 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSwim: Revisiting Sliding-Window Attention Mechanisms for Training-Free Ultra-High-Resolution Video Generation
Nov 18, 2025The quadratic time and memory complexity of the attention mechanism in modern Transformer based video generators makes end-to-end training for ultra high resolution videos prohibitively expensive. Motivated by this limitation, we introduce a training-free approach that leverages video Diffusion Transformers pretrained at their native scale to synthesize higher resolution videos without any additional training or adaptation. At the core of our method lies an inward sliding window attention mechanism, which originates from a key observation: maintaining each query token's training scale receptive field is crucial for preserving visual fidelity and detail. However, naive local window attention, unfortunately, often leads to repetitive content and exhibits a lack of global coherence in the generated results. To overcome this challenge, we devise a dual-path pipeline that backs up window attention with a novel cross-attention override strategy, enabling the semantic content produced by local attention to be guided by another branch with a full receptive field and, therefore, ensuring holistic consistency. Furthermore, to improve efficiency, we incorporate a cross-attention caching strategy for this branch to avoid the frequent computation of full 3D attention. Extensive experiments demonstrate that our method delivers ultra-high-resolution videos with fine-grained visual details and high efficiency in a training-free paradigm. Meanwhile, it achieves superior performance on VBench, even compared to training-based alternatives, with competitive or improved efficiency. Codes are available at: https://github.com/WillWu111/FreeSwim
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025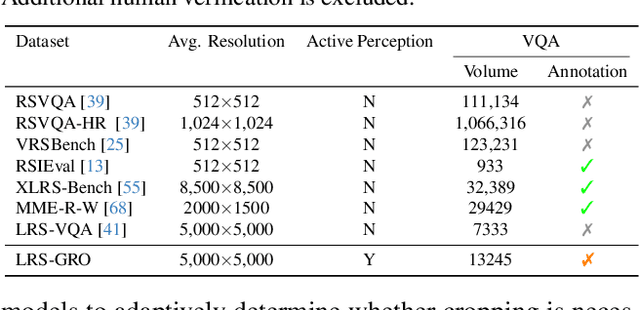
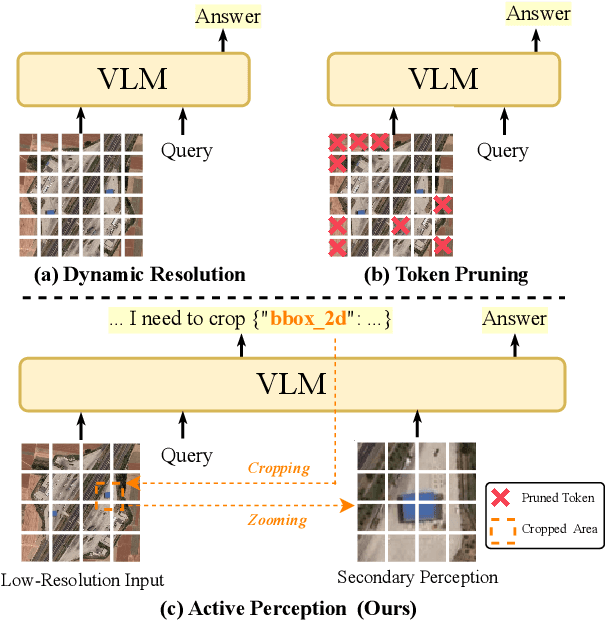
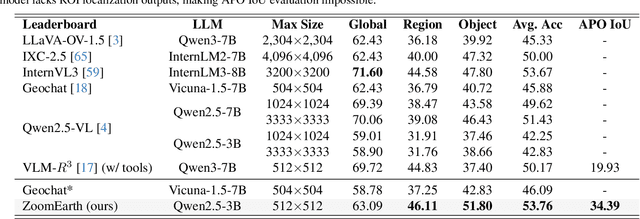
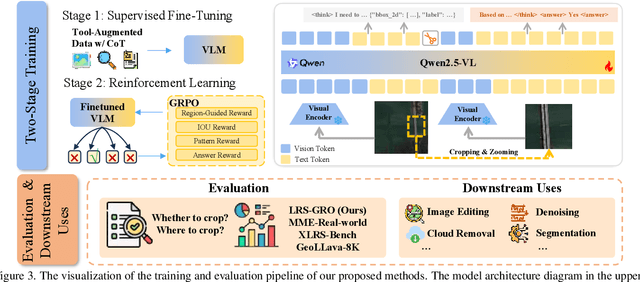
Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Jul 08, 2025Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
RS-MTDF: Multi-Teacher Distillation and Fusion for Remote Sensing Semi-Supervised Semantic Segmentation
Jun 11, 2025Semantic segmentation in remote sensing images is crucial for various applications, yet its performance is heavily reliant on large-scale, high-quality pixel-wise annotations, which are notoriously expensive and time-consuming to acquire. Semi-supervised semantic segmentation (SSS) offers a promising alternative to mitigate this data dependency. However, existing SSS methods often struggle with the inherent distribution mismatch between limited labeled data and abundant unlabeled data, leading to suboptimal generalization. To alleviate this issue, we attempt to introduce the Vision Foundation Models (VFMs) pre-trained on vast and diverse datasets into the SSS task since VFMs possess robust generalization capabilities that can effectively bridge this distribution gap and provide strong semantic priors for SSS. Inspired by this, we introduce RS-MTDF (Multi-Teacher Distillation and Fusion), a novel framework that leverages the powerful semantic knowledge embedded in VFMs to guide semi-supervised learning in remote sensing. Specifically, RS-MTDF employs multiple frozen VFMs (e.g., DINOv2 and CLIP) as expert teachers, utilizing feature-level distillation to align student features with their robust representations. To further enhance discriminative power, the distilled knowledge is seamlessly fused into the student decoder. Extensive experiments on three challenging remote sensing datasets demonstrate that RS-MTDF consistently achieves state-of-the-art performance. Notably, our method outperforms existing approaches across various label ratios on LoveDA and secures the highest IoU in the majority of semantic categories. These results underscore the efficacy of multi-teacher VFM guidance in significantly enhancing both generalization and semantic understanding for remote sensing segmentation. Ablation studies further validate the contribution of each proposed module.
Hallucination at a Glance: Controlled Visual Edits and Fine-Grained Multimodal Learning
Jun 08, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks but still struggle with fine-grained visual differences, leading to hallucinations or missed semantic shifts. We attribute this to limitations in both training data and learning objectives. To address these issues, we propose a controlled data generation pipeline that produces minimally edited image pairs with semantically aligned captions. Using this pipeline, we construct the Micro Edit Dataset (MED), containing over 50K image-text pairs spanning 11 fine-grained edit categories, including attribute, count, position, and object presence changes. Building on MED, we introduce a supervised fine-tuning (SFT) framework with a feature-level consistency loss that promotes stable visual embeddings under small edits. We evaluate our approach on the Micro Edit Detection benchmark, which includes carefully balanced evaluation pairs designed to test sensitivity to subtle visual variations across the same edit categories. Our method improves difference detection accuracy and reduces hallucinations compared to strong baselines, including GPT-4o. Moreover, it yields consistent gains on standard vision-language tasks such as image captioning and visual question answering. These results demonstrate the effectiveness of combining targeted data and alignment objectives for enhancing fine-grained visual reasoning in MLLMs.
MV-CC: Mask Enhanced Video Model for Remote Sensing Change Caption
Oct 31, 2024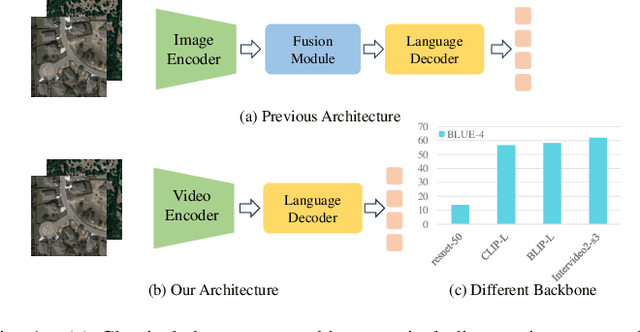

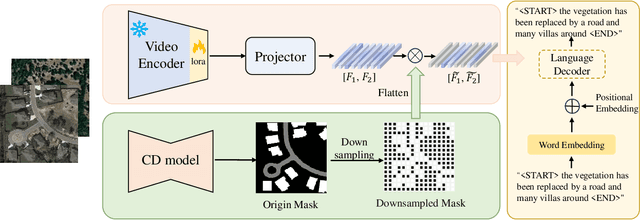
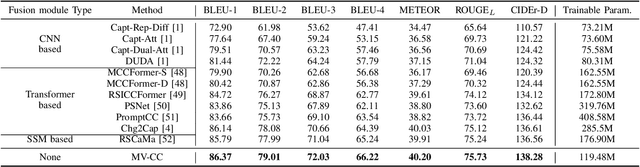
Remote sensing image change caption (RSICC) aims to provide natural language descriptions for bi-temporal remote sensing images. Since Change Caption (CC) task requires both spatial and temporal features, previous works follow an encoder-fusion-decoder architecture. They use an image encoder to extract spatial features and the fusion module to integrate spatial features and extract temporal features, which leads to increasingly complex manual design of the fusion module. In this paper, we introduce a novel video model-based paradigm without design of the fusion module and propose a Mask-enhanced Video model for Change Caption (MV-CC). Specifically, we use the off-the-shelf video encoder to simultaneously extract the temporal and spatial features of bi-temporal images. Furthermore, the types of changes in the CC are set based on specific task requirements, and to enable the model to better focus on the regions of interest, we employ masks obtained from the Change Detection (CD) method to explicitly guide the CC model. Experimental results demonstrate that our proposed method can obtain better performance compared with other state-of-the-art RSICC methods. The code is available at https://github.com/liuruixun/MV-CC.
MBPU: A Plug-and-Play State Space Model for Point Cloud Upsamping with Fast Point Rendering
Oct 21, 2024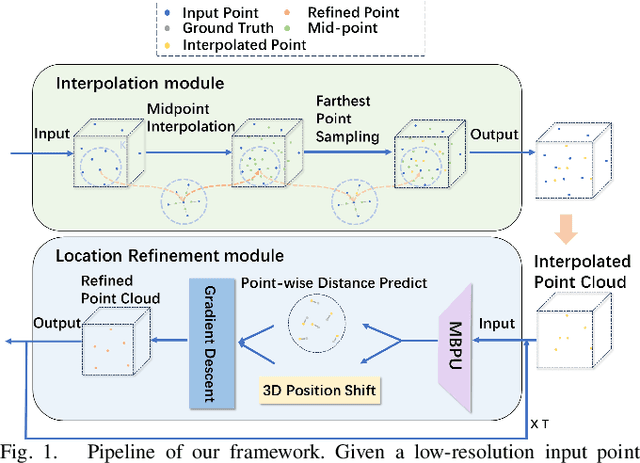
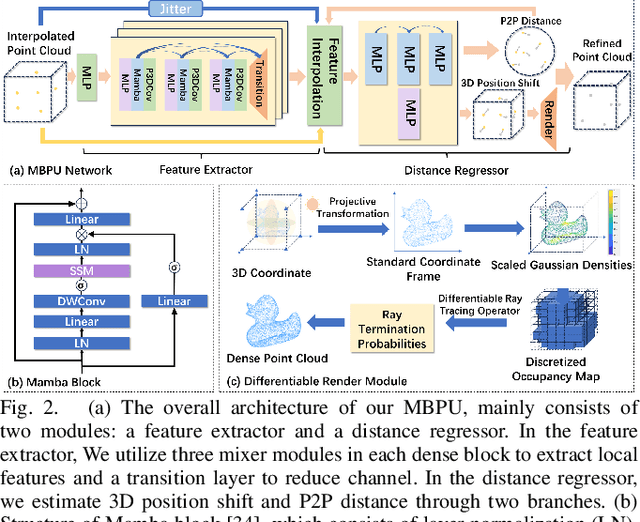
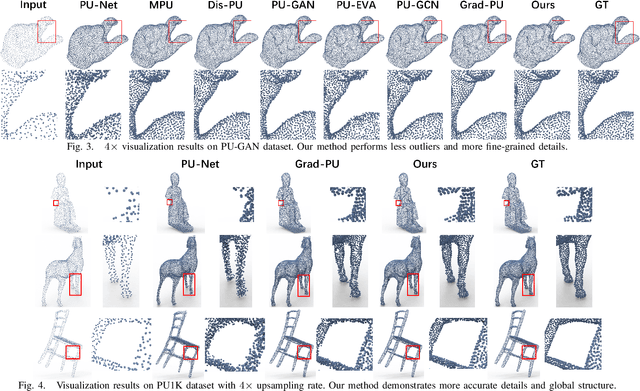
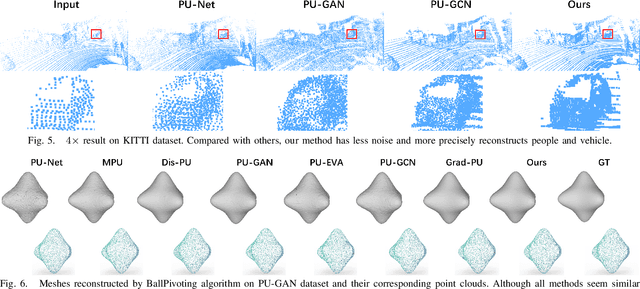
The task of point cloud upsampling (PCU) is to generate dense and uniform point clouds from sparse input captured by 3D sensors like LiDAR, holding potential applications in real yet is still a challenging task. Existing deep learning-based methods have shown significant achievements in this field. However, they still face limitations in effectively handling long sequences and addressing the issue of shrinkage artifacts around the surface of the point cloud. Inspired by the newly proposed Mamba, in this paper, we introduce a network named MBPU built on top of the Mamba architecture, which performs well in long sequence modeling, especially for large-scale point cloud upsampling, and achieves fast convergence speed. Moreover, MBPU is an arbitrary-scale upsampling framework as the predictor of point distance in the point refinement phase. At the same time, we simultaneously predict the 3D position shift and 1D point-to-point distance as regression quantities to constrain the global features while ensuring the accuracy of local details. We also introduce a fast differentiable renderer to further enhance the fidelity of the upsampled point cloud and reduce artifacts. It is noted that, by the merits of our fast point rendering, MBPU yields high-quality upsampled point clouds by effectively eliminating surface noise. Extensive experiments have demonstrated that our MBPU outperforms other off-the-shelf methods in terms of point cloud upsampling, especially for large-scale point clouds.