 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
AdaptiveLog: An Adaptive Log Analysis Framework with the Collaboration of Large and Small Language Model
Jan 19, 2025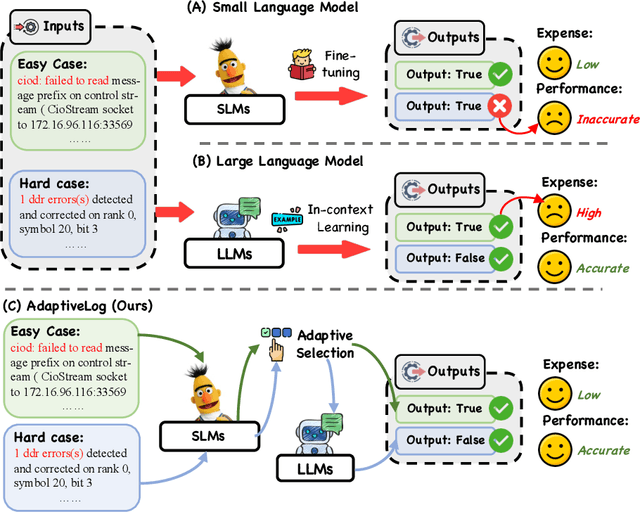

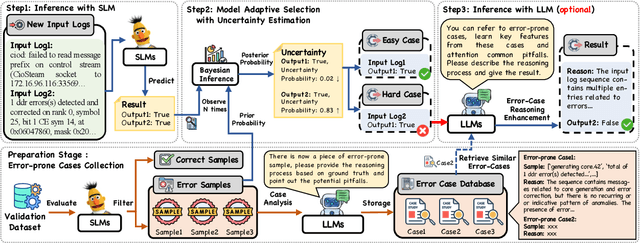

Automated log analysis is crucial to ensure high availability and reliability of complex systems. The advent of LLMs in NLP has ushered in a new era of language model-driven automated log analysis, garnering significant interest. Within this field, two primary paradigms based on language models for log analysis have become prominent. Small Language Models (SLMs) follow the pre-train and fine-tune paradigm, focusing on the specific log analysis task through fine-tuning on supervised datasets. On the other hand, LLMs following the in-context learning paradigm, analyze logs by providing a few examples in prompt contexts without updating parameters. Despite their respective strengths, we notice that SLMs are more cost-effective but less powerful, whereas LLMs with large parameters are highly powerful but expensive and inefficient. To trade-off between the performance and inference costs of both models in automated log analysis, this paper introduces an adaptive log analysis framework known as AdaptiveLog, which effectively reduces the costs associated with LLM while ensuring superior results. This framework collaborates an LLM and a small language model, strategically allocating the LLM to tackle complex logs while delegating simpler logs to the SLM. Specifically, to efficiently query the LLM, we propose an adaptive selection strategy based on the uncertainty estimation of the SLM, where the LLM is invoked only when the SLM is uncertain. In addition, to enhance the reasoning ability of the LLM in log analysis tasks, we propose a novel prompt strategy by retrieving similar error-prone cases as the reference, enabling the model to leverage past error experiences and learn solutions from these cases. Extensive experiments demonstrate that AdaptiveLog achieves state-of-the-art results across different tasks, elevating the overall accuracy of log analysis while maintaining cost efficiency.
LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models
Sep 03, 2024
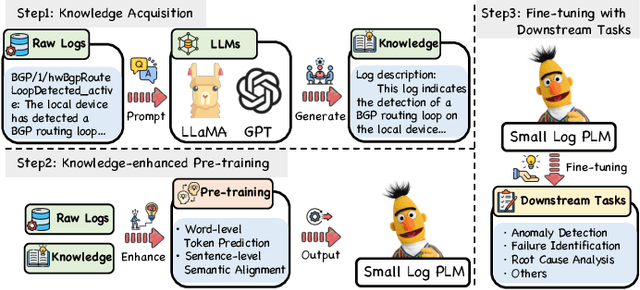
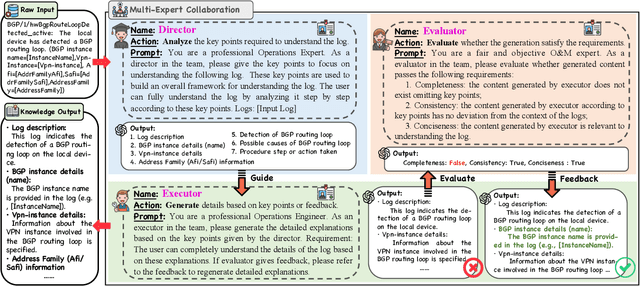
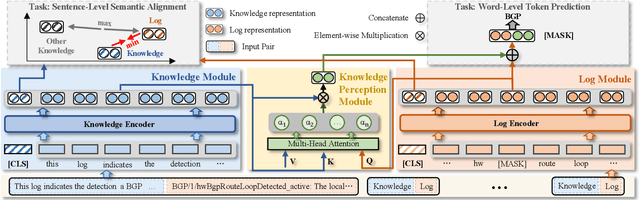
Logs play a critical role in providing essential information for system monitoring and troubleshooting. Recently, with the success of pre-trained language models (PLMs) and large language models (LLMs) in natural language processing (NLP), smaller PLMs (such as BERT) and LLMs (like ChatGPT) have become the current mainstream approaches for log analysis. While LLMs possess rich knowledge, their high computational costs and unstable performance make LLMs impractical for analyzing logs directly. In contrast, smaller PLMs can be fine-tuned for specific tasks even with limited computational resources, making them more practical. However, these smaller PLMs face challenges in understanding logs comprehensively due to their limited expert knowledge. To better utilize the knowledge embedded within LLMs for log understanding, this paper introduces a novel knowledge enhancement framework, called LUK, which acquires expert knowledge from LLMs to empower log understanding on a smaller PLM. Specifically, we design a multi-expert collaboration framework based on LLMs consisting of different roles to acquire expert knowledge. In addition, we propose two novel pre-training tasks to enhance the log pre-training with expert knowledge. LUK achieves state-of-the-art results on different log analysis tasks and extensive experiments demonstrate expert knowledge from LLMs can be utilized more effectively to understand logs.
Evaluating and Enhancing Structural Understanding Capabilities of Large Language Models on Tables via Input Designs
May 22, 2023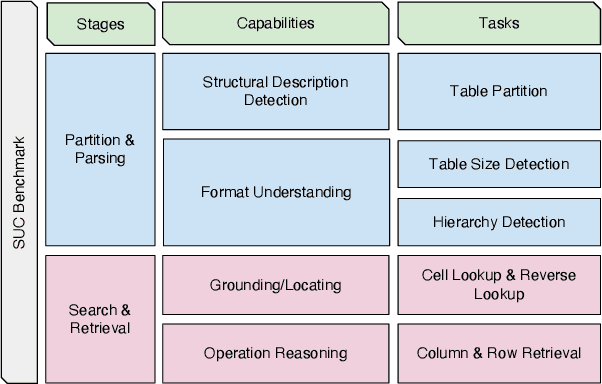
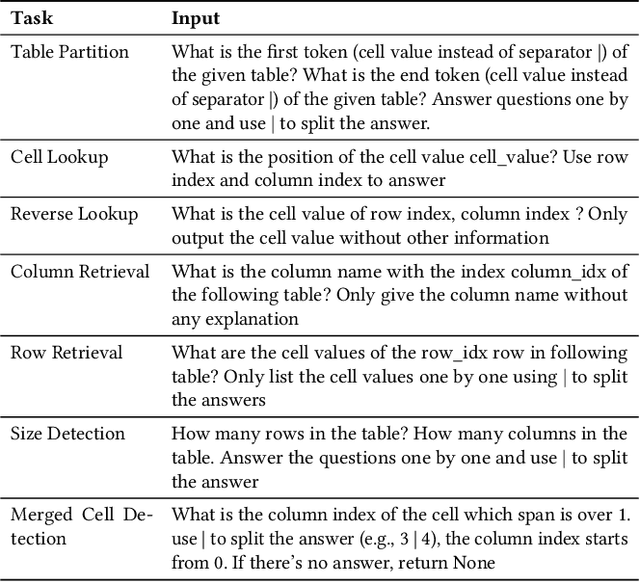
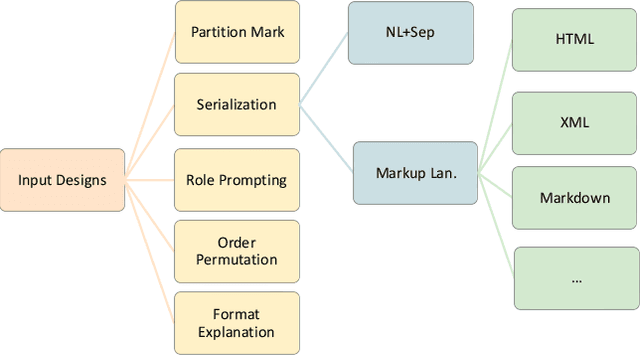

Large language models (LLMs) are becoming attractive as few-shot reasoners to solve NL-related tasks. However, there is still much to be learned about how well LLMs understand structured data, such as tables. While it is true that tables can be used as inputs to LLMs with serialization, there lack comprehensive studies examining whether LLMs can truly comprehend such data. In this paper we try to understand this by designing a benchmark to evaluate structural understanding capabilities (SUC) of LLMs. The benchmark we create includes seven tasks, each with their own unique challenges, e.g,, cell lookup, row retrieval and size detection. We run a series of evaluations on GPT-3 family models (e.g., text-davinci-003). We discover that the performance varied depending on a number of input choices, including table input format, content order, role prompting and partition marks. Drawing from the insights gained through the benchmark evaluations, we then propose self-augmentation for effective structural prompting, e.g., critical value / range identification using LLMs' internal knowledge. When combined with carefully chosen input choices, these structural prompting methods lead to promising improvements in LLM performance on a variety of tabular tasks, e.g., TabFact($\uparrow2.31\%$), HybridQA($\uparrow2.13\%$), SQA($\uparrow2.72\%$), Feverous($\uparrow0.84\%$), and ToTTo($\uparrow5.68\%$). We believe our benchmark and proposed prompting methods can serve as a simple yet generic selection for future research. The code and data are released in https://anonymous.4open.science/r/StructuredLLM-76F3.
HessianFR: An Efficient Hessian-based Follow-the-Ridge Algorithm for Minimax Optimization
May 23, 2022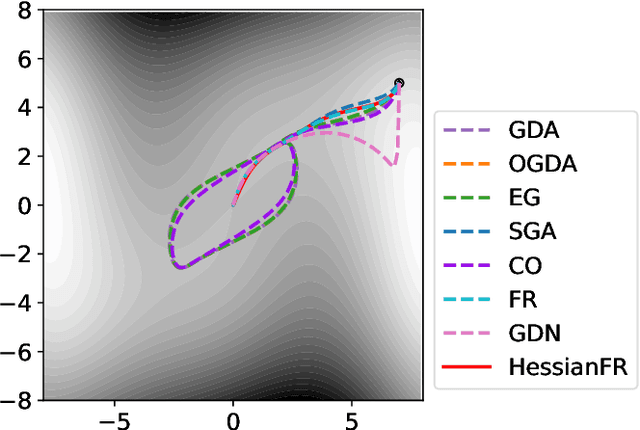


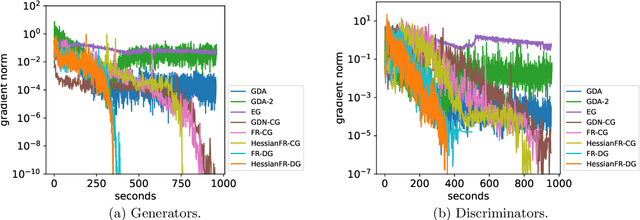
Wide applications of differentiable two-player sequential games (e.g., image generation by GANs) have raised much interest and attention of researchers to study efficient and fast algorithms. Most of the existing algorithms are developed based on nice properties of simultaneous games, i.e., convex-concave payoff functions, but are not applicable in solving sequential games with different settings. Some conventional gradient descent ascent algorithms theoretically and numerically fail to find the local Nash equilibrium of the simultaneous game or the local minimax (i.e., local Stackelberg equilibrium) of the sequential game. In this paper, we propose the HessianFR, an efficient Hessian-based Follow-the-Ridge algorithm with theoretical guarantees. Furthermore, the convergence of the stochastic algorithm and the approximation of Hessian inverse are exploited to improve algorithm efficiency. A series of experiments of training generative adversarial networks (GANs) have been conducted on both synthetic and real-world large-scale image datasets (e.g. MNIST, CIFAR-10 and CelebA). The experimental results demonstrate that the proposed HessianFR outperforms baselines in terms of convergence and image generation quality.