient architecture, and introduces SEA-Eval -- the first benchmark designed specifically for evaluating SEAs. Grounded in Flywheel theory, SEA-Eval establishes $SR$ and $T$ as primary metrics and enables through sequential task stream design the independent quantification of evolutionary gain, evolutionary stability, and implicit alignment convergence. Empirical evaluation reveals that under identical success rates, token consumption differs by up to 31.2$\times$ across frameworks, with divergent evolutionary trajectories under sequential analysis -- demonstrating that success rate alone creates a capability illusion and that the sequential convergence of $T$ is the key criterion for distinguishing genuine evolution from pseudo-evolution.
ComLQ: Benchmarking Complex Logical Queries in Information Retrieval
Nov 15, 2025

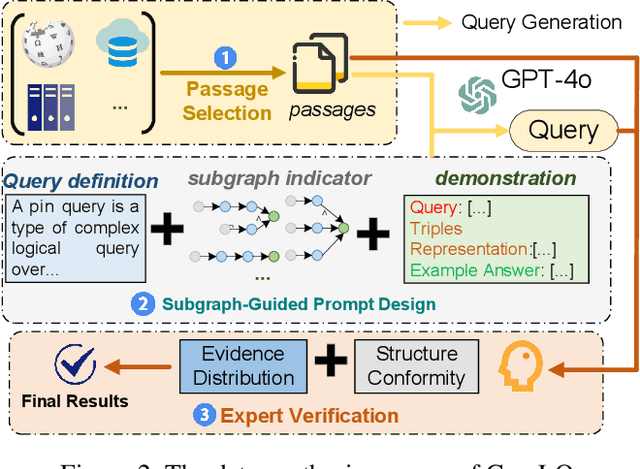

Information retrieval (IR) systems play a critical role in navigating information overload across various applications. Existing IR benchmarks primarily focus on simple queries that are semantically analogous to single- and multi-hop relations, overlooking \emph{complex logical queries} involving first-order logic operations such as conjunction ($\land$), disjunction ($\lor$), and negation ($\lnot$). Thus, these benchmarks can not be used to sufficiently evaluate the performance of IR models on complex queries in real-world scenarios. To address this problem, we propose a novel method leveraging large language models (LLMs) to construct a new IR dataset \textbf{ComLQ} for \textbf{Com}plex \textbf{L}ogical \textbf{Q}ueries, which comprises 2,909 queries and 11,251 candidate passages. A key challenge in constructing the dataset lies in capturing the underlying logical structures within unstructured text. Therefore, by designing the subgraph-guided prompt with the subgraph indicator, an LLM (such as GPT-4o) is guided to generate queries with specific logical structures based on selected passages. All query-passage pairs in ComLQ are ensured \emph{structure conformity} and \emph{evidence distribution} through expert annotation. To better evaluate whether retrievers can handle queries with negation, we further propose a new evaluation metric, \textbf{Log-Scaled Negation Consistency} (\textbf{LSNC@$K$}). As a supplement to standard relevance-based metrics (such as nDCG and mAP), LSNC@$K$ measures whether top-$K$ retrieved passages violate negation conditions in queries. Our experimental results under zero-shot settings demonstrate existing retrieval models' limited performance on complex logical queries, especially on queries with negation, exposing their inferior capabilities of modeling exclusion.
Why Did Apple Fall To The Ground: Evaluating Curiosity In Large Language Model
Oct 23, 2025Curiosity serves as a pivotal conduit for human beings to discover and learn new knowledge. Recent advancements of large language models (LLMs) in natural language processing have sparked discussions regarding whether these models possess capability of curiosity-driven learning akin to humans. In this paper, starting from the human curiosity assessment questionnaire Five-Dimensional Curiosity scale Revised (5DCR), we design a comprehensive evaluation framework that covers dimensions such as Information Seeking, Thrill Seeking, and Social Curiosity to assess the extent of curiosity exhibited by LLMs. The results demonstrate that LLMs exhibit a stronger thirst for knowledge than humans but still tend to make conservative choices when faced with uncertain environments. We further investigated the relationship between curiosity and thinking of LLMs, confirming that curious behaviors can enhance the model's reasoning and active learning abilities. These findings suggest that LLMs have the potential to exhibit curiosity similar to that of humans, providing experimental support for the future development of learning capabilities and innovative research in LLMs.
HINT: Helping Ineffective Rollouts Navigate Towards Effectiveness
Oct 10, 2025Reinforcement Learning (RL) has become a key driver for enhancing the long chain-of-thought (CoT) reasoning capabilities of Large Language Models (LLMs). However, prevalent methods like GRPO often fail when task difficulty exceeds the model's capacity, leading to reward sparsity and inefficient training. While prior work attempts to mitigate this using off-policy data, such as mixing RL with Supervised Fine-Tuning (SFT) or using hints, they often misguide policy updates In this work, we identify a core issue underlying these failures, which we term low training affinity. This condition arises from a large distributional mismatch between external guidance and the model's policy. To diagnose this, we introduce Affinity, the first quantitative metric for monitoring exploration efficiency and training stability. To improve Affinity, we propose HINT: Helping Ineffective rollouts Navigate Towards effectiveness, an adaptive hinting framework. Instead of providing direct answers, HINT supplies heuristic hints that guide the model to discover solutions on its own, preserving its autonomous reasoning capabilities. Extensive experiments on mathematical reasoning tasks show that HINT consistently outperforms existing methods, achieving state-of-the-art results with models of various scales, while also demonstrating significantly more stable learning and greater data efficiency.Code is available on Github.
CultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs
Sep 19, 2025As large language models (LLMs) are increasingly deployed in diverse cultural environments, evaluating their cultural understanding capability has become essential for ensuring trustworthy and culturally aligned applications. However, most existing benchmarks lack comprehensiveness and are challenging to scale and adapt across different cultural contexts, because their frameworks often lack guidance from well-established cultural theories and tend to rely on expert-driven manual annotations. To address these issues, we propose CultureScope, the most comprehensive evaluation framework to date for assessing cultural understanding in LLMs. Inspired by the cultural iceberg theory, we design a novel dimensional schema for cultural knowledge classification, comprising 3 layers and 140 dimensions, which guides the automated construction of culture-specific knowledge bases and corresponding evaluation datasets for any given languages and cultures. Experimental results demonstrate that our method can effectively evaluate cultural understanding. They also reveal that existing large language models lack comprehensive cultural competence, and merely incorporating multilingual data does not necessarily enhance cultural understanding. All code and data files are available at https://github.com/HoganZinger/Culture
AdaptiveLog: An Adaptive Log Analysis Framework with the Collaboration of Large and Small Language Model
Jan 19, 2025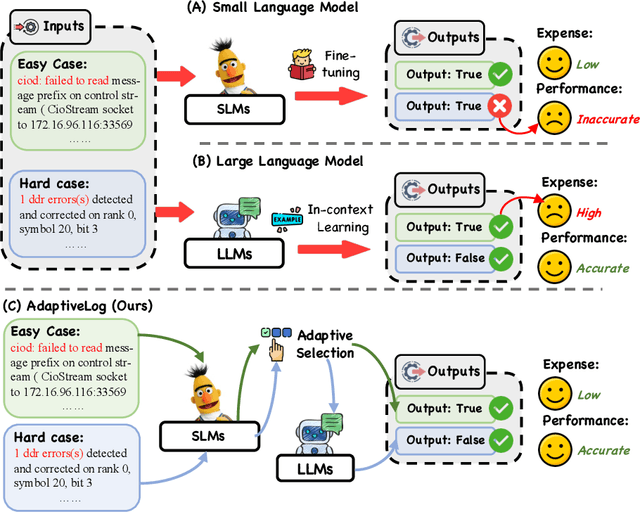

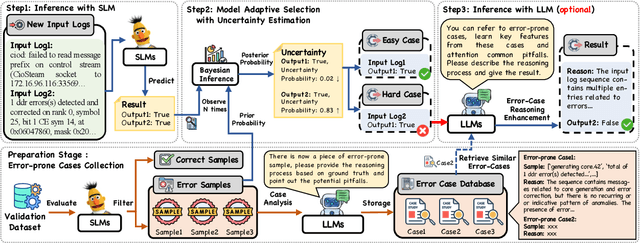

Automated log analysis is crucial to ensure high availability and reliability of complex systems. The advent of LLMs in NLP has ushered in a new era of language model-driven automated log analysis, garnering significant interest. Within this field, two primary paradigms based on language models for log analysis have become prominent. Small Language Models (SLMs) follow the pre-train and fine-tune paradigm, focusing on the specific log analysis task through fine-tuning on supervised datasets. On the other hand, LLMs following the in-context learning paradigm, analyze logs by providing a few examples in prompt contexts without updating parameters. Despite their respective strengths, we notice that SLMs are more cost-effective but less powerful, whereas LLMs with large parameters are highly powerful but expensive and inefficient. To trade-off between the performance and inference costs of both models in automated log analysis, this paper introduces an adaptive log analysis framework known as AdaptiveLog, which effectively reduces the costs associated with LLM while ensuring superior results. This framework collaborates an LLM and a small language model, strategically allocating the LLM to tackle complex logs while delegating simpler logs to the SLM. Specifically, to efficiently query the LLM, we propose an adaptive selection strategy based on the uncertainty estimation of the SLM, where the LLM is invoked only when the SLM is uncertain. In addition, to enhance the reasoning ability of the LLM in log analysis tasks, we propose a novel prompt strategy by retrieving similar error-prone cases as the reference, enabling the model to leverage past error experiences and learn solutions from these cases. Extensive experiments demonstrate that AdaptiveLog achieves state-of-the-art results across different tasks, elevating the overall accuracy of log analysis while maintaining cost efficiency.
EDGE: Enhanced Grounded GUI Understanding with Enriched Multi-Granularity Synthetic Data
Oct 25, 2024Autonomous agents operating on the graphical user interfaces (GUIs) of various applications hold immense practical value. Unlike the large language model (LLM)-based methods which rely on structured texts and customized backends, the approaches using large vision-language models (LVLMs) are more intuitive and adaptable as they can visually perceive and directly interact with screens, making them indispensable in general scenarios without text metadata and tailored backends. Given the lack of high-quality training data for GUI-related tasks in existing work, this paper aims to enhance the GUI understanding and interacting capabilities of LVLMs through a data-driven approach. We propose EDGE, a general data synthesis framework that automatically generates large-scale, multi-granularity training data from webpages across the Web. Evaluation results on various GUI and agent benchmarks demonstrate that the model trained with the dataset generated through EDGE exhibits superior webpage understanding capabilities, which can then be easily transferred to previously unseen desktop and mobile environments. Our approach significantly reduces the dependence on manual annotations, empowering researchers to harness the vast public resources available on the Web to advance their work. Our source code, the dataset and the model are available at https://anonymous.4open.science/r/EDGE-1CDB.
LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models
Sep 03, 2024
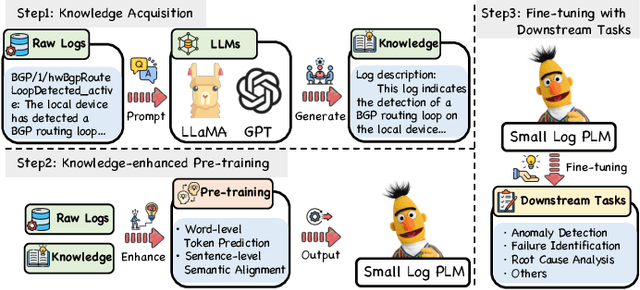
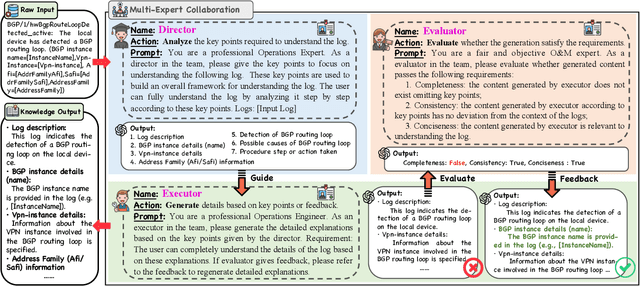
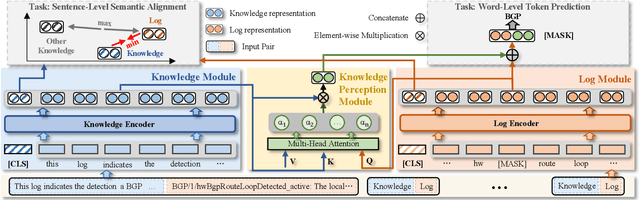
Logs play a critical role in providing essential information for system monitoring and troubleshooting. Recently, with the success of pre-trained language models (PLMs) and large language models (LLMs) in natural language processing (NLP), smaller PLMs (such as BERT) and LLMs (like ChatGPT) have become the current mainstream approaches for log analysis. While LLMs possess rich knowledge, their high computational costs and unstable performance make LLMs impractical for analyzing logs directly. In contrast, smaller PLMs can be fine-tuned for specific tasks even with limited computational resources, making them more practical. However, these smaller PLMs face challenges in understanding logs comprehensively due to their limited expert knowledge. To better utilize the knowledge embedded within LLMs for log understanding, this paper introduces a novel knowledge enhancement framework, called LUK, which acquires expert knowledge from LLMs to empower log understanding on a smaller PLM. Specifically, we design a multi-expert collaboration framework based on LLMs consisting of different roles to acquire expert knowledge. In addition, we propose two novel pre-training tasks to enhance the log pre-training with expert knowledge. LUK achieves state-of-the-art results on different log analysis tasks and extensive experiments demonstrate expert knowledge from LLMs can be utilized more effectively to understand logs.
Enhancing Quantitative Reasoning Skills of Large Language Models through Dimension Perception
Dec 29, 2023Quantities are distinct and critical components of texts that characterize the magnitude properties of entities, providing a precise perspective for the understanding of natural language, especially for reasoning tasks. In recent years, there has been a flurry of research on reasoning tasks based on large language models (LLMs), most of which solely focus on numerical values, neglecting the dimensional concept of quantities with units despite its importance. We argue that the concept of dimension is essential for precisely understanding quantities and of great significance for LLMs to perform quantitative reasoning. However, the lack of dimension knowledge and quantity-related benchmarks has resulted in low performance of LLMs. Hence, we present a framework to enhance the quantitative reasoning ability of language models based on dimension perception. We first construct a dimensional unit knowledge base (DimUnitKB) to address the knowledge gap in this area. We propose a benchmark DimEval consisting of seven tasks of three categories to probe and enhance the dimension perception skills of LLMs. To evaluate the effectiveness of our methods, we propose a quantitative reasoning task and conduct experiments. The experimental results show that our dimension perception method dramatically improves accuracy (43.55%->50.67%) on quantitative reasoning tasks compared to GPT-4.
Beyond the Obvious: Evaluating the Reasoning Ability In Real-life Scenarios of Language Models on Life Scapes Reasoning Benchmark~(LSR-Benchmark)
Jul 11, 2023



This paper introduces the Life Scapes Reasoning Benchmark (LSR-Benchmark), a novel dataset targeting real-life scenario reasoning, aiming to close the gap in artificial neural networks' ability to reason in everyday contexts. In contrast to domain knowledge reasoning datasets, LSR-Benchmark comprises free-text formatted questions with rich information on real-life scenarios, human behaviors, and character roles. The dataset consists of 2,162 questions collected from open-source online sources and is manually annotated to improve its quality. Experiments are conducted using state-of-the-art language models, such as gpt3.5-turbo and instruction fine-tuned llama models, to test the performance in LSR-Benchmark. The results reveal that humans outperform these models significantly, indicating a persisting challenge for machine learning models in comprehending daily human life.