 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-GS: Gaussian Splatting with Spatial-aware Denoising
May 14, 2026Recent advances in 3D Gaussian Splatting (3DGS) have achieved remarkable success in high-fidelity Novel View Synthesis (NVS), yet the optimization process inevitably introduces noisy Gaussian primitives due to the sparse and incomplete initialization from Structure-from-Motion (SfM) point clouds. Most existing methods focus solely on adjusting the positions of primitives during optimization, while neglecting the underlying spatial structure. To this end, we introduce a new perspective by formulating the optimization of 3DGS as a primitive denoising process and propose Denoising-GS, a spatial-aware denoising framework for Gaussian primitives by taking both the positions and spatial structure into consideration. Specifically, we design an optimizer that preserves the spatial optimization flow of primitives, facilitating coherent and directed denoising rather than random perturbations. Building upon this, the Spatial Gradient-based Denoising strategy jointly considers the spatial supports of primitives to ensure gradient-consistent updates. Furthermore, the Uncertainty-based Denoising module estimates primitive-wise uncertainty to prune redundant or noisy primitives, while the Spatial Coherence Refinement strategy selectively splits primitives in sparse regions to maintain structural completeness. Experiments conducted on three benchmark datasets demonstrate that Denoising-GS consistently enhances NVS fidelity while maintaining representation compactness, achieving state-of-the-art performance across all benchmarks. Source code and models will be made publicly available.
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Jul 08, 2025Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
MGSR: 2D/3D Mutual-boosted Gaussian Splatting for High-fidelity Surface Reconstruction under Various Light Conditions
Mar 07, 2025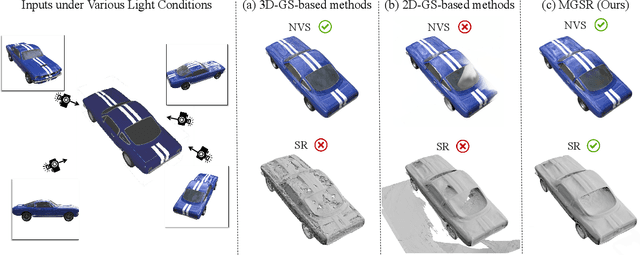
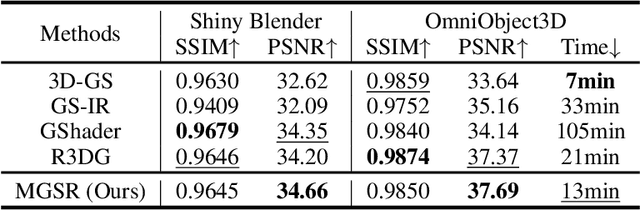
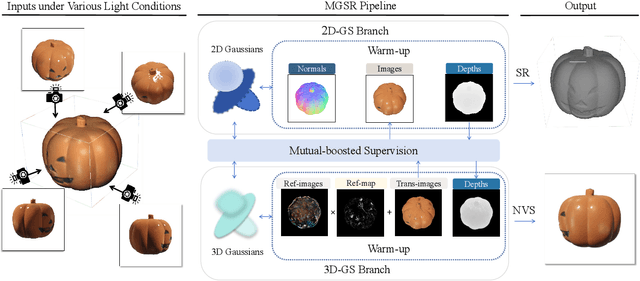

Novel view synthesis (NVS) and surface reconstruction (SR) are essential tasks in 3D Gaussian Splatting (3D-GS). Despite recent progress, these tasks are often addressed independently, with GS-based rendering methods struggling under diverse light conditions and failing to produce accurate surfaces, while GS-based reconstruction methods frequently compromise rendering quality. This raises a central question: must rendering and reconstruction always involve a trade-off? To address this, we propose MGSR, a 2D/3D Mutual-boosted Gaussian splatting for Surface Reconstruction that enhances both rendering quality and 3D reconstruction accuracy. MGSR introduces two branches--one based on 2D-GS and the other on 3D-GS. The 2D-GS branch excels in surface reconstruction, providing precise geometry information to the 3D-GS branch. Leveraging this geometry, the 3D-GS branch employs a geometry-guided illumination decomposition module that captures reflected and transmitted components, enabling realistic rendering under varied light conditions. Using the transmitted component as supervision, the 2D-GS branch also achieves high-fidelity surface reconstruction. Throughout the optimization process, the 2D-GS and 3D-GS branches undergo alternating optimization, providing mutual supervision. Prior to this, each branch completes an independent warm-up phase, with an early stopping strategy implemented to reduce computational costs. We evaluate MGSR on a diverse set of synthetic and real-world datasets, at both object and scene levels, demonstrating strong performance in rendering and surface reconstruction.
RefGaussian: Disentangling Reflections from 3D Gaussian Splatting for Realistic Rendering
Jun 09, 2024



3D Gaussian Splatting (3D-GS) has made a notable advancement in the field of neural rendering, 3D scene reconstruction, and novel view synthesis. Nevertheless, 3D-GS encounters the main challenge when it comes to accurately representing physical reflections, especially in the case of total reflection and semi-reflection that are commonly found in real-world scenes. This limitation causes reflections to be mistakenly treated as independent elements with physical presence, leading to imprecise reconstructions. Herein, to tackle this challenge, we propose RefGaussian to disentangle reflections from 3D-GS for realistically modeling reflections. Specifically, we propose to split a scene into transmitted and reflected components and represent these components using two Spherical Harmonics (SH). Given that this decomposition is not fully determined, we employ local regularization techniques to ensure local smoothness for both the transmitted and reflected components, thereby achieving more plausible decomposition outcomes than 3D-GS. Experimental results demonstrate that our approach achieves superior novel view synthesis and accurate depth estimation outcomes. Furthermore, it enables the utilization of scene editing applications, ensuring both high-quality results and physical coherence.
Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
Mar 15, 2024



Unsupervised domain adaptation (UDA) is vital for alleviating the workload of labeling 3D point cloud data and mitigating the absence of labels when facing a newly defined domain. Various methods of utilizing images to enhance the performance of cross-domain 3D segmentation have recently emerged. However, the pseudo labels, which are generated from models trained on the source domain and provide additional supervised signals for the unseen domain, are inadequate when utilized for 3D segmentation due to their inherent noisiness and consequently restrict the accuracy of neural networks. With the advent of 2D visual foundation models (VFMs) and their abundant knowledge prior, we propose a novel pipeline VFMSeg to further enhance the cross-modal unsupervised domain adaptation framework by leveraging these models. In this work, we study how to harness the knowledge priors learned by VFMs to produce more accurate labels for unlabeled target domains and improve overall performance. We first utilize a multi-modal VFM, which is pre-trained on large scale image-text pairs, to provide supervised labels (VFM-PL) for images and point clouds from the target domain. Then, another VFM trained on fine-grained 2D masks is adopted to guide the generation of semantically augmented images and point clouds to enhance the performance of neural networks, which mix the data from source and target domains like view frustums (FrustumMixing). Finally, we merge class-wise prediction across modalities to produce more accurate annotations for unlabeled target domains. Our method is evaluated on various autonomous driving datasets and the results demonstrate a significant improvement for 3D segmentation task.
3D Gaussian as a New Vision Era: A Survey
Feb 11, 2024



3D Gaussian Splatting (3D-GS) has emerged as a significant advancement in the field of Computer Graphics, offering explicit scene representation and novel view synthesis without the reliance on neural networks, such as Neural Radiance Fields (NeRF). This technique has found diverse applications in areas such as robotics, urban mapping, autonomous navigation, and virtual reality/augmented reality, just name a few. Given the growing popularity and expanding research in 3D Gaussian Splatting, this paper presents a comprehensive survey of relevant papers from the past year. We organize the survey into taxonomies based on characteristics and applications, providing an introduction to the theoretical underpinnings of 3D Gaussian Splatting. Our goal through this survey is to acquaint new researchers with 3D Gaussian Splatting, serve as a valuable reference for seminal works in the field, and inspire future research directions, as discussed in our concluding section.