 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIceBench-S2S: A Benchmark of Deep Learning for Challenging Subseasonal-to-Seasonal Daily Arctic Sea Ice Forecasting in Deep Latent Space
Jan 31, 2026Arctic sea ice plays a critical role in regulating Earth's climate system, significantly influencing polar ecological stability and human activities in coastal regions. Recent advances in artificial intelligence have facilitated the development of skillful pan-Arctic sea ice forecasting systems, where data-driven approaches showcase tremendous potential to outperform conventional physics-based numerical models in terms of accuracy, computational efficiency and forecasting lead times. Despite the latest progress made by deep learning (DL) forecasting models, most of their skillful forecasting lead times are confined to daily subseasonal scale and monthly averaged values for up to six months, which drastically hinders their deployment for real-world applications, e.g., maritime routine planning for Arctic transportation and scientific investigation. Extending daily forecasts from subseasonal to seasonal (S2S) scale is scientifically crucial for operational applications. To bridge the gap between the forecasting lead time of current DL models and the significant daily S2S scale, we introduce IceBench-S2S, the first comprehensive benchmark for evaluating DL approaches in mitigating the challenge of forecasting Arctic sea ice concentration in successive 180-day periods. It proposes a generalized framework that first compresses spatial features of daily sea ice data into a deep latent space. The temporally concatenated deep features are subsequently modeled by DL-based forecasting backbones to predict the sea ice variation at S2S scale. IceBench-S2S provides a unified training and evaluation pipeline for different backbones, along with practical guidance for model selection in polar environmental monitoring tasks.
Multi-modal Multi-task Pre-training for Improved Point Cloud Understanding
Jul 23, 2025Recent advances in multi-modal pre-training methods have shown promising effectiveness in learning 3D representations by aligning multi-modal features between 3D shapes and their corresponding 2D counterparts. However, existing multi-modal pre-training frameworks primarily rely on a single pre-training task to gather multi-modal data in 3D applications. This limitation prevents the models from obtaining the abundant information provided by other relevant tasks, which can hinder their performance in downstream tasks, particularly in complex and diverse domains. In order to tackle this issue, we propose MMPT, a Multi-modal Multi-task Pre-training framework designed to enhance point cloud understanding. Specifically, three pre-training tasks are devised: (i) Token-level reconstruction (TLR) aims to recover masked point tokens, endowing the model with representative learning abilities. (ii) Point-level reconstruction (PLR) is integrated to predict the masked point positions directly, and the reconstructed point cloud can be considered as a transformed point cloud used in the subsequent task. (iii) Multi-modal contrastive learning (MCL) combines feature correspondences within and across modalities, thus assembling a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised manner. Moreover, this framework operates without requiring any 3D annotations, making it scalable for use with large datasets. The trained encoder can be effectively transferred to various downstream tasks. To demonstrate its effectiveness, we evaluated its performance compared to state-of-the-art methods in various discriminant and generative applications under widely-used benchmarks.
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Jul 08, 2025Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
Gaussian2Scene: 3D Scene Representation Learning via Self-supervised Learning with 3D Gaussian Splatting
Jun 11, 2025



Self-supervised learning (SSL) for point cloud pre-training has become a cornerstone for many 3D vision tasks, enabling effective learning from large-scale unannotated data. At the scene level, existing SSL methods often incorporate volume rendering into the pre-training framework, using RGB-D images as reconstruction signals to facilitate cross-modal learning. This strategy promotes alignment between 2D and 3D modalities and enables the model to benefit from rich visual cues in the RGB-D inputs. However, these approaches are limited by their reliance on implicit scene representations and high memory demands. Furthermore, since their reconstruction objectives are applied only in 2D space, they often fail to capture underlying 3D geometric structures. To address these challenges, we propose Gaussian2Scene, a novel scene-level SSL framework that leverages the efficiency and explicit nature of 3D Gaussian Splatting (3DGS) for pre-training. The use of 3DGS not only alleviates the computational burden associated with volume rendering but also supports direct 3D scene reconstruction, thereby enhancing the geometric understanding of the backbone network. Our approach follows a progressive two-stage training strategy. In the first stage, a dual-branch masked autoencoder learns both 2D and 3D scene representations. In the second stage, we initialize training with reconstructed point clouds and further supervise learning using the geometric locations of Gaussian primitives and rendered RGB images. This process reinforces both geometric and cross-modal learning. We demonstrate the effectiveness of Gaussian2Scene across several downstream 3D object detection tasks, showing consistent improvements over existing pre-training methods.
Seasonal Forecasting of Pan-Arctic Sea Ice with State Space Model
May 15, 2025The rapid decline of Arctic sea ice resulting from anthropogenic climate change poses significant risks to indigenous communities, ecosystems, and the global climate system. This situation emphasizes the immediate necessity for precise seasonal sea ice forecasts. While dynamical models perform well for short-term forecasts, they encounter limitations in long-term forecasts and are computationally intensive. Deep learning models, while more computationally efficient, often have difficulty managing seasonal variations and uncertainties when dealing with complex sea ice dynamics. In this research, we introduce IceMamba, a deep learning architecture that integrates sophisticated attention mechanisms within the state space model. Through comparative analysis of 25 renowned forecast models, including dynamical, statistical, and deep learning approaches, our experimental results indicate that IceMamba delivers excellent seasonal forecasting capabilities for Pan-Arctic sea ice concentration. Specifically, IceMamba outperforms all tested models regarding average RMSE and anomaly correlation coefficient (ACC) and ranks second in Integrated Ice Edge Error (IIEE). This innovative approach enhances our ability to foresee and alleviate the effects of sea ice variability, offering essential insights for strategies aimed at climate adaptation.
* This paper is published in npj Climate and Atmospheric Science: https://www.nature.com/articles/s41612-025-01058-0#Sec16 Supplementary information: https://static-content.springer.com/esm/art%3A10.1038%2Fs41612-025-01058-0/MediaObjects/41612_2025_1058_MOESM1_ESM.pdf
MGSR: 2D/3D Mutual-boosted Gaussian Splatting for High-fidelity Surface Reconstruction under Various Light Conditions
Mar 07, 2025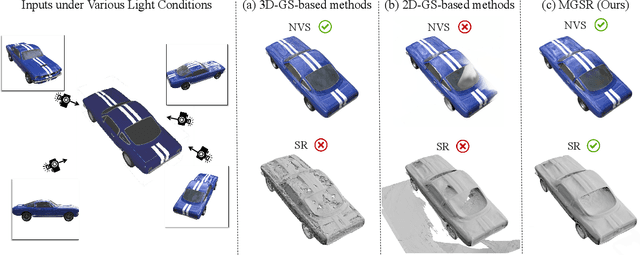
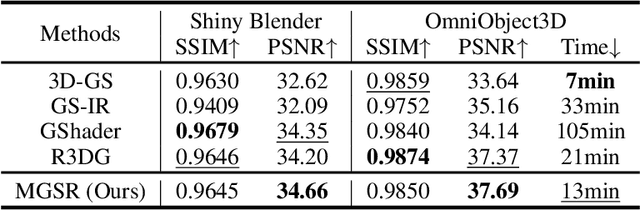
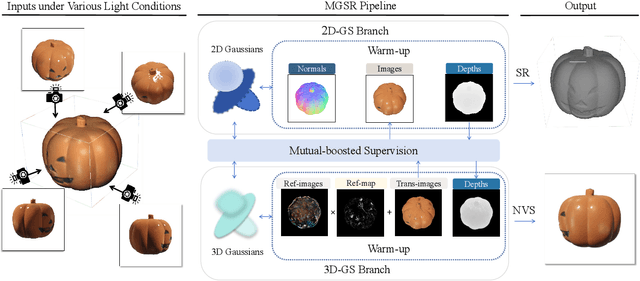

Novel view synthesis (NVS) and surface reconstruction (SR) are essential tasks in 3D Gaussian Splatting (3D-GS). Despite recent progress, these tasks are often addressed independently, with GS-based rendering methods struggling under diverse light conditions and failing to produce accurate surfaces, while GS-based reconstruction methods frequently compromise rendering quality. This raises a central question: must rendering and reconstruction always involve a trade-off? To address this, we propose MGSR, a 2D/3D Mutual-boosted Gaussian splatting for Surface Reconstruction that enhances both rendering quality and 3D reconstruction accuracy. MGSR introduces two branches--one based on 2D-GS and the other on 3D-GS. The 2D-GS branch excels in surface reconstruction, providing precise geometry information to the 3D-GS branch. Leveraging this geometry, the 3D-GS branch employs a geometry-guided illumination decomposition module that captures reflected and transmitted components, enabling realistic rendering under varied light conditions. Using the transmitted component as supervision, the 2D-GS branch also achieves high-fidelity surface reconstruction. Throughout the optimization process, the 2D-GS and 3D-GS branches undergo alternating optimization, providing mutual supervision. Prior to this, each branch completes an independent warm-up phase, with an early stopping strategy implemented to reduce computational costs. We evaluate MGSR on a diverse set of synthetic and real-world datasets, at both object and scene levels, demonstrating strong performance in rendering and surface reconstruction.
Satellite Observations Guided Diffusion Model for Accurate Meteorological States at Arbitrary Resolution
Feb 09, 2025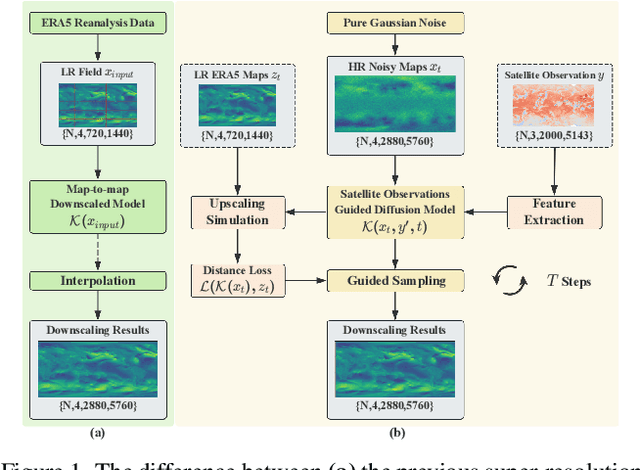
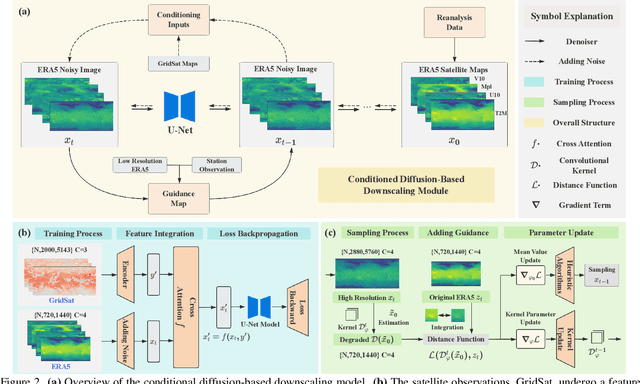
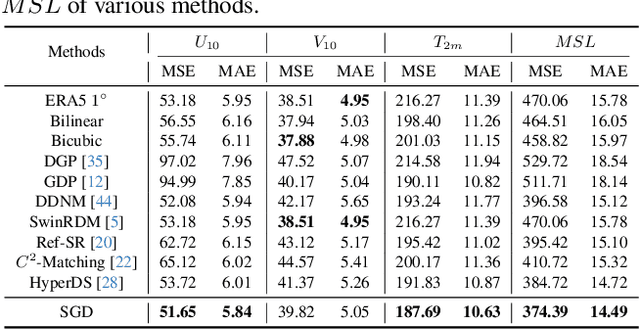
Accurate acquisition of surface meteorological conditions at arbitrary locations holds significant importance for weather forecasting and climate simulation. Due to the fact that meteorological states derived from satellite observations are often provided in the form of low-resolution grid fields, the direct application of spatial interpolation to obtain meteorological states for specific locations often results in significant discrepancies when compared to actual observations. Existing downscaling methods for acquiring meteorological state information at higher resolutions commonly overlook the correlation with satellite observations. To bridge the gap, we propose Satellite-observations Guided Diffusion Model (SGD), a conditional diffusion model pre-trained on ERA5 reanalysis data with satellite observations (GridSat) as conditions, which is employed for sampling downscaled meteorological states through a zero-shot guided sampling strategy and patch-based methods. During the training process, we propose to fuse the information from GridSat satellite observations into ERA5 maps via the attention mechanism, enabling SGD to generate atmospheric states that align more accurately with actual conditions. In the sampling, we employed optimizable convolutional kernels to simulate the upscale process, thereby generating high-resolution ERA5 maps using low-resolution ERA5 maps as well as observations from weather stations as guidance. Moreover, our devised patch-based method promotes SGD to generate meteorological states at arbitrary resolutions. Experiments demonstrate SGD fulfills accurate meteorological states downscaling to 6.25km.
AdaptiveLog: An Adaptive Log Analysis Framework with the Collaboration of Large and Small Language Model
Jan 19, 2025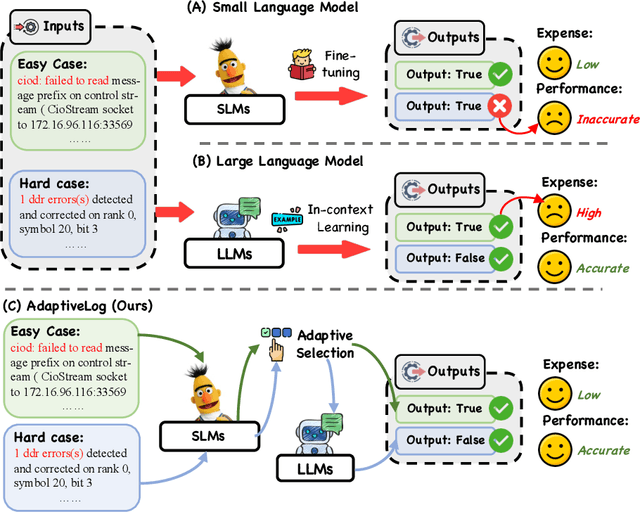

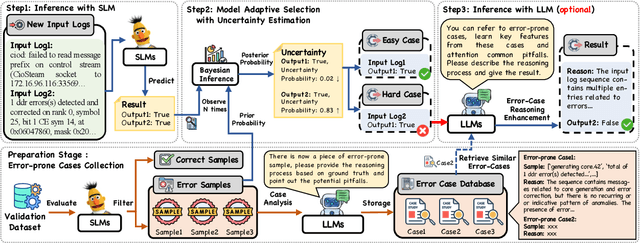

Automated log analysis is crucial to ensure high availability and reliability of complex systems. The advent of LLMs in NLP has ushered in a new era of language model-driven automated log analysis, garnering significant interest. Within this field, two primary paradigms based on language models for log analysis have become prominent. Small Language Models (SLMs) follow the pre-train and fine-tune paradigm, focusing on the specific log analysis task through fine-tuning on supervised datasets. On the other hand, LLMs following the in-context learning paradigm, analyze logs by providing a few examples in prompt contexts without updating parameters. Despite their respective strengths, we notice that SLMs are more cost-effective but less powerful, whereas LLMs with large parameters are highly powerful but expensive and inefficient. To trade-off between the performance and inference costs of both models in automated log analysis, this paper introduces an adaptive log analysis framework known as AdaptiveLog, which effectively reduces the costs associated with LLM while ensuring superior results. This framework collaborates an LLM and a small language model, strategically allocating the LLM to tackle complex logs while delegating simpler logs to the SLM. Specifically, to efficiently query the LLM, we propose an adaptive selection strategy based on the uncertainty estimation of the SLM, where the LLM is invoked only when the SLM is uncertain. In addition, to enhance the reasoning ability of the LLM in log analysis tasks, we propose a novel prompt strategy by retrieving similar error-prone cases as the reference, enabling the model to leverage past error experiences and learn solutions from these cases. Extensive experiments demonstrate that AdaptiveLog achieves state-of-the-art results across different tasks, elevating the overall accuracy of log analysis while maintaining cost efficiency.
Adaptive Prototype Replay for Class Incremental Semantic Segmentation
Dec 17, 2024



Class incremental semantic segmentation (CISS) aims to segment new classes during continual steps while preventing the forgetting of old knowledge. Existing methods alleviate catastrophic forgetting by replaying distributions of previously learned classes using stored prototypes or features. However, they overlook a critical issue: in CISS, the representation of class knowledge is updated continuously through incremental learning, whereas prototype replay methods maintain fixed prototypes. This mismatch between updated representation and fixed prototypes limits the effectiveness of the prototype replay strategy. To address this issue, we propose the Adaptive prototype replay (Adapter) for CISS in this paper. Adapter comprises an adaptive deviation compen sation (ADC) strategy and an uncertainty-aware constraint (UAC) loss. Specifically, the ADC strategy dynamically updates the stored prototypes based on the estimated representation shift distance to match the updated representation of old class. The UAC loss reduces prediction uncertainty, aggregating discriminative features to aid in generating compact prototypes. Additionally, we introduce a compensation-based prototype similarity discriminative (CPD) loss to ensure adequate differentiation between similar prototypes, thereby enhancing the efficiency of the adaptive prototype replay strategy. Extensive experiments on Pascal VOC and ADE20K datasets demonstrate that Adapter achieves state-of-the-art results and proves effective across various CISS tasks, particularly in challenging multi-step scenarios. The code and model is available at https://github.com/zhu-gl-ux/Adapter.
MBPU: A Plug-and-Play State Space Model for Point Cloud Upsamping with Fast Point Rendering
Oct 21, 2024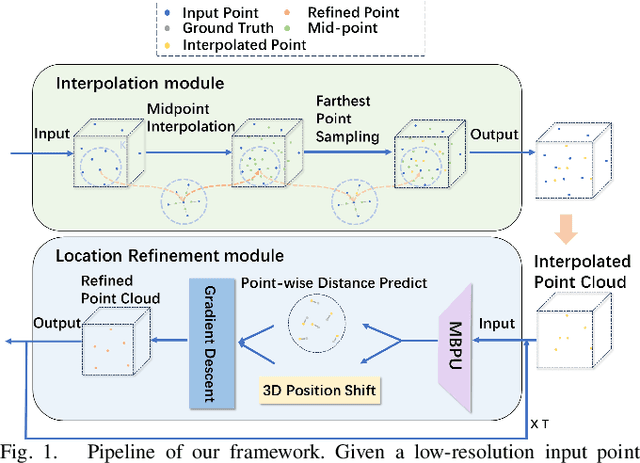
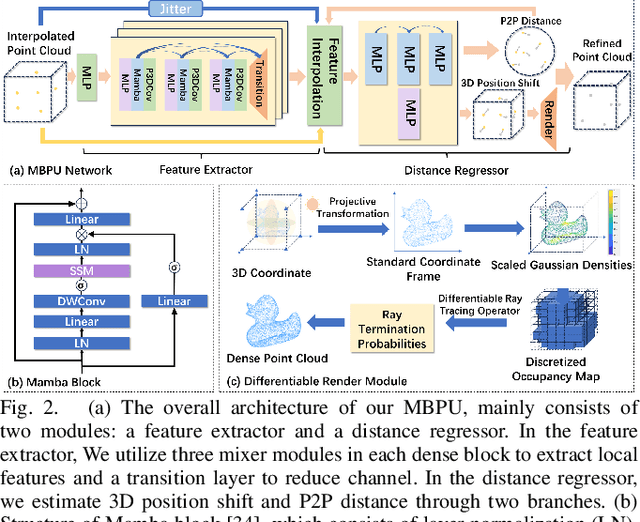
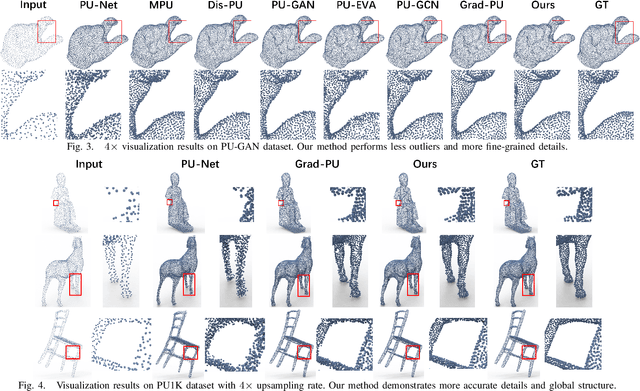
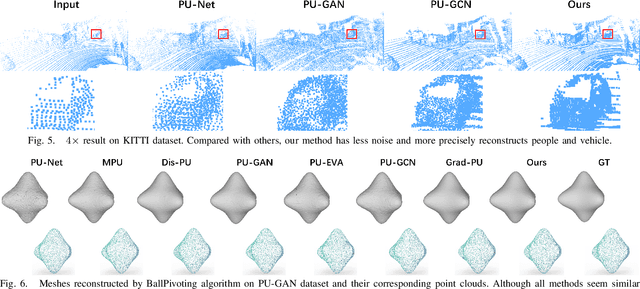
The task of point cloud upsampling (PCU) is to generate dense and uniform point clouds from sparse input captured by 3D sensors like LiDAR, holding potential applications in real yet is still a challenging task. Existing deep learning-based methods have shown significant achievements in this field. However, they still face limitations in effectively handling long sequences and addressing the issue of shrinkage artifacts around the surface of the point cloud. Inspired by the newly proposed Mamba, in this paper, we introduce a network named MBPU built on top of the Mamba architecture, which performs well in long sequence modeling, especially for large-scale point cloud upsampling, and achieves fast convergence speed. Moreover, MBPU is an arbitrary-scale upsampling framework as the predictor of point distance in the point refinement phase. At the same time, we simultaneously predict the 3D position shift and 1D point-to-point distance as regression quantities to constrain the global features while ensuring the accuracy of local details. We also introduce a fast differentiable renderer to further enhance the fidelity of the upsampled point cloud and reduce artifacts. It is noted that, by the merits of our fast point rendering, MBPU yields high-quality upsampled point clouds by effectively eliminating surface noise. Extensive experiments have demonstrated that our MBPU outperforms other off-the-shelf methods in terms of point cloud upsampling, especially for large-scale point clouds.